Prompting Whisper for QA-driven Zero-shot End-to-end Spoken Language Understanding
2406.15209
0
0

Abstract
Zero-shot spoken language understanding (SLU) enables systems to comprehend user utterances in new domains without prior exposure to training data. Recent studies often rely on large language models (LLMs), leading to excessive footprints and complexity. This paper proposes the use of Whisper, a standalone speech processing model, for zero-shot end-to-end (E2E) SLU. To handle unseen semantic labels, SLU tasks are integrated into a question-answering (QA) framework, which prompts the Whisper decoder for semantics deduction. The system is efficiently trained with prefix-tuning, optimising a minimal set of parameters rather than the entire Whisper model. We show that the proposed system achieves a 40.7% absolute gain for slot filling (SLU-F1) on SLURP compared to a recently introduced zero-shot benchmark. Furthermore, it performs comparably to a Whisper-GPT-2 modular system under both in-corpus and cross-corpus evaluation settings, but with a relative 34.8% reduction in model parameters.
Create account to get full access
Overview
- The paper presents a novel approach for zero-shot end-to-end spoken language understanding (SLU) using the Whisper language model.
- The proposed method, called Zero-shot Whisper SLU, leverages Whisper's speech recognition capabilities and prompts it with natural language questions to extract semantic information from speech.
- This allows the system to perform SLU without any task-specific training data, making it highly versatile and applicable across diverse domains.
- The authors demonstrate the effectiveness of their approach on several benchmarks, showcasing its strong performance compared to existing zero-shot and few-shot SLU techniques.
Plain English Explanation
The researchers have developed a new way to understand the meaning of spoken language without any prior training on specific tasks. They use a powerful speech recognition model called Whisper and prompt it with natural language questions to extract the key information from the speech.
For example, if someone says "I'd like to book a flight to New York next week," the system would be able to understand the intent (booking a flight), the destination (New York), and the timeframe (next week) without being trained on flight booking data. This zero-shot end-to-end spoken language understanding approach is highly versatile and can be applied to a wide range of applications, from customer service to home automation.
The researchers show that their method, called Zero-shot Whisper SLU, outperforms other zero-shot and few-shot SLU techniques on several benchmark datasets. This is an important advancement, as it means we can build intelligent systems that can understand spoken language without the need for large amounts of training data, which can be costly and time-consuming to collect.
Technical Explanation
The core of the Zero-shot Whisper SLU approach is the use of the Whisper language model. Whisper is a state-of-the-art speech recognition model that can transcribe speech into text. The researchers leverage Whisper's capabilities and prompt it with natural language questions to extract semantic information from the speech.
For example, if the audio input is "I'd like to book a flight to New York next week," the system would prompt Whisper with a question like "What is the intent, destination, and timeframe in the given speech?" Whisper would then generate a response that includes the key semantic information, such as "The intent is to book a flight, the destination is New York, and the timeframe is next week."
The researchers evaluate their Zero-shot Whisper SLU approach on several SLU benchmarks, including UniversalSLU and Zero-shot End-to-End Spoken Question Answering. They show that their method outperforms existing zero-shot and few-shot SLU techniques, demonstrating the effectiveness of leveraging Whisper's capabilities for zero-shot SLU.
Critical Analysis
The researchers have presented a novel and promising approach for zero-shot end-to-end spoken language understanding. By utilizing the powerful Whisper model and prompting it with natural language questions, they have effectively bypassed the need for task-specific training data, making their system highly versatile and applicable across a wide range of domains.
However, the paper does not address some potential limitations of their approach. For example, the performance of the system may be heavily dependent on the quality and appropriateness of the prompts used. Designing effective prompts that can extract the relevant semantic information from the speech input may require significant effort and domain expertise.
Additionally, the paper does not provide a detailed analysis of the system's performance on more complex or ambiguous speech inputs, where the semantic information may be less straightforward to extract. It would be valuable to see how the Zero-shot Whisper SLU approach handles more challenging scenarios and potential failure cases.
Overall, the researchers have made an important contribution to the field of spoken language understanding, and their work opens up new avenues for efficient compression of multitask, multilingual speech models and boosting prompting mechanisms for zero-shot applications. Further research and refinement of the approach could lead to even more robust and versatile spoken language understanding systems.
Conclusion
The paper presents a novel zero-shot end-to-end spoken language understanding approach that leverages the Whisper language model and natural language prompting. This Zero-shot Whisper SLU method demonstrates strong performance on several SLU benchmarks, showcasing its ability to extract semantic information from speech without any task-specific training data.
This research is an important step towards building more versatile and efficient spoken language understanding systems, which can have far-reaching applications in areas like universal spoken language understanding for diverse tasks, zero-shot end-to-end spoken question answering, and efficient compression of multitask, multilingual speech models. As the field continues to evolve, further advancements in boosting prompting mechanisms for zero-shot applications could unlock even more powerful and versatile spoken language understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
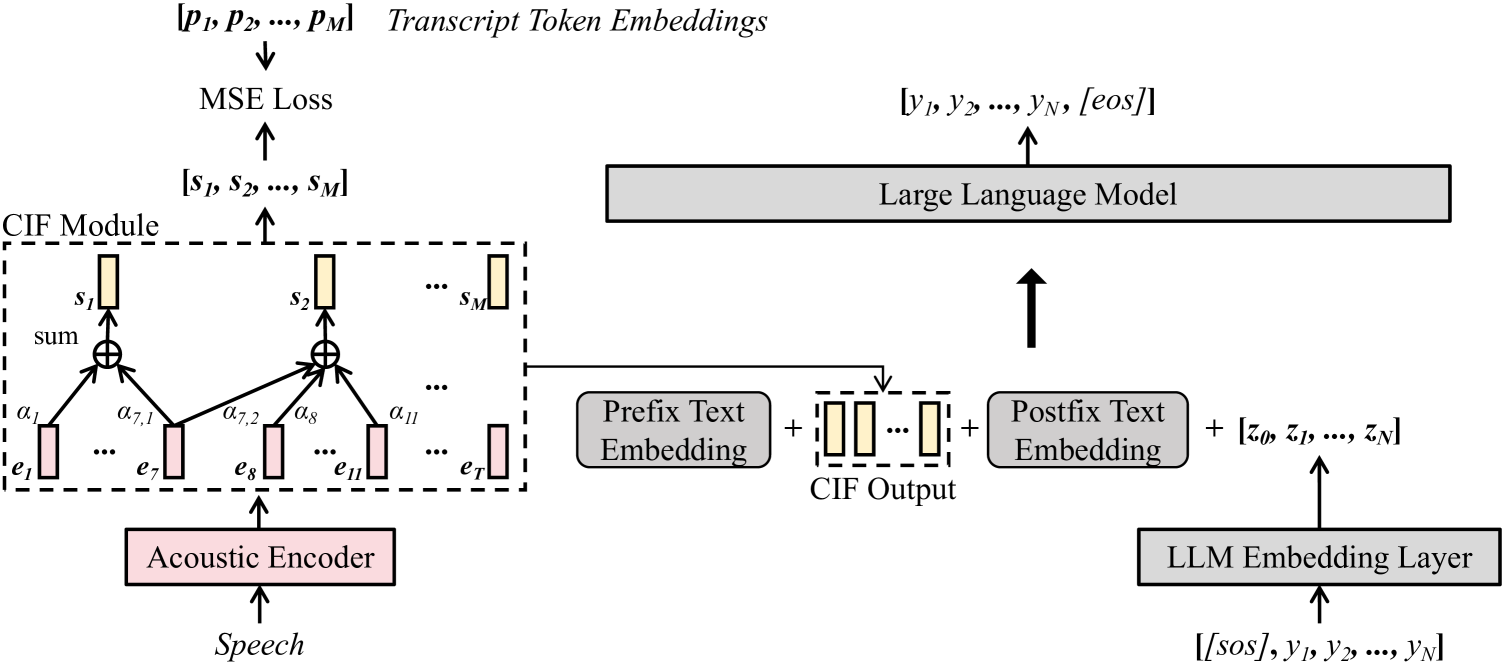
Wav2Prompt: End-to-End Speech Prompt Generation and Tuning For LLM in Zero and Few-shot Learning
Keqi Deng, Guangzhi Sun, Philip C. Woodland
0
0
Wav2Prompt is proposed which allows straightforward integration between spoken input and a text-based large language model (LLM). Wav2Prompt uses a simple training process with only the same data used to train an automatic speech recognition (ASR) model. After training, Wav2Prompt learns continuous representations from speech and uses them as LLM prompts. To avoid task over-fitting issues found in prior work and preserve the emergent abilities of LLMs, Wav2Prompt takes LLM token embeddings as the training targets and utilises a continuous integrate-and-fire mechanism for explicit speech-text alignment. Therefore, a Wav2Prompt-LLM combination can be applied to zero-shot spoken language tasks such as speech translation (ST), speech understanding (SLU), speech question answering (SQA) and spoken-query-based QA (SQQA). It is shown that for these zero-shot tasks, Wav2Prompt performs similarly to an ASR-LLM cascade and better than recent prior work. If relatively small amounts of task-specific paired data are available in few-shot scenarios, the Wav2Prompt-LLM combination can be end-to-end (E2E) fine-tuned. The Wav2Prompt-LLM combination then yields greatly improved results relative to an ASR-LLM cascade for the above tasks. For instance, for English-French ST with the BLOOMZ-7B1 LLM, a Wav2Prompt-LLM combination gave a 8.5 BLEU point increase over an ASR-LLM cascade.
6/4/2024
💬
UniverSLU: Universal Spoken Language Understanding for Diverse Tasks with Natural Language Instructions
Siddhant Arora, Hayato Futami, Jee-weon Jung, Yifan Peng, Roshan Sharma, Yosuke Kashiwagi, Emiru Tsunoo, Karen Livescu, Shinji Watanabe
0
0
Recent studies leverage large language models with multi-tasking capabilities, using natural language prompts to guide the model's behavior and surpassing performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly performs various spoken language understanding (SLU) tasks? We start by adapting a pre-trained automatic speech recognition model to additional tasks using single-token task specifiers. We enhance this approach through instruction tuning, i.e., finetuning by describing the task using natural language instructions followed by the list of label options. Our approach can generalize to new task descriptions for the seen tasks during inference, thereby enhancing its user-friendliness. We demonstrate the efficacy of our single multi-task learning model UniverSLU for 12 speech classification and sequence generation task types spanning 17 datasets and 9 languages. On most tasks, UniverSLU achieves competitive performance and often even surpasses task-specific models. Additionally, we assess the zero-shot capabilities, finding that the model generalizes to new datasets and languages for seen task types.
4/4/2024
Zero-Shot End-To-End Spoken Question Answering In Medical Domain
Yanis Labrak, Adel Moumen, Richard Dufour, Mickael Rouvier
0
0
In the rapidly evolving landscape of spoken question-answering (SQA), the integration of large language models (LLMs) has emerged as a transformative development. Conventional approaches often entail the use of separate models for question audio transcription and answer selection, resulting in significant resource utilization and error accumulation. To tackle these challenges, we explore the effectiveness of end-to-end (E2E) methodologies for SQA in the medical domain. Our study introduces a novel zero-shot SQA approach, compared to traditional cascade systems. Through a comprehensive evaluation conducted on a new open benchmark of 8 medical tasks and 48 hours of synthetic audio, we demonstrate that our approach requires up to 14.7 times fewer resources than a combined 1.3B parameters LLM with a 1.55B parameters ASR model while improving average accuracy by 0.5%. These findings underscore the potential of E2E methodologies for SQA in resource-constrained contexts.
6/11/2024
🗣️
Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao
0
0
Zero-shot text-to-speech (TTS) aims to synthesize voices with unseen speech prompts, which significantly reduces the data and computation requirements for voice cloning by skipping the fine-tuning process. However, the prompting mechanisms of zero-shot TTS still face challenges in the following aspects: 1) previous works of zero-shot TTS are typically trained with single-sentence prompts, which significantly restricts their performance when the data is relatively sufficient during the inference stage. 2) The prosodic information in prompts is highly coupled with timbre, making it untransferable to each other. This paper introduces Mega-TTS 2, a generic prompting mechanism for zero-shot TTS, to tackle the aforementioned challenges. Specifically, we design a powerful acoustic autoencoder that separately encodes the prosody and timbre information into the compressed latent space while providing high-quality reconstructions. Then, we propose a multi-reference timbre encoder and a prosody latent language model (P-LLM) to extract useful information from multi-sentence prompts. We further leverage the probabilities derived from multiple P-LLM outputs to produce transferable and controllable prosody. Experimental results demonstrate that Mega-TTS 2 could not only synthesize identity-preserving speech with a short prompt of an unseen speaker from arbitrary sources but consistently outperform the fine-tuning method when the volume of data ranges from 10 seconds to 5 minutes. Furthermore, our method enables to transfer various speaking styles to the target timbre in a fine-grained and controlled manner. Audio samples can be found in https://boostprompt.github.io/boostprompt/.
4/11/2024