Prompting Encoder Models for Zero-Shot Classification: A Cross-Domain Study in Italian

0

Sign in to get full access
Overview
- The paper explores using prompting techniques to enable zero-shot classification in encoder models, focusing on a cross-domain study in Italian.
- The researchers investigate how well pre-trained language models can perform classification tasks without fine-tuning, by leveraging prompting.
- The study covers multiple domains, including news, reviews, and social media, to assess the generalization capabilities of the prompting approach.
Plain English Explanation
In this paper, the researchers looked at a technique called "prompting" to enable zero-shot classification using pre-trained language models.
The key idea behind prompting is to provide the model with a short "prompt" that describes the task, rather than fine-tuning the model on labeled data. This allows the model to be applied to new tasks and domains without the need for extensive retraining.
The researchers focused their study on the Italian language, and looked at how well this prompting approach worked across different types of text, such as news articles, product reviews, and social media posts. This allowed them to assess how well the models could generalize and perform classification tasks in a cross-domain setting.
Technical Explanation
The key aspects of the technical approach are:
-
Prompting Technique: The researchers used prompts in the form of short phrases that described the classification task, such as "This text is about [TOPIC]." These prompts were appended to the input text and used to elicit the desired classification from the pre-trained language model.
-
Cross-Domain Evaluation: The researchers evaluated the prompting approach across three different domains in Italian: news, reviews, and social media. This tested the model's ability to generalize and perform well in diverse text genres, rather than just a single domain.
-
Model Architectures: The researchers experimented with different pre-trained language models, including BERT and its Italian counterpart, to assess their zero-shot classification performance when prompted.
-
Evaluation Metrics: The study measured classification accuracy, as well as additional metrics like F1-score, to provide a more comprehensive assessment of the model's performance.
Critical Analysis
The paper provides a thorough evaluation of the prompting approach for zero-shot classification in Italian, covering multiple domains and model architectures. However, some potential limitations include:
- The study is focused on a single language (Italian), and it would be valuable to see how the prompting techniques generalize to other languages.
- The paper does not explore the impact of different prompt formulations or engineering on the model's performance, which could be an important area for further research.
- The generalization capabilities of the models are assessed across domains, but not necessarily across tasks, which could be an interesting avenue for future work.
Overall, the paper makes a valuable contribution to the understanding of how prompting can enable zero-shot classification, and the findings could have important implications for developing more versatile and adaptable AI systems.
Conclusion
This paper presents a comprehensive study on using prompting techniques to enable zero-shot classification with pre-trained language models, focusing on the Italian language and a cross-domain evaluation. The results demonstrate the potential of prompting to allow models to perform classification tasks in new domains without the need for extensive fine-tuning or retraining.
The findings suggest that prompting could be a powerful approach for building more flexible and adaptable AI systems that can generalize to a wide range of tasks and applications. Further research is needed to explore the limits of this technique and how it can be optimized for different languages and use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompting Encoder Models for Zero-Shot Classification: A Cross-Domain Study in Italian
Serena Auriemma, Martina Miliani, Mauro Madeddu, Alessandro Bondielli, Lucia Passaro, Alessandro Lenci
Addressing the challenge of limited annotated data in specialized fields and low-resource languages is crucial for the effective use of Language Models (LMs). While most Large Language Models (LLMs) are trained on general-purpose English corpora, there is a notable gap in models specifically tailored for Italian, particularly for technical and bureaucratic jargon. This paper explores the feasibility of employing smaller, domain-specific encoder LMs alongside prompting techniques to enhance performance in these specialized contexts. Our study concentrates on the Italian bureaucratic and legal language, experimenting with both general-purpose and further pre-trained encoder-only models. We evaluated the models on downstream tasks such as document classification and entity typing and conducted intrinsic evaluations using Pseudo-Log-Likelihood. The results indicate that while further pre-trained models may show diminished robustness in general knowledge, they exhibit superior adaptability for domain-specific tasks, even in a zero-shot setting. Furthermore, the application of calibration techniques and in-domain verbalizers significantly enhances the efficacy of encoder models. These domain-specialized models prove to be particularly advantageous in scenarios where in-domain resources or expertise are scarce. In conclusion, our findings offer new insights into the use of Italian models in specialized contexts, which may have a significant impact on both research and industrial applications in the digital transformation era.
Read more7/31/2024
0
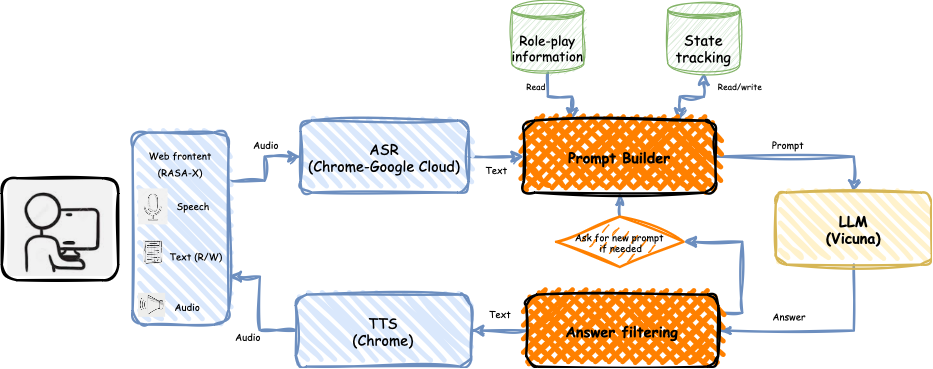
Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
Ahmed Njifenjou, Virgile Sucal, Bassam Jabaian, Fabrice Lef`evre
Recently, various methods have been proposed to create open-domain conversational agents with Large Language Models (LLMs). These models are able to answer user queries, but in a one-way Q&A format rather than a true conversation. Fine-tuning on particular datasets is the usual way to modify their style to increase conversational ability, but this is expensive and usually only available in a few languages. In this study, we explore role-play zero-shot prompting as an efficient and cost-effective solution for open-domain conversation, using capable multilingual LLMs (Beeching et al., 2023) trained to obey instructions. We design a prompting system that, when combined with an instruction-following model - here Vicuna (Chiang et al., 2023) - produces conversational agents that match and even surpass fine-tuned models in human evaluation in French in two different tasks.
Read more6/27/2024
0
Language Models for Text Classification: Is In-Context Learning Enough?
Aleksandra Edwards, Jose Camacho-Collados
Recent foundational language models have shown state-of-the-art performance in many NLP tasks in zero- and few-shot settings. An advantage of these models over more standard approaches based on fine-tuning is the ability to understand instructions written in natural language (prompts), which helps them generalise better to different tasks and domains without the need for specific training data. This makes them suitable for addressing text classification problems for domains with limited amounts of annotated instances. However, existing research is limited in scale and lacks understanding of how text generation models combined with prompting techniques compare to more established methods for text classification such as fine-tuning masked language models. In this paper, we address this research gap by performing a large-scale evaluation study for 16 text classification datasets covering binary, multiclass, and multilabel problems. In particular, we compare zero- and few-shot approaches of large language models to fine-tuning smaller language models. We also analyse the results by prompt, classification type, domain, and number of labels. In general, the results show how fine-tuning smaller and more efficient language models can still outperform few-shot approaches of larger language models, which have room for improvement when it comes to text classification.
Read more4/16/2024

0
Enabling Natural Zero-Shot Prompting on Encoder Models via Statement-Tuning
Ahmed Elshabrawy, Yongxin Huang, Iryna Gurevych, Alham Fikri Aji
While Large Language Models (LLMs) exhibit remarkable capabilities in zero-shot and few-shot scenarios, they often require computationally prohibitive sizes. Conversely, smaller Masked Language Models (MLMs) like BERT and RoBERTa achieve state-of-the-art results through fine-tuning but struggle with extending to few-shot and zero-shot settings due to their architectural constraints. Hence, we propose Statement-Tuning, a technique that models discriminative tasks as a set of finite statements and trains an Encoder model to discriminate between the potential statements to determine the label. We do Statement-Tuning on multiple tasks to enable cross-task generalization. Experimental results demonstrate that Statement Tuning achieves competitive performance compared to state-of-the-art LLMs with significantly fewer parameters. Moreover, the study investigates the impact of several design choices on few-shot and zero-shot generalization, revealing that Statement Tuning can achieve sufficient performance with modest training data and benefits from task and statement diversity for unseen task generalizability.
Read more4/23/2024