FilterPrompt: Guiding Image Transfer in Diffusion Models
2404.13263
0
0

Abstract
In controllable generation tasks, flexibly manipulating the generated images to attain a desired appearance or structure based on a single input image cue remains a critical and longstanding challenge. Achieving this requires the effective decoupling of key attributes within the input image data, aiming to get representations accurately. Previous research has predominantly concentrated on disentangling image attributes within feature space. However, the complex distribution present in real-world data often makes the application of such decoupling algorithms to other datasets challenging. Moreover, the granularity of control over feature encoding frequently fails to meet specific task requirements. Upon scrutinizing the characteristics of various generative models, we have observed that the input sensitivity and dynamic evolution properties of the diffusion model can be effectively fused with the explicit decomposition operation in pixel space. This integration enables the image processing operations performed in pixel space for a specific feature distribution of the input image, and can achieve the desired control effect in the generated results. Therefore, we propose FilterPrompt, an approach to enhance the model control effect. It can be universally applied to any diffusion model, allowing users to adjust the representation of specific image features in accordance with task requirements, thereby facilitating more precise and controllable generation outcomes. In particular, our designed experiments demonstrate that the FilterPrompt optimizes feature correlation, mitigates content conflicts during the generation process, and enhances the model's control capability.
Create account to get full access
Overview
- This paper proposes a novel technique called FilterPrompt for guiding image transfer in diffusion models.
- Diffusion models have shown impressive results in image generation, but often struggle with tasks like image-to-image translation.
- FilterPrompt aims to address this by enabling more controllable and semantically meaningful image transfer.
Plain English Explanation
Diffusion models are a type of AI system that can generate highly realistic images. However, they can have trouble with tasks like taking one image and transforming it into a different kind of image, a process known as image-to-image translation.
The FilterPrompt technique introduced in this paper tries to solve this problem. It gives the diffusion model more guidance and control over the image transfer process, allowing it to produce results that are more semantically meaningful and aligned with the user's intent.
For example, if you wanted to take a photo of a city street and turn it into an oil painting-style image, FilterPrompt could help the diffusion model understand the key elements to preserve (like the buildings and cars) versus the elements to transform (like the painting style). This results in more coherent and intentional image-to-image translations.
Technical Explanation
The core idea behind FilterPrompt is to explicitly decompose the image transfer process into separate content and style components. This is achieved by training the diffusion model to not only generate the final output image, but also to predict a set of content and style features that represent different aspects of the image.
During inference, the user can then provide a "prompt" that specifies the desired content and style characteristics, and the diffusion model uses this prompt to guide the image transfer in a more controlled and semantically meaningful way. The authors demonstrate the effectiveness of this approach through extensive experiments on various image-to-image translation tasks.
Critical Analysis
One potential limitation of the FilterPrompt approach is that it relies on the diffusion model being able to accurately predict the relevant content and style features. If the model struggles to disentangle these components, the guided image transfer may not work as intended.
Additionally, the paper does not explore the robustness of FilterPrompt to diverse or challenging input images, and it's unclear how well the technique would generalize to a wider range of image-to-image translation scenarios.
Further research could investigate ways to make the content/style decomposition more robust, as well as explore adversarial attacks on the FilterPrompt system to better understand its limitations.
Conclusion
Overall, the FilterPrompt technique represents an interesting and promising step towards more controllable and semantically meaningful image-to-image translation using diffusion models. By explicitly modeling content and style features, the approach allows for greater user guidance and better preservation of semantic information during the image transfer process. Further research to address the potential limitations could lead to even more powerful and versatile image manipulation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Enhancing Image Layout Control with Loss-Guided Diffusion Models
Zakaria Patel, Kirill Serkh
0
0
Diffusion models are a powerful class of generative models capable of producing high-quality images from pure noise. In particular, conditional diffusion models allow one to specify the contents of the desired image using a simple text prompt. Conditioning on a text prompt alone, however, does not allow for fine-grained control over the composition and layout of the final image, which instead depends closely on the initial noise distribution. While most methods which introduce spatial constraints (e.g., bounding boxes) require fine-tuning, a smaller and more recent subset of these methods are training-free. They are applicable whenever the prompt influences the model through an attention mechanism, and generally fall into one of two categories. The first entails modifying the cross-attention maps of specific tokens directly to enhance the signal in certain regions of the image. The second works by defining a loss function over the cross-attention maps, and using the gradient of this loss to guide the latent. While previous work explores these as alternative strategies, we provide an interpretation for these methods which highlights their complimentary features, and demonstrate that it is possible to obtain superior performance when both methods are used in concert.
5/24/2024
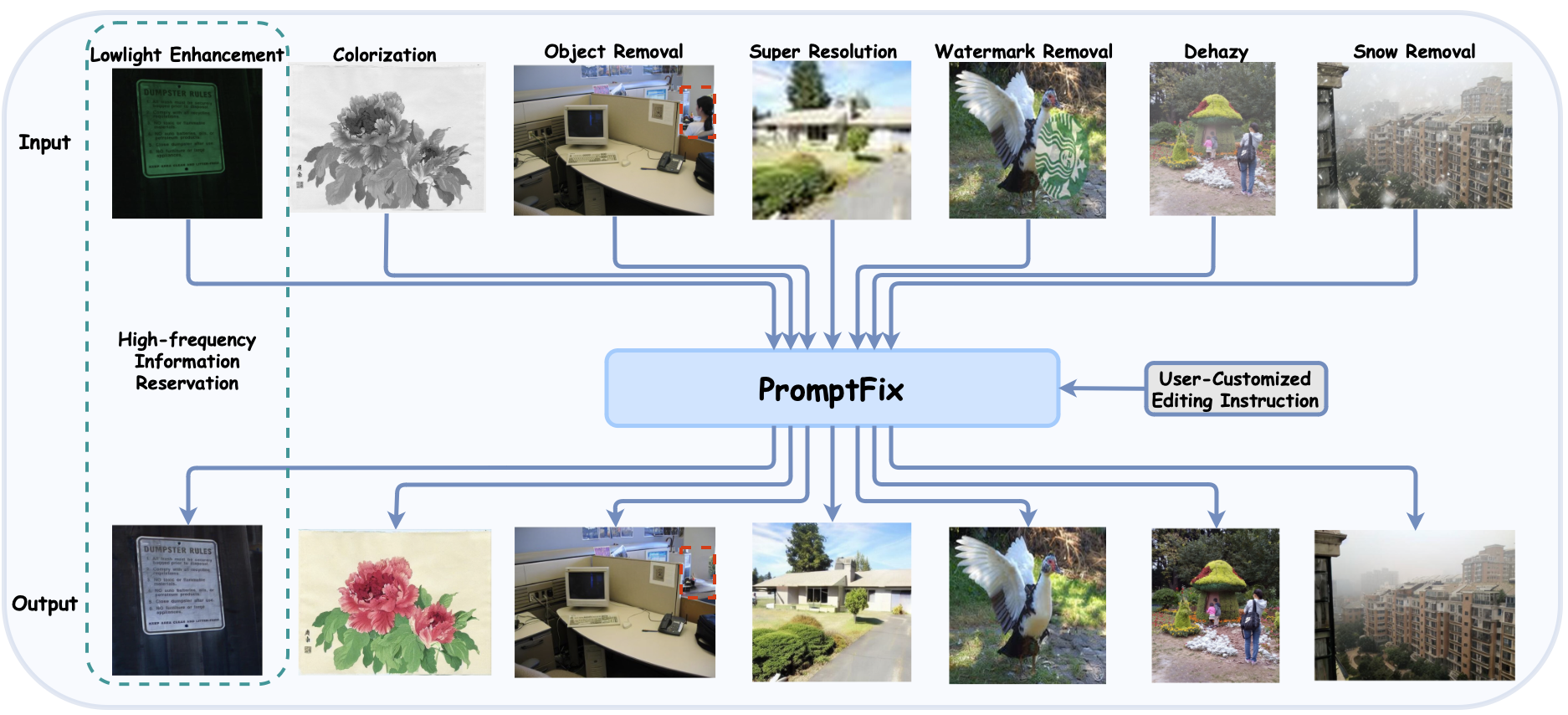
PromptFix: You Prompt and We Fix the Photo
Yongsheng Yu, Ziyun Zeng, Hang Hua, Jianlong Fu, Jiebo Luo
0
0
Diffusion models equipped with language models demonstrate excellent controllability in image generation tasks, allowing image processing to adhere to human instructions. However, the lack of diverse instruction-following data hampers the development of models that effectively recognize and execute user-customized instructions, particularly in low-level tasks. Moreover, the stochastic nature of the diffusion process leads to deficiencies in image generation or editing tasks that require the detailed preservation of the generated images. To address these limitations, we propose PromptFix, a comprehensive framework that enables diffusion models to follow human instructions to perform a wide variety of image-processing tasks. First, we construct a large-scale instruction-following dataset that covers comprehensive image-processing tasks, including low-level tasks, image editing, and object creation. Next, we propose a high-frequency guidance sampling method to explicitly control the denoising process and preserve high-frequency details in unprocessed areas. Finally, we design an auxiliary prompting adapter, utilizing Vision-Language Models (VLMs) to enhance text prompts and improve the model's task generalization. Experimental results show that PromptFix outperforms previous methods in various image-processing tasks. Our proposed model also achieves comparable inference efficiency with these baseline models and exhibits superior zero-shot capabilities in blind restoration and combination tasks. The dataset and code will be aviliable at https://github.com/yeates/PromptFix.
5/28/2024
Guiding a Diffusion Model with a Bad Version of Itself
Tero Karras, Miika Aittala, Tuomas Kynkaanniemi, Jaakko Lehtinen, Timo Aila, Samuli Laine
0
0
The primary axes of interest in image-generating diffusion models are image quality, the amount of variation in the results, and how well the results align with a given condition, e.g., a class label or a text prompt. The popular classifier-free guidance approach uses an unconditional model to guide a conditional model, leading to simultaneously better prompt alignment and higher-quality images at the cost of reduced variation. These effects seem inherently entangled, and thus hard to control. We make the surprising observation that it is possible to obtain disentangled control over image quality without compromising the amount of variation by guiding generation using a smaller, less-trained version of the model itself rather than an unconditional model. This leads to significant improvements in ImageNet generation, setting record FIDs of 1.01 for 64x64 and 1.25 for 512x512, using publicly available networks. Furthermore, the method is also applicable to unconditional diffusion models, drastically improving their quality.
6/5/2024
🤷
Manipulating Embeddings of Stable Diffusion Prompts
Niklas Deckers, Julia Peters, Martin Potthast
0
0
Prompt engineering is still the primary way for users of generative text-to-image models to manipulate generated images in a targeted way. Based on treating the model as a continuous function and by passing gradients between the image space and the prompt embedding space, we propose and analyze a new method to directly manipulate the embedding of a prompt instead of the prompt text. We then derive three practical interaction tools to support users with image generation: (1) Optimization of a metric defined in the image space that measures, for example, the image style. (2) Supporting a user in creative tasks by allowing them to navigate in the image space along a selection of directions of near prompt embeddings. (3) Changing the embedding of the prompt to include information that a user has seen in a particular seed but has difficulty describing in the prompt. Compared to prompt engineering, user-driven prompt embedding manipulation enables a more fine-grained, targeted control that integrates a user's intentions. Our user study shows that our methods are considered less tedious and that the resulting images are often preferred.
6/26/2024