Superposition Prompting: Improving and Accelerating Retrieval-Augmented Generation
2404.06910
0
0
Abstract
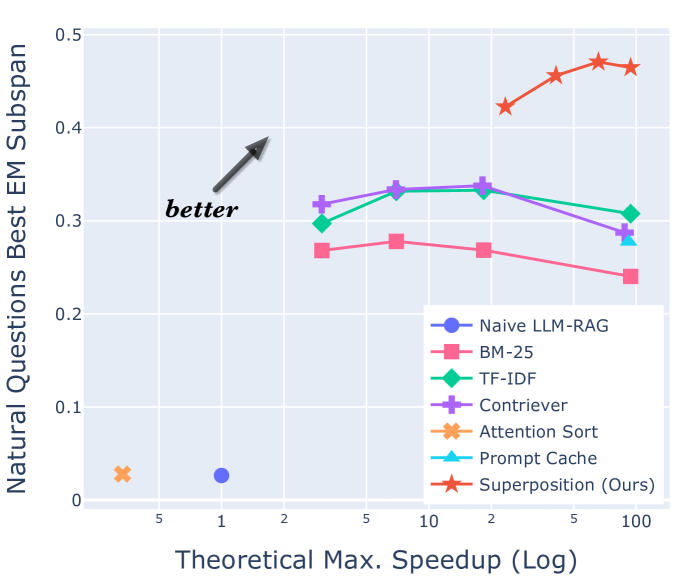
Despite the successes of large language models (LLMs), they exhibit significant drawbacks, particularly when processing long contexts. Their inference cost scales quadratically with respect to sequence length, making it expensive for deployment in some real-world text processing applications, such as retrieval-augmented generation (RAG). Additionally, LLMs also exhibit the distraction phenomenon, where irrelevant context in the prompt degrades output quality. To address these drawbacks, we propose a novel RAG prompting methodology, superposition prompting, which can be directly applied to pre-trained transformer-based LLMs without the need for fine-tuning. At a high level, superposition prompting allows the LLM to process input documents in parallel prompt paths, discarding paths once they are deemed irrelevant. We demonstrate the capability of our method to simultaneously enhance time efficiency across a variety of question-answering benchmarks using multiple pre-trained LLMs. Furthermore, our technique significantly improves accuracy when the retrieved context is large relative the context the model was trained on. For example, our approach facilitates an 93x reduction in compute time while improving accuracy by 43% on the NaturalQuestions-Open dataset with the MPT-7B instruction-tuned model over naive RAG.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces "Superposition Prompting", a novel approach to improving and accelerating retrieval-augmented generation using large language models (LLMs).
- The key ideas are to leverage the power of LLMs for efficient in-context learning and to combine retrieval with a "superposition" technique to enhance the quality and speed of the generation process.
- The authors demonstrate the effectiveness of their approach on a range of tasks, including question answering and text summarization, showing significant improvements over existing retrieval-augmented methods.
Plain English Explanation
Retrieval-augmented generation is a powerful technique that combines the knowledge stored in large language models with the ability to quickly retrieve relevant information from a database. This can be particularly helpful for tasks like question answering, where the model needs to draw from a broader knowledge base to provide accurate and informative responses.
The researchers in this paper have developed a new approach called "Superposition Prompting" that builds on this idea. The core insight is that by carefully combining the information retrieved from the database with the language model's own knowledge, you can improve the quality and speed of the generation process.
The Adapting LLMs for Efficient Context Processing Through Soft Retrieval and ConFLARE: Conformal Large Language Model Retrieval papers provide helpful background on the challenges and opportunities in this area.
The key steps in Superposition Prompting are:
- Retrieve relevant information from a database using the input prompt
- Carefully combine this retrieved information with the language model's own knowledge through a "superposition" technique
- Use this enhanced context to generate a more accurate and informative response
By leveraging the strengths of both the language model and the retrieval system, the authors show that Superposition Prompting can lead to significant improvements in performance across a variety of tasks, compared to existing retrieval-augmented methods.
Technical Explanation
The core idea behind Superposition Prompting is to seamlessly integrate the information retrieved from a database with the language model's own knowledge during the generation process. This is done through a novel "superposition" technique that combines the retrieved context with the language model's internal representations in a principled way.
Specifically, the authors propose to use a soft-retrieval mechanism to obtain a set of relevant documents from a database based on the input prompt. These retrieved documents are then encoded and combined with the language model's hidden states using a weighted sum. This "superposed" representation is then used to condition the language model's generation, allowing it to draw from both the retrieved information and its own learned knowledge.
The authors evaluate their approach on a range of tasks, including question answering and text summarization, and show significant improvements over existing retrieval-augmented methods. For example, on the popular QuAC question answering benchmark, Superposition Prompting achieved a 5-point increase in F1 score compared to a strong baseline.
The authors also provide detailed analyses to understand the mechanisms behind these performance gains. They find that the superposition technique helps the language model better ground its generation in the relevant context, leading to more accurate and informative outputs. Additionally, the retrieval process can be accelerated by only retrieving a small number of documents, without sacrificing much performance.
Overall, this work represents an important advancement in the field of retrieval-augmented generation, demonstrating how the synergistic combination of language models and retrieval systems can be leveraged to create more powerful and efficient AI systems. The Towards Robust Retrieval-Based Summarization System, Modeling Uncertainty Using Post-Fusion as Fallback, and Not All Contexts Are Equal: Teaching LLMs papers provide additional context and perspectives on related challenges and approaches in this area.
Critical Analysis
The Superposition Prompting approach presented in this paper represents a significant step forward in the field of retrieval-augmented generation. The authors have demonstrated the effectiveness of their technique across a range of tasks, showcasing impressive performance improvements over existing methods.
One notable strength of the approach is its ability to efficiently leverage the retrieved context, without the need for expensive joint encoding of the prompt and retrieved documents. By using a "superposition" technique to combine the representations, the model can maintain high performance while reducing the computational overhead of the retrieval process.
However, the paper does acknowledge some potential limitations and areas for further research. For instance, the authors note that the performance gains may be task-dependent, and further investigation is needed to understand the optimal retrieval strategies for different types of problems. Additionally, the paper does not explore the impact of the size and quality of the underlying database on the system's performance, which could be an important factor in real-world applications.
Another area that could benefit from further exploration is the interpretability and explainability of the Superposition Prompting approach. While the authors provide some insights into the mechanisms behind the performance gains, a deeper understanding of how the model is leveraging the retrieved information could be valuable for building trust and transparency in these systems.
Overall, the Superposition Prompting technique represents an exciting advancement in the field of retrieval-augmented generation, and the authors have laid the groundwork for further research and development in this area. By continuing to explore the capabilities and limitations of this approach, researchers may be able to unlock even more powerful and versatile AI systems that can seamlessly combine language understanding, knowledge retrieval, and generation.
Conclusion
The Superposition Prompting approach introduced in this paper offers a novel and effective way to improve and accelerate retrieval-augmented generation using large language models. By carefully combining the retrieved context with the model's own internal representations, the authors demonstrate significant performance gains on a range of tasks, including question answering and text summarization.
This work represents an important step forward in the field of AI, showcasing how the synergistic integration of language models and retrieval systems can lead to more powerful and efficient AI systems. The authors' insights on the mechanisms behind the performance improvements, as well as the potential limitations and areas for future research, provide a solid foundation for further advancements in this area.
As the field of AI continues to evolve, techniques like Superposition Prompting will undoubtedly play a crucial role in unlocking the full potential of large language models and enabling them to tackle increasingly complex real-world problems. This paper serves as a valuable contribution to the ongoing efforts to push the boundaries of what is possible in the realm of AI-powered language understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Introducing Super RAGs in Mistral 8x7B-v1
Ayush Thakur, Raghav Gupta
0
0
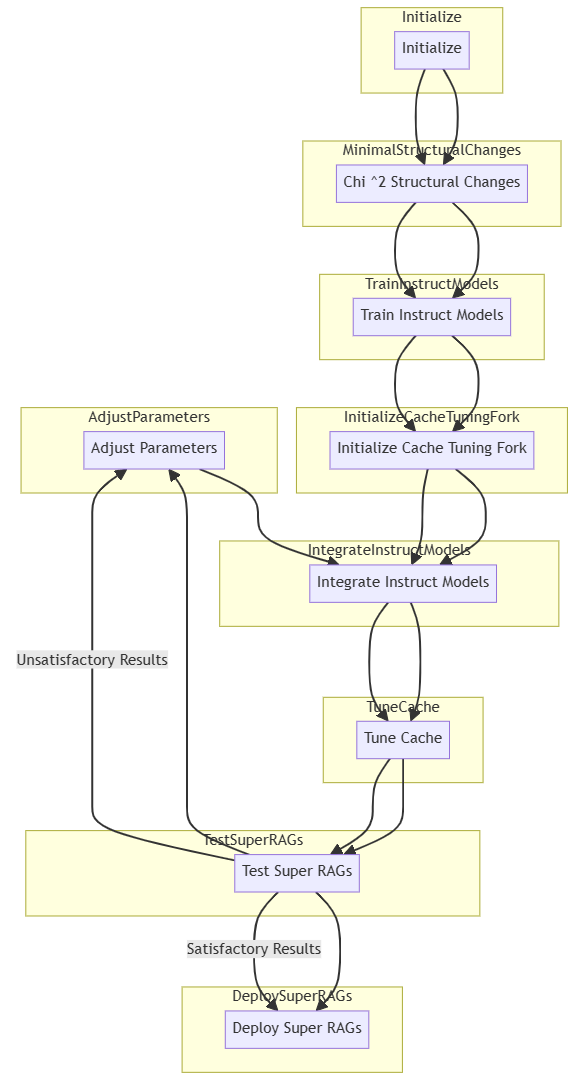
The relentless pursuit of enhancing Large Language Models (LLMs) has led to the advent of Super Retrieval-Augmented Generation (Super RAGs), a novel approach designed to elevate the performance of LLMs by integrating external knowledge sources with minimal structural modifications. This paper presents the integration of Super RAGs into the Mistral 8x7B v1, a state-of-the-art LLM, and examines the resultant improvements in accuracy, speed, and user satisfaction. Our methodology uses a fine-tuned instruct model setup and a cache tuning fork system, ensuring efficient and relevant data retrieval. The evaluation, conducted over several epochs, demonstrates significant enhancements across all metrics. The findings suggest that Super RAGs can effectively augment LLMs, paving the way for more sophisticated and reliable AI systems. This research contributes to the field by providing empirical evidence of the benefits of Super RAGs and offering insights into their potential applications.
4/16/2024
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Katherine Jijo, Eden Chung, Natan Vidra
0
0
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
4/12/2024
The Power of Noise: Redefining Retrieval for RAG Systems
Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, Fabrizio Silvestri
0
0
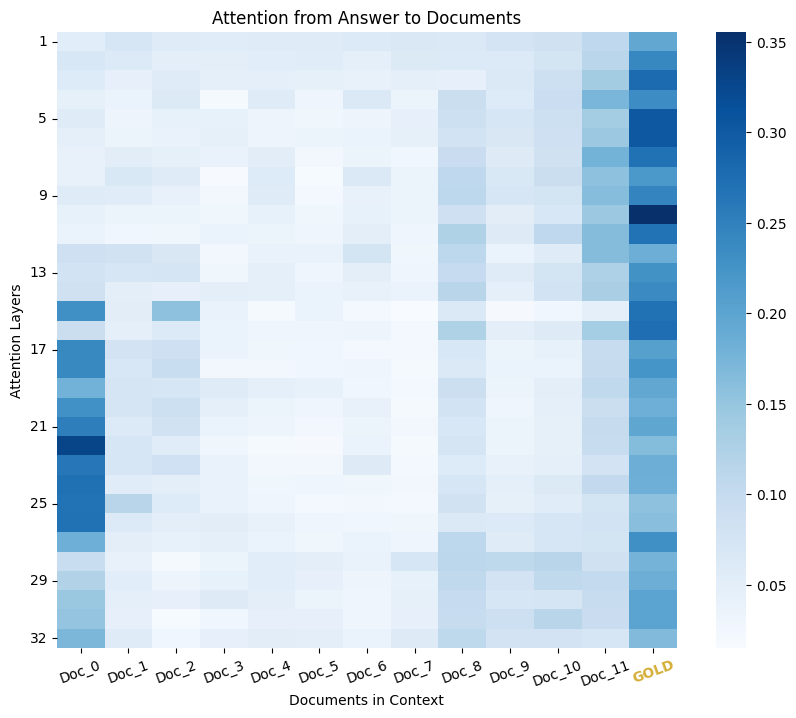
Retrieval-Augmented Generation (RAG) has recently emerged as a method to extend beyond the pre-trained knowledge of Large Language Models by augmenting the original prompt with relevant passages or documents retrieved by an Information Retrieval (IR) system. RAG has become increasingly important for Generative AI solutions, especially in enterprise settings or in any domain in which knowledge is constantly refreshed and cannot be memorized in the LLM. We argue here that the retrieval component of RAG systems, be it dense or sparse, deserves increased attention from the research community, and accordingly, we conduct the first comprehensive and systematic examination of the retrieval strategy of RAG systems. We focus, in particular, on the type of passages IR systems within a RAG solution should retrieve. Our analysis considers multiple factors, such as the relevance of the passages included in the prompt context, their position, and their number. One counter-intuitive finding of this work is that the retriever's highest-scoring documents that are not directly relevant to the query (e.g., do not contain the answer) negatively impact the effectiveness of the LLM. Even more surprising, we discovered that adding random documents in the prompt improves the LLM accuracy by up to 35%. These results highlight the need to investigate the appropriate strategies when integrating retrieval with LLMs, thereby laying the groundwork for future research in this area.
5/2/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Yujuan Ding, Wenqi Fan, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) techniques can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-generated content (AIGC), the powerful capacity of retrieval in RAG in providing additional knowledge enables retrieval-augmented generation to assist existing generative AI in producing high-quality outputs. Recently, large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, retrieval-augmented large language models have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in retrieval-augmented large language models (RA-LLMs), covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we categorize mainstream relevant work by application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research.
5/13/2024