Enhancing Argument Summarization: Prioritizing Exhaustiveness in Key Point Generation and Introducing an Automatic Coverage Evaluation Metric

0

Sign in to get full access
Overview
- This paper focuses on enhancing argument summarization by prioritizing exhaustiveness in key point generation and introducing an automatic coverage evaluation metric.
- The researchers aim to address limitations in current argument summarization approaches, which often fail to capture all important points and lack effective evaluation methods.
- The paper proposes a novel key point generation model that prioritizes exhaustiveness and an automatic coverage evaluation metric to assess the quality of generated summaries.
Plain English Explanation
The paper is about improving how computers can automatically summarize the main arguments in a document. Current summarization systems often miss important points or fail to capture the full scope of the arguments.
To address this, the researchers developed a new model that focuses on generating a more complete set of key points that cover all the important arguments. They also created a new evaluation metric that can automatically assess how well the generated summaries cover the original content.
The key idea is to make sure the summarization process is as thorough and exhaustive as possible, capturing all the essential arguments rather than just the most prominent ones. This helps ensure the summaries provide a comprehensive overview of the document's main points.
The new evaluation metric is also important, as it allows researchers and developers to quantify how well their summarization systems are performing in terms of covering the full scope of the original content. This makes it easier to compare different summarization approaches and identify areas for improvement.
Overall, this research aims to enhance the quality and usefulness of automatic argument summarization, which has important applications in fields like policy analysis, decision-making, and education.
Technical Explanation
The paper proposes two main contributions to improve argument summarization:
- Exhaustive Key Point Generation Model: The researchers developed a novel key point generation model that prioritizes extracting a more comprehensive set of important points from the input text. This is in contrast to traditional approaches that tend to focus on identifying the most salient points.
The model uses a cover tree data structure to efficiently search for and extract a diverse set of key points that collectively cover the main arguments. This helps ensure the generated summaries are more exhaustive and representative of the original content.
- Automatic Coverage Evaluation Metric: The researchers also introduced a new automatic metric to evaluate the coverage of generated summaries. This metric assesses how well the key points in the summary capture the important arguments from the original text.
The metric works by comparing the key points in the summary to a ground truth set of key points, measuring the overlap and ensuring the summary covers a high proportion of the essential content. This provides a more rigorous and objective way to assess the quality of argument summaries.
The paper evaluates the proposed model and coverage metric on several benchmark datasets for argument summarization. The results demonstrate that the exhaustive key point generation approach outperforms previous state-of-the-art summarization methods in terms of capturing a more comprehensive set of arguments. The new coverage metric also proves effective at differentiating between summaries of varying quality.
Critical Analysis
The researchers acknowledge several limitations in their work that could be addressed in future research:
- The exhaustive key point generation model relies on heuristics to balance coverage and conciseness, which could be further refined or automated.
- The coverage evaluation metric assumes the availability of ground truth key points, which may not always be easy to obtain, especially for larger or more complex documents.
- The experiments were conducted on a limited set of argument summarization datasets, and the model's performance may vary on different types of text or domains.
Additionally, some potential areas for further exploration include:
- Incorporating user preferences or task-specific requirements into the summarization process to better tailor the output to user needs.
- Exploring ways to combine the exhaustive key point generation with topic-aware summarization techniques to balance coverage and relevance.
- Investigating ways to efficiently extract key phrases from the input text to further improve the quality of the generated summaries.
Overall, this research presents a promising approach to address important limitations in current argument summarization systems. The focus on exhaustiveness and the introduction of a new coverage evaluation metric are valuable contributions that could help advance the field of automatic text summarization.
Conclusion
This paper introduces two key innovations to enhance argument summarization: an exhaustive key point generation model and an automatic coverage evaluation metric. The proposed techniques aim to address limitations in current summarization approaches, which often fail to capture all the important arguments and lack effective ways to assess the quality of the generated summaries.
The exhaustive key point generation model leverages a cover tree data structure to efficiently extract a more comprehensive set of key points that collectively represent the main arguments in the input text. The new coverage evaluation metric provides a more rigorous way to assess how well the generated summaries cover the essential content of the original document.
The experimental results demonstrate the effectiveness of these approaches, suggesting they could lead to significant improvements in the quality and usefulness of automatic argument summarization. This has important implications for applications such as policy analysis, decision-making, and education, where comprehensive and accurate summaries of complex arguments are crucial.
While the research presents some limitations, the proposed innovations open up exciting avenues for further exploration and refinement of argument summarization techniques. Incorporating user preferences, combining exhaustiveness with topic-aware summarization, and exploring efficient key phrase extraction are some potential directions for future work in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Argument Summarization: Prioritizing Exhaustiveness in Key Point Generation and Introducing an Automatic Coverage Evaluation Metric
Mohammad Khosravani, Chenyang Huang, Amine Trabelsi
The proliferation of social media platforms has given rise to the amount of online debates and arguments. Consequently, the need for automatic summarization methods for such debates is imperative, however this area of summarization is rather understudied. The Key Point Analysis (KPA) task formulates argument summarization as representing the summary of a large collection of arguments in the form of concise sentences in bullet-style format, called key points. A sub-task of KPA, called Key Point Generation (KPG), focuses on generating these key points given the arguments. This paper introduces a novel extractive approach for key point generation, that outperforms previous state-of-the-art methods for the task. Our method utilizes an extractive clustering based approach that offers concise, high quality generated key points with higher coverage of reference summaries, and less redundant outputs. In addition, we show that the existing evaluation metrics for summarization such as ROUGE are incapable of differentiating between generated key points of different qualities. To this end, we propose a new evaluation metric for assessing the generated key points by their coverage. Our code can be accessed online.
Read more4/19/2024
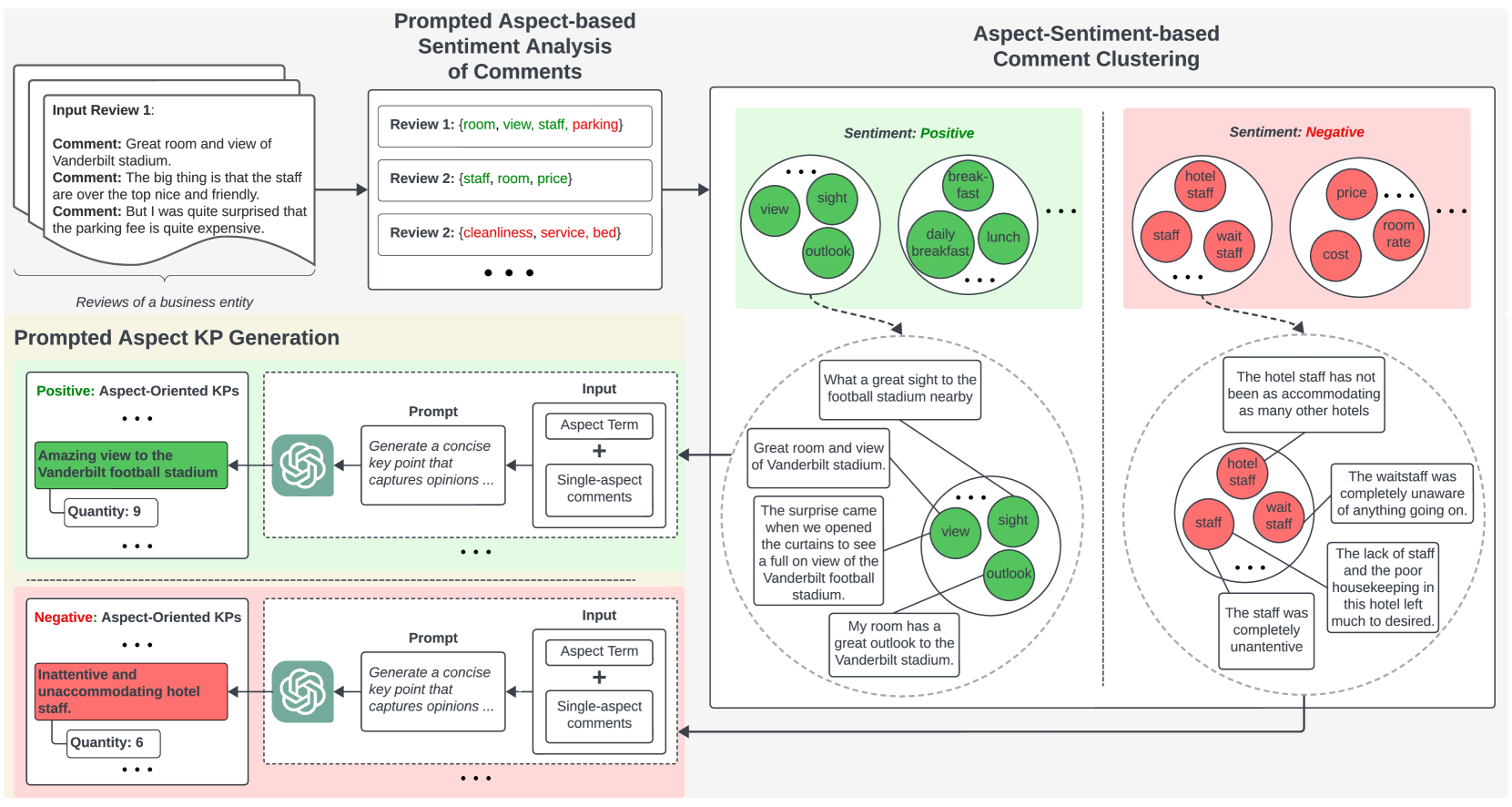
0
Prompted Aspect Key Point Analysis for Quantitative Review Summarization
An Quang Tang, Xiuzhen Zhang, Minh Ngoc Dinh, Erik Cambria
Key Point Analysis (KPA) aims for quantitative summarization that provides key points (KPs) as succinct textual summaries and quantities measuring their prevalence. KPA studies for arguments and reviews have been reported in the literature. A majority of KPA studies for reviews adopt supervised learning to extract short sentences as KPs before matching KPs to review comments for quantification of KP prevalence. Recent abstractive approaches still generate KPs based on sentences, often leading to KPs with overlapping and hallucinated opinions, and inaccurate quantification. In this paper, we propose Prompted Aspect Key Point Analysis (PAKPA) for quantitative review summarization. PAKPA employs aspect sentiment analysis and prompted in-context learning with Large Language Models (LLMs) to generate and quantify KPs grounded in aspects for business entities, which achieves faithful KPs with accurate quantification, and removes the need for large amounts of annotated data for supervised training. Experiments on the popular review dataset Yelp and the aspect-oriented review summarization dataset SPACE show that our framework achieves state-of-the-art performance. Source code and data are available at: https://github.com/antangrocket1312/PAKPA
Read more7/22/2024
⛏️
0
Thesis: Document Summarization with applications to Keyword extraction and Image Retrieval
Jayaprakash Sundararaj
Automatic summarization is the process of reducing a text document in order to generate a summary that retains the most important points of the original document. In this work, we study two problems - i) summarizing a text document as set of keywords/caption, for image recommedation, ii) generating opinion summary which good mix of relevancy and sentiment with the text document. Intially, we present our work on an recommending images for enhancing a substantial amount of existing plain text news articles. We use probabilistic models and word similarity heuristics to generate captions and extract Key-phrases which are re-ranked using a rank aggregation framework with relevance feedback mechanism. We show that such rank aggregation and relevant feedback which are typically used in Tagging Documents, Text Information Retrieval also helps in improving image retrieval. These queries are fed to the Yahoo Search Engine to obtain relevant images 1. Our proposed method is observed to perform better than all existing baselines. Additonally, We propose a set of submodular functions for opinion summarization. Opinion summarization has built in it the tasks of summarization and sentiment detection. However, it is not easy to detect sentiment and simultaneously extract summary. The two tasks conflict in the sense that the demand of compression may drop sentiment bearing sentences, and the demand of sentiment detection may bring in redundant sentences. However, using submodularity we show how to strike a balance between the two requirements. Our functions generate summaries such that there is good correlation between document sentiment and summary sentiment along with good ROUGE score. We also compare the performances of the proposed submodular functions.
Read more6/4/2024
📊
0
KPEval: Towards Fine-Grained Semantic-Based Keyphrase Evaluation
Di Wu, Da Yin, Kai-Wei Chang
Despite the significant advancements in keyphrase extraction and keyphrase generation methods, the predominant approach for evaluation mainly relies on exact matching with human references. This scheme fails to recognize systems that generate keyphrases semantically equivalent to the references or diverse keyphrases that carry practical utility. To better assess the capability of keyphrase systems, we propose KPEval, a comprehensive evaluation framework consisting of four critical aspects: reference agreement, faithfulness, diversity, and utility. For each aspect, we design semantic-based metrics to reflect the evaluation objectives. Meta-evaluation studies demonstrate that our evaluation strategy correlates better with human preferences compared to a range of previously proposed metrics. Using KPEval, we re-evaluate 23 keyphrase systems and discover that (1) established model comparison results have blind-spots especially when considering reference-free evaluation; (2) large language models are underestimated by prior evaluation works; and (3) there is no single best model that can excel in all the aspects.
Read more6/5/2024