Prompt, Plan, Perform: LLM-based Humanoid Control via Quantized Imitation Learning

0
🔍
Sign in to get full access
Overview
- Reinforcement learning and imitation learning have shown promise for controlling humanoid robot motion.
- However, these methods often require specific simulation environments and rewards, resulting in limited capabilities for complex and unknown tasks.
- This paper presents a novel approach that combines adversarial imitation learning with large language models (LLMs) to enable a single policy that can learn reusable skills and solve zero-shot tasks.
Plain English Explanation
The paper describes a new way to control the motion of humanoid robots, which are robots designed to move and act like humans. Traditionally, researchers have used reinforcement learning and imitation learning to teach robots how to move, but these methods often require creating custom simulations and reward systems for specific tasks. This can limit the robots' abilities to handle complex or unknown situations.
The researchers in this paper have developed a different approach that combines adversarial imitation learning with large language models (LLMs). LLMs are powerful AI systems that can understand and generate human language.
The key idea is to use the LLM as a "strategic planner" to guide the robot's actions. The robot learns a single, versatile policy that can apply its skills to new tasks, based on the LLM's understanding of the task requirements. This allows the robot to tackle complex, unknown tasks without needing to train separate policies for each one.
To further improve the system, the researchers incorporate techniques like vector quantization to help the robot generate appropriate actions in response to the LLM's instructions. They also design general reward functions that focus on the unique motion features of humanoid robots, rather than relying on additional guidance or policies.
Technical Explanation
The researchers propose a framework that combines adversarial imitation learning with large language models (LLMs) to enable a single policy network that can learn reusable skills and solve zero-shot tasks for humanoid robots.
The key components of their approach are:
-
LLM as a Strategic Planner: The LLM is used to comprehend task-specific prompts and provide guidance to the agent, enabling it to apply previously learned skills to novel tasks in a sequence.
-
Codebook-based Vector Quantization: This technique allows the agent to generate suitable actions in response to unseen textual commands from the LLM, improving the system's ability to follow instructions.
-
General Reward Functions: The researchers design reward functions that consider the distinct motion features of humanoid robots, ensuring the agent imitates the motion data while maintaining goal orientation without additional guiding direction approaches or policies.
The researchers evaluate their method through extensive experiments, demonstrating its efficient and adaptive abilities in complicated motion tasks for humanoid robots.
Critical Analysis
The researchers address an important challenge in the field of humanoid robot control by proposing a novel approach that overcomes the limitations of traditional reinforcement learning and imitation learning methods. The use of LLMs as strategic planners is a particularly interesting and promising concept, as it allows the agent to apply its learned skills to a wider range of tasks without the need for custom simulation environments and reward systems.
However, the paper does not provide a detailed analysis of the potential limitations or drawbacks of this approach. For example, it would be valuable to understand the computational and memory requirements of the system, as well as the performance on tasks that may require more complex reasoning or long-term planning beyond the capabilities of current LLMs.
Additionally, the paper could benefit from a more thorough discussion of the ethical implications and potential societal impacts of this technology, especially as it relates to the deployment of humanoid robots in real-world environments.
Conclusion
This paper presents a novel approach that combines adversarial imitation learning with large language models to enable a single policy network that can learn reusable skills and solve zero-shot tasks for humanoid robots. The use of LLMs as strategic planners and the incorporation of techniques like vector quantization demonstrate the potential for this framework to enhance the capabilities of humanoid robots in complex and unknown environments. While the paper raises interesting technical and conceptual advancements, further research is needed to fully understand the limitations and societal implications of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Prompt, Plan, Perform: LLM-based Humanoid Control via Quantized Imitation Learning
Jingkai Sun, Qiang Zhang, Yiqun Duan, Xiaoyang Jiang, Chong Cheng, Renjing Xu
In recent years, reinforcement learning and imitation learning have shown great potential for controlling humanoid robots' motion. However, these methods typically create simulation environments and rewards for specific tasks, resulting in the requirements of multiple policies and limited capabilities for tackling complex and unknown tasks. To overcome these issues, we present a novel approach that combines adversarial imitation learning with large language models (LLMs). This innovative method enables the agent to learn reusable skills with a single policy and solve zero-shot tasks under the guidance of LLMs. In particular, we utilize the LLM as a strategic planner for applying previously learned skills to novel tasks through the comprehension of task-specific prompts. This empowers the robot to perform the specified actions in a sequence. To improve our model, we incorporate codebook-based vector quantization, allowing the agent to generate suitable actions in response to unseen textual commands from LLMs. Furthermore, we design general reward functions that consider the distinct motion features of humanoid robots, ensuring the agent imitates the motion data while maintaining goal orientation without additional guiding direction approaches or policies. To the best of our knowledge, this is the first framework that controls humanoid robots using a single learning policy network and LLM as a planner. Extensive experiments demonstrate that our method exhibits efficient and adaptive ability in complicated motion tasks.
Read more8/1/2024
🏅
0
I-CTRL: Imitation to Control Humanoid Robots Through Constrained Reinforcement Learning
Yashuai Yan, Esteve Valls Mascaro, Tobias Egle, Dongheui Lee
This paper addresses the critical need for refining robot motions that, despite achieving a high visual similarity through human-to-humanoid retargeting methods, fall short of practical execution in the physical realm. Existing techniques in the graphics community often prioritize visual fidelity over physics-based feasibility, posing a significant challenge for deploying bipedal systems in practical applications. Our research introduces a constrained reinforcement learning algorithm to produce physics-based high-quality motion imitation onto legged humanoid robots that enhance motion resemblance while successfully following the reference human trajectory. We name our framework: I-CTRL. By reformulating the motion imitation problem as a constrained refinement over non-physics-based retargeted motions, our framework excels in motion imitation with simple and unique rewards that generalize across four robots. Moreover, our framework can follow large-scale motion datasets with a unique RL agent. The proposed approach signifies a crucial step forward in advancing the control of bipedal robots, emphasizing the importance of aligning visual and physical realism for successful motion imitation.
Read more5/15/2024
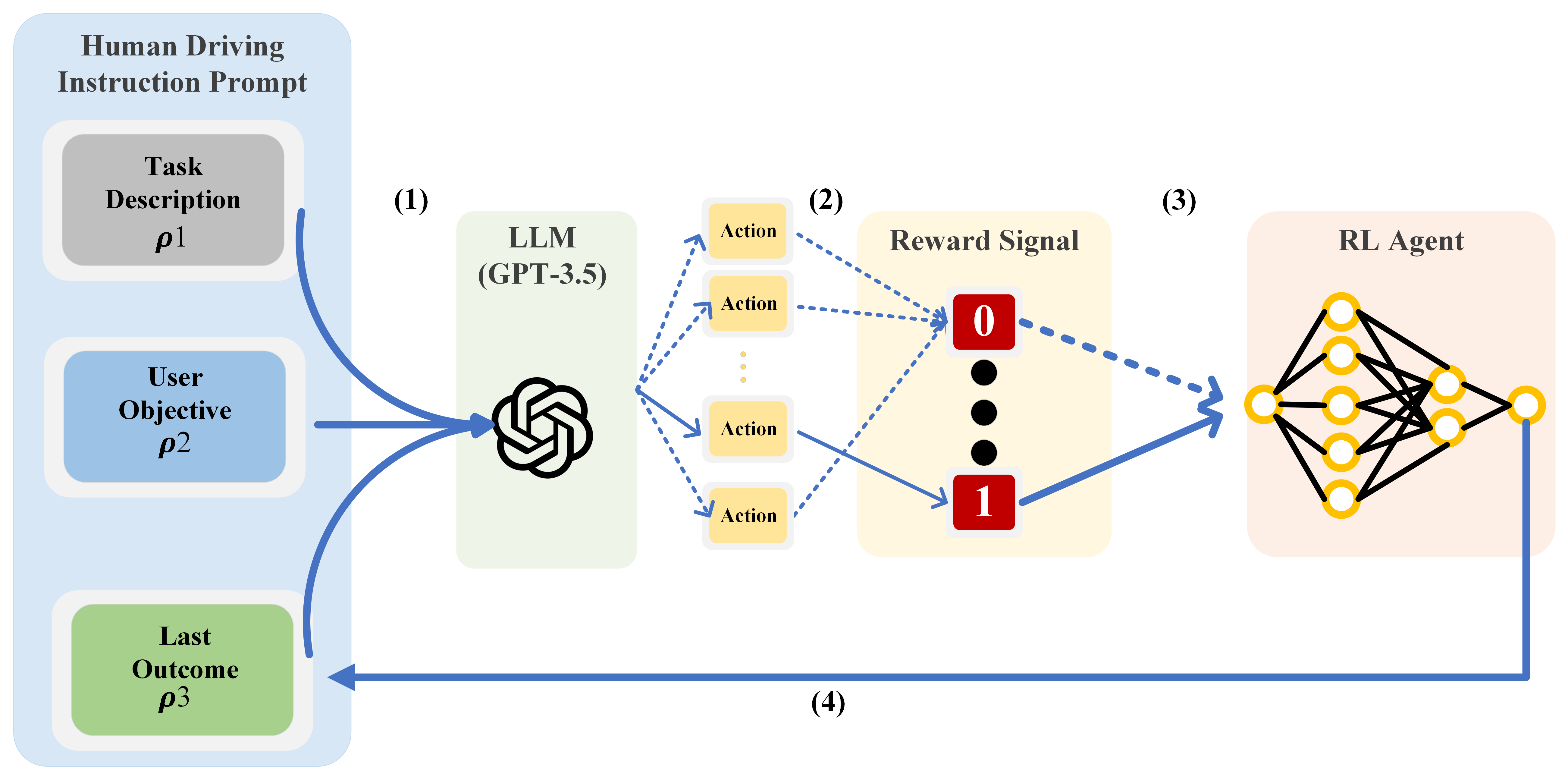
0
In-context Learning for Automated Driving Scenarios
Ziqi Zhou, Jingyue Zhang, Jingyuan Zhang, Boyue Wang, Tianyu Shi, Alaa Khamis
One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach utilizing Large Language Models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also reaches better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced and human-like automated driving systems. Our experimental data and source code can be found here.
Read more5/8/2024
🌿
0
Incremental Learning of Humanoid Robot Behavior from Natural Interaction and Large Language Models
Leonard Barmann, Rainer Kartmann, Fabian Peller-Konrad, Jan Niehues, Alex Waibel, Tamim Asfour
Natural-language dialog is key for intuitive human-robot interaction. It can be used not only to express humans' intents, but also to communicate instructions for improvement if a robot does not understand a command correctly. Of great importance is to endow robots with the ability to learn from such interaction experience in an incremental way to allow them to improve their behaviors or avoid mistakes in the future. In this paper, we propose a system to achieve incremental learning of complex behavior from natural interaction, and demonstrate its implementation on a humanoid robot. Building on recent advances, we present a system that deploys Large Language Models (LLMs) for high-level orchestration of the robot's behavior, based on the idea of enabling the LLM to generate Python statements in an interactive console to invoke both robot perception and action. The interaction loop is closed by feeding back human instructions, environment observations, and execution results to the LLM, thus informing the generation of the next statement. Specifically, we introduce incremental prompt learning, which enables the system to interactively learn from its mistakes. For that purpose, the LLM can call another LLM responsible for code-level improvements of the current interaction based on human feedback. The improved interaction is then saved in the robot's memory, and thus retrieved on similar requests. We integrate the system in the robot cognitive architecture of the humanoid robot ARMAR-6 and evaluate our methods both quantitatively (in simulation) and qualitatively (in simulation and real-world) by demonstrating generalized incrementally-learned knowledge.
Read more5/17/2024