PromptFix: You Prompt and We Fix the Photo
2405.16785
0
0
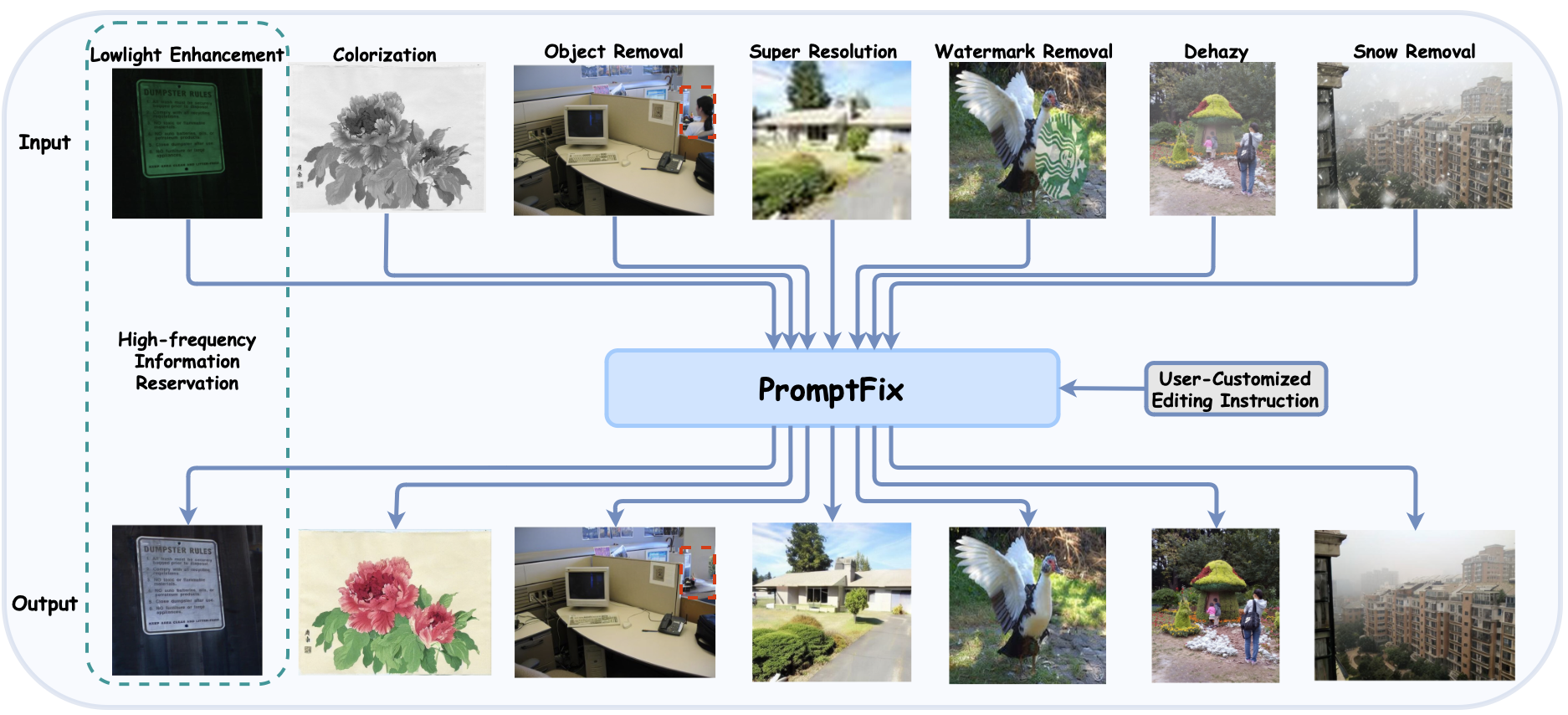
Abstract
Diffusion models equipped with language models demonstrate excellent controllability in image generation tasks, allowing image processing to adhere to human instructions. However, the lack of diverse instruction-following data hampers the development of models that effectively recognize and execute user-customized instructions, particularly in low-level tasks. Moreover, the stochastic nature of the diffusion process leads to deficiencies in image generation or editing tasks that require the detailed preservation of the generated images. To address these limitations, we propose PromptFix, a comprehensive framework that enables diffusion models to follow human instructions to perform a wide variety of image-processing tasks. First, we construct a large-scale instruction-following dataset that covers comprehensive image-processing tasks, including low-level tasks, image editing, and object creation. Next, we propose a high-frequency guidance sampling method to explicitly control the denoising process and preserve high-frequency details in unprocessed areas. Finally, we design an auxiliary prompting adapter, utilizing Vision-Language Models (VLMs) to enhance text prompts and improve the model's task generalization. Experimental results show that PromptFix outperforms previous methods in various image-processing tasks. Our proposed model also achieves comparable inference efficiency with these baseline models and exhibits superior zero-shot capabilities in blind restoration and combination tasks. The dataset and code will be aviliable at https://github.com/yeates/PromptFix.
Create account to get full access
Overview
- This paper introduces PromptFix, a system that allows users to provide a prompt and have the system automatically fix and improve the image generated from that prompt.
- PromptFix leverages recent advancements in text-to-image generation models and prompt engineering techniques to enhance the quality and fidelity of generated images.
- The key innovations of PromptFix include a prompt-driven image refinement module and a prompt optimization framework to iteratively improve the input prompt.
Plain English Explanation
PromptFix is a new system that makes it easier to create high-quality images from textual descriptions. Many existing text-to-image models struggle to fully capture all the nuances and details specified in a prompt. PromptFix aims to address this by automatically refining and improving the generated images.
Here's how it works: You provide a written description or prompt about the image you want to create. PromptFix then uses advanced AI techniques to analyze that prompt and generate an initial image. But it doesn't stop there. PromptFix then evaluates the image and automatically tweaks the prompt to make the image better match what you had in mind. It can do this repeatedly, iteratively improving the prompt and the generated image until you're satisfied with the result.
This allows users to easily create complex, photorealistic images from simple textual descriptions, without needing specialized artistic or editing skills. The prompt engineering techniques used in PromptFix help ensure the final image closely matches the user's vision, even for detailed or elaborate prompts.
Technical Explanation
PromptFix builds on recent advancements in text-to-image generation and prompt optimization. The core architecture consists of three key components:
- Prompt Encoder: This module takes the user's input prompt and encodes it into a latent representation that can be used to guide the image generation process.
- Image Generator: A generative model that produces an initial image based on the encoded prompt.
- Prompt Optimizer: This component analyzes the generated image and iteratively refines the input prompt to improve the quality and fidelity of the output.
The prompt optimizer uses a combination of perceptual similarity metrics and learned heuristics to identify areas where the generated image deviates from the intended prompt. It then suggests prompt modifications that can address these issues, feeding the updated prompt back into the generation pipeline. This iterative process continues until the generated image satisfies a predefined quality threshold.
Critical Analysis
The authors acknowledge several limitations of the current PromptFix system. First, the prompt optimization process can be computationally expensive, especially for complex prompts that require many refinement iterations. This may limit the real-time performance of the system, particularly on resource-constrained devices.
Additionally, the paper does not extensively explore the limits of PromptFix's capabilities. It would be valuable to understand the types of prompts that the system struggles with, as well as the maximum level of detail and complexity it can handle effectively. Further research is needed to fully characterize the strengths and weaknesses of the approach.
Finally, the paper does not address potential societal implications or ethical concerns around the use of such a powerful image generation system. As text-to-image models become more advanced, it will be important to consider issues such as the potential for misuse, bias, and the impact on human creativity and employment.
Conclusion
The PromptFix system represents an exciting step forward in bridging the gap between textual descriptions and high-quality, photorealistic images. By combining state-of-the-art text-to-image generation with an iterative prompt optimization process, PromptFix empowers users to easily create complex visual content from simple textual inputs.
While the current implementation has some limitations, the core ideas behind PromptFix have the potential to significantly impact fields such as digital art, product design, and visual storytelling. As the underlying technologies continue to evolve, systems like PromptFix may become powerful tools for democratizing and enhancing visual creativity for a wide range of users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Batch-Instructed Gradient for Prompt Evolution:Systematic Prompt Optimization for Enhanced Text-to-Image Synthesis
Xinrui Yang, Zhuohan Wang, Anthony Hu
0
0
Text-to-image models have shown remarkable progress in generating high-quality images from user-provided prompts. Despite this, the quality of these images varies due to the models' sensitivity to human language nuances. With advancements in large language models, there are new opportunities to enhance prompt design for image generation tasks. Existing research primarily focuses on optimizing prompts for direct interaction, while less attention is given to scenarios involving intermediary agents, like the Stable Diffusion model. This study proposes a Multi-Agent framework to optimize input prompts for text-to-image generation models. Central to this framework is a prompt generation mechanism that refines initial queries using dynamic instructions, which evolve through iterative performance feedback. High-quality prompts are then fed into a state-of-the-art text-to-image model. A professional prompts database serves as a benchmark to guide the instruction modifier towards generating high-caliber prompts. A scoring system evaluates the generated images, and an LLM generates new instructions based on calculated gradients. This iterative process is managed by the Upper Confidence Bound (UCB) algorithm and assessed using the Human Preference Score version 2 (HPS v2). Preliminary ablation studies highlight the effectiveness of various system components and suggest areas for future improvements.
6/14/2024

FilterPrompt: Guiding Image Transfer in Diffusion Models
Xi Wang, Yichen Peng, Heng Fang, Haoran Xie, Xi Yang, Chuntao Li
0
0
In controllable generation tasks, flexibly manipulating the generated images to attain a desired appearance or structure based on a single input image cue remains a critical and longstanding challenge. Achieving this requires the effective decoupling of key attributes within the input image data, aiming to get representations accurately. Previous research has predominantly concentrated on disentangling image attributes within feature space. However, the complex distribution present in real-world data often makes the application of such decoupling algorithms to other datasets challenging. Moreover, the granularity of control over feature encoding frequently fails to meet specific task requirements. Upon scrutinizing the characteristics of various generative models, we have observed that the input sensitivity and dynamic evolution properties of the diffusion model can be effectively fused with the explicit decomposition operation in pixel space. This integration enables the image processing operations performed in pixel space for a specific feature distribution of the input image, and can achieve the desired control effect in the generated results. Therefore, we propose FilterPrompt, an approach to enhance the model control effect. It can be universally applied to any diffusion model, allowing users to adjust the representation of specific image features in accordance with task requirements, thereby facilitating more precise and controllable generation outcomes. In particular, our designed experiments demonstrate that the FilterPrompt optimizes feature correlation, mitigates content conflicts during the generation process, and enhances the model's control capability.
5/14/2024
Improving face generation quality and prompt following with synthetic captions
Michail Tarasiou, Stylianos Moschoglou, Jiankang Deng, Stefanos Zafeiriou
0
0
Recent advancements in text-to-image generation using diffusion models have significantly improved the quality of generated images and expanded the ability to depict a wide range of objects. However, ensuring that these models adhere closely to the text prompts remains a considerable challenge. This issue is particularly pronounced when trying to generate photorealistic images of humans. Without significant prompt engineering efforts models often produce unrealistic images and typically fail to incorporate the full extent of the prompt information. This limitation can be largely attributed to the nature of captions accompanying the images used in training large scale diffusion models, which typically prioritize contextual information over details related to the person's appearance. In this paper we address this issue by introducing a training-free pipeline designed to generate accurate appearance descriptions from images of people. We apply this method to create approximately 250,000 captions for publicly available face datasets. We then use these synthetic captions to fine-tune a text-to-image diffusion model. Our results demonstrate that this approach significantly improves the model's ability to generate high-quality, realistic human faces and enhances adherence to the given prompts, compared to the baseline model. We share our synthetic captions, pretrained checkpoints and training code.
5/20/2024
🛸
NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation
Shachar Rosenman, Vasudev Lal, Phillip Howard
0
0
Despite impressive recent advances in text-to-image diffusion models, obtaining high-quality images often requires prompt engineering by humans who have developed expertise in using them. In this work, we present NeuroPrompts, an adaptive framework that automatically enhances a user's prompt to improve the quality of generations produced by text-to-image models. Our framework utilizes constrained text decoding with a pre-trained language model that has been adapted to generate prompts similar to those produced by human prompt engineers. This approach enables higher-quality text-to-image generations and provides user control over stylistic features via constraint set specification. We demonstrate the utility of our framework by creating an interactive application for prompt enhancement and image generation using Stable Diffusion. Additionally, we conduct experiments utilizing a large dataset of human-engineered prompts for text-to-image generation and show that our approach automatically produces enhanced prompts that result in superior image quality. We make our code and a screencast video demo of NeuroPrompts publicly available.
4/9/2024