Prompted Aspect Key Point Analysis for Quantitative Review Summarization

0
Sign in to get full access
Overview
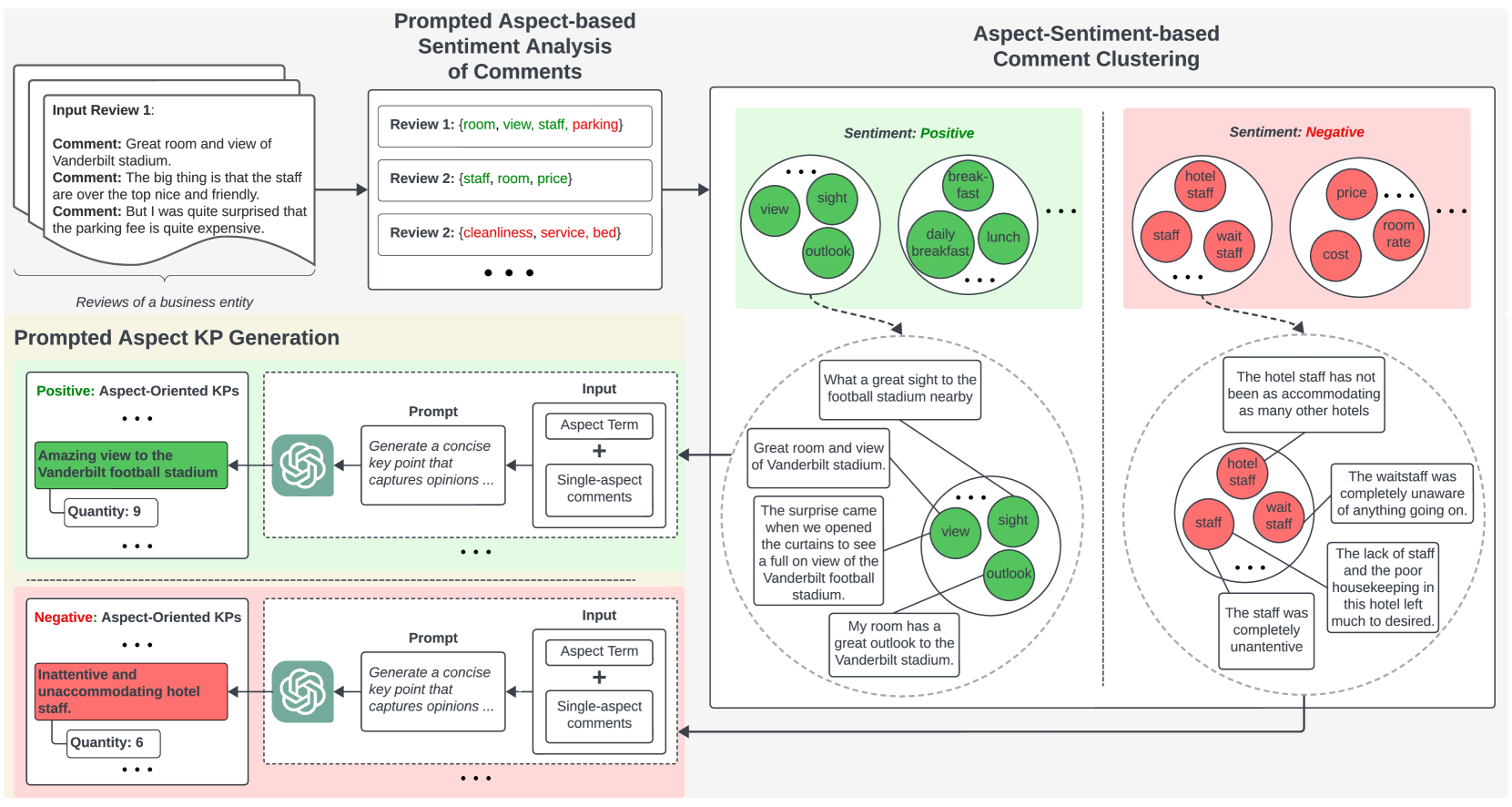
- The paper focuses on a technique called "Prompted Aspect Key Point Analysis" for summarizing quantitative reviews.
- It aims to extract the key points from a review text that address specific aspects or criteria.
- The technique involves using prompts to guide a language model in identifying the most important information.
Plain English Explanation
The paper describes a method for summarizing quantitative reviews in a more targeted and useful way. The idea is to identify the key points from a review that are most relevant to specific aspects or criteria that the reviewer is evaluating.
For example, if you're reading a review of a product, the key points might cover things like the product's features, performance, ease of use, and value. This method uses prompts to guide a language model in pinpointing the information that addresses those specific aspects, rather than just providing a generic summary.
The goal is to make the summary more useful for readers by focusing on the details that are most relevant to the criteria they care about, rather than just providing a high-level overview.
Technical Explanation
The paper proposes a technique called "Prompted Aspect Key Point Analysis" for summarizing quantitative reviews. The key steps are:
-
Aspect Identification: The reviewers or researchers identify the specific aspects or criteria they want to focus on in the summary (e.g., features, performance, ease of use).
-
Prompt Engineering: The team designs prompts that guide a language model to extract the most relevant information for each aspect. These prompts are structured to elicit the key points that address the specified criteria.
-
Language Model Application: The prompts are used to query the language model, which then generates summaries that highlight the most important information for each aspect.
The paper evaluates this approach on a dataset of product reviews, showing that it can produce more targeted and useful summaries compared to generic techniques. The prompts help the model zero in on the details that are most relevant to the aspects of interest.
Critical Analysis
The paper presents a promising approach, but there are some potential limitations and areas for further research:
-
Domain Generalization: The evaluation was focused on product reviews, so more work may be needed to see how well the technique generalizes to other types of quantitative reviews (e.g., scientific papers, business reports).
-
Prompt Engineering Effort: Designing effective prompts requires significant time and expertise. Automating or streamlining the prompt engineering process could make the technique more accessible.
-
Subjectivity of Aspect Prioritization: Different readers may have different priorities when it comes to the aspects they care about. The paper doesn't address how to handle this subjective element.
-
Potential Biases: Like any language model-based system, there is a risk of the technique perpetuating biases present in the training data. Careful monitoring and mitigation strategies may be necessary.
Overall, the paper introduces an interesting idea for improving the usefulness of review summaries, but there are still some challenges to overcome for wider adoption and applicability.
Conclusion
This paper presents a novel technique called "Prompted Aspect Key Point Analysis" for generating more targeted and useful summaries of quantitative reviews. By using prompts to guide a language model in identifying the key points that address specific aspects or criteria, the method can produce summaries that are tailored to the reader's priorities.
While the approach shows promise, there are still some limitations and areas for further research, such as improving the prompt engineering process, addressing the subjective nature of aspect prioritization, and ensuring the technique can generalize to a wider range of domains. Overall, the paper introduces an interesting idea that could have significant implications for enhancing the usefulness of review summaries and related applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompted Aspect Key Point Analysis for Quantitative Review Summarization
An Quang Tang, Xiuzhen Zhang, Minh Ngoc Dinh, Erik Cambria
Key Point Analysis (KPA) aims for quantitative summarization that provides key points (KPs) as succinct textual summaries and quantities measuring their prevalence. KPA studies for arguments and reviews have been reported in the literature. A majority of KPA studies for reviews adopt supervised learning to extract short sentences as KPs before matching KPs to review comments for quantification of KP prevalence. Recent abstractive approaches still generate KPs based on sentences, often leading to KPs with overlapping and hallucinated opinions, and inaccurate quantification. In this paper, we propose Prompted Aspect Key Point Analysis (PAKPA) for quantitative review summarization. PAKPA employs aspect sentiment analysis and prompted in-context learning with Large Language Models (LLMs) to generate and quantify KPs grounded in aspects for business entities, which achieves faithful KPs with accurate quantification, and removes the need for large amounts of annotated data for supervised training. Experiments on the popular review dataset Yelp and the aspect-oriented review summarization dataset SPACE show that our framework achieves state-of-the-art performance. Source code and data are available at: https://github.com/antangrocket1312/PAKPA
Read more7/22/2024

0
Enhancing Argument Summarization: Prioritizing Exhaustiveness in Key Point Generation and Introducing an Automatic Coverage Evaluation Metric
Mohammad Khosravani, Chenyang Huang, Amine Trabelsi
The proliferation of social media platforms has given rise to the amount of online debates and arguments. Consequently, the need for automatic summarization methods for such debates is imperative, however this area of summarization is rather understudied. The Key Point Analysis (KPA) task formulates argument summarization as representing the summary of a large collection of arguments in the form of concise sentences in bullet-style format, called key points. A sub-task of KPA, called Key Point Generation (KPG), focuses on generating these key points given the arguments. This paper introduces a novel extractive approach for key point generation, that outperforms previous state-of-the-art methods for the task. Our method utilizes an extractive clustering based approach that offers concise, high quality generated key points with higher coverage of reference summaries, and less redundant outputs. In addition, we show that the existing evaluation metrics for summarization such as ROUGE are incapable of differentiating between generated key points of different qualities. To this end, we propose a new evaluation metric for assessing the generated key points by their coverage. Our code can be accessed online.
Read more4/19/2024

0
Key-Point-Driven Data Synthesis with its Enhancement on Mathematical Reasoning
Yiming Huang, Xiao Liu, Yeyun Gong, Zhibin Gou, Yelong Shen, Nan Duan, Weizhu Chen
Large language models (LLMs) have shown great potential in complex reasoning tasks, yet their performance is often hampered by the scarcity of high-quality and reasoning-focused training datasets. Addressing this challenge, we propose Key-Point-Driven Data Synthesis (KPDDS), a novel data synthesis framework that synthesizes question-answer pairs by leveraging key points and exemplar practices from authentic data sources. KPDDS ensures the generation of novel questions with rigorous quality control and substantial scalability. As a result, we present KPMath, an extensive synthetic dataset tailored for mathematical reasoning, comprising over 800K question-answer pairs. Utilizing KPMath and augmenting it with additional reasoning-intensive corpora, we create the comprehensive KPMath-Plus dataset. The Qwen1.5-72B model, fine-tuned on KPMath-Plus, achieves 87.0% PASS@1 accuracy on GSM8K and 58.3% on MATH, surpassing competitors in the 7B to 70B range and best commercial models like GPT-4 across multiple math reasoning datasets.
Read more5/9/2024

0
Pre-Trained Language Models for Keyphrase Prediction: A Review
Muhammad Umair, Tangina Sultana, Young-Koo Lee
Keyphrase Prediction (KP) is essential for identifying keyphrases in a document that can summarize its content. However, recent Natural Language Processing (NLP) advances have developed more efficient KP models using deep learning techniques. The limitation of a comprehensive exploration jointly both keyphrase extraction and generation using pre-trained language models spotlights a critical gap in the literature, compelling our survey paper to bridge this deficiency and offer a unified and in-depth analysis to address limitations in previous surveys. This paper extensively examines the topic of pre-trained language models for keyphrase prediction (PLM-KP), which are trained on large text corpora via different learning (supervisor, unsupervised, semi-supervised, and self-supervised) techniques, to provide respective insights into these two types of tasks in NLP, precisely, Keyphrase Extraction (KPE) and Keyphrase Generation (KPG). We introduce appropriate taxonomies for PLM-KPE and KPG to highlight these two main tasks of NLP. Moreover, we point out some promising future directions for predicting keyphrases.
Read more9/4/2024