Wav2Prompt: End-to-End Speech Prompt Generation and Tuning For LLM in Zero and Few-shot Learning

0
Sign in to get full access
Overview
- This paper, "Wav2Prompt: End-to-End Speech Prompt Generation and Tuning For LLM in Zero and Few-shot Learning," presents a novel approach for generating textual prompts from speech inputs to enable large language models (LLMs) to perform zero-shot and few-shot learning tasks.
- The proposed Wav2Prompt framework aims to bridge the gap between speech and language models, allowing users to leverage speech as an intuitive interface for interacting with LLMs.
- The system is designed to work in both zero-shot and few-shot learning scenarios, where the language model is required to perform tasks with limited or no training data.
Plain English Explanation
The paper introduces a system called Wav2Prompt that can take speech input and automatically generate a text prompt for a large language model (LLM) to use. This allows users to interact with LLMs using their voice, rather than having to type out prompts.
The key idea is that Wav2Prompt can "translate" speech into the kind of textual prompt that an LLM expects as input. This is useful in situations where the user doesn't have much training data to work with - the "zero-shot" and "few-shot" learning scenarios mentioned in the paper.
For example, imagine you wanted to use an LLM to summarize a document, but you only had a couple of examples to train the model on. Wav2Prompt could let you just speak your instructions, and it would generate the right prompt for the LLM to use. This makes it much easier to get an LLM to perform new tasks without needing lots of training data.
Technical Explanation
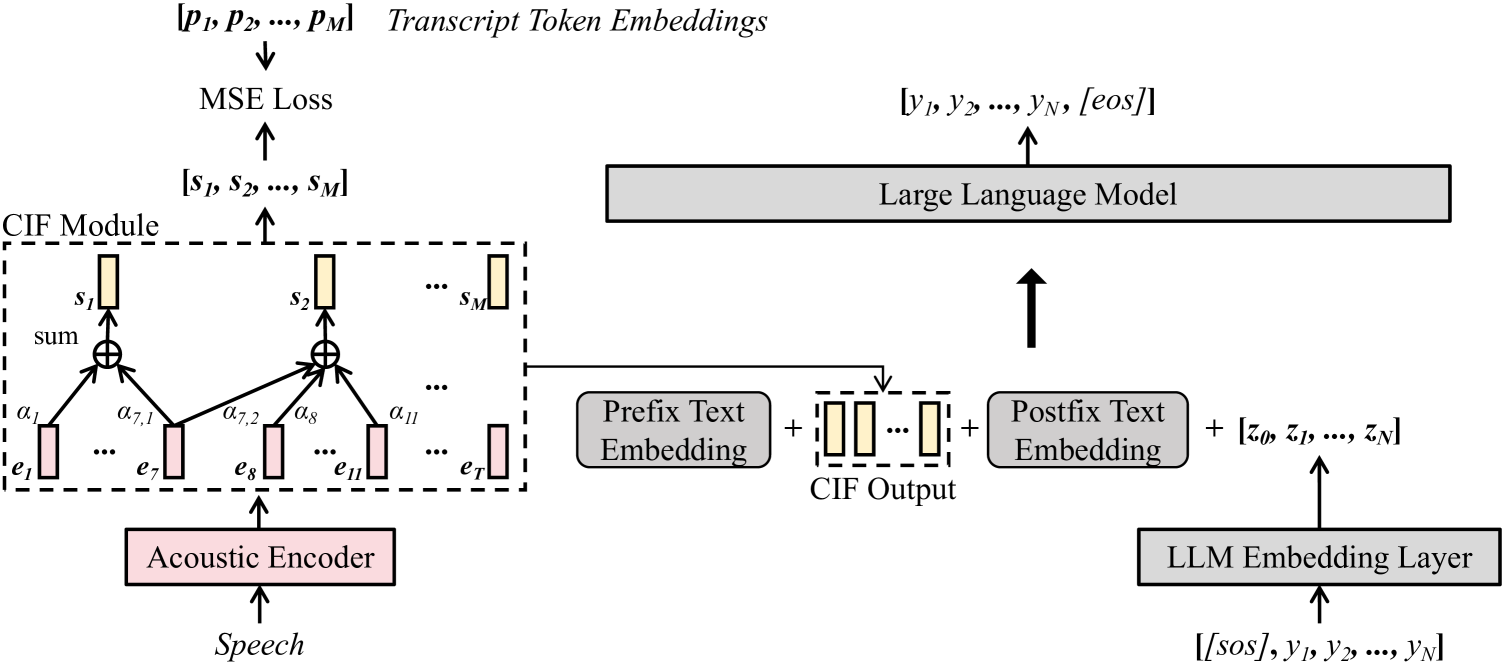
The Wav2Prompt framework consists of two main components:
-
A speech-to-text module that converts the input speech into text. This uses a pre-trained automatic speech recognition (ASR) model.
-
A prompt generation module that takes the text output from the ASR model and produces a prompt that can be used to fine-tune the target LLM for the desired task. This module is trained on a dataset of speech-prompt pairs.
The key innovation is that the prompt generation module is trained end-to-end, allowing it to learn the mapping between speech and the optimal prompts for different tasks, without requiring manual prompt engineering.
The paper evaluates Wav2Prompt on a range of zero-shot and few-shot learning tasks, including text summarization, question answering, and sentiment analysis. The results show that Wav2Prompt can effectively generate prompts that enable the LLM to perform these tasks, even with limited training data.
Critical Analysis
The paper presents a promising approach for integrating speech and language models, but there are some potential limitations and areas for further research:
- The performance of Wav2Prompt is still dependent on the quality of the underlying ASR and LLM models. Improvements in these foundational components could further enhance the end-to-end system.
- The paper focuses on relatively simple tasks like summarization and sentiment analysis. Extending Wav2Prompt to more complex, open-ended tasks may require additional architectural innovations or larger training datasets.
- The paper does not address potential biases or ethical concerns that could arise from using speech-based prompts to control LLMs. These issues will need to be carefully considered as the technology matures.
Despite these caveats, the Wav2Prompt framework represents an important step towards making large language models more accessible and intuitive to use, particularly in zero-shot and few-shot learning scenarios. As AI systems become more ubiquitous, bridging the gap between speech and language will be a critical capability.
Conclusion
The Wav2Prompt paper presents a novel approach for generating textual prompts from speech inputs, enabling users to leverage large language models through a more natural, voice-based interface. By automating the prompt engineering process, Wav2Prompt has the potential to make LLMs more accessible and usable, especially in situations where limited training data is available.
While the current system has some limitations, the underlying concept of seamlessly integrating speech and language models is a significant advancement that could have far-reaching implications for the future of human-AI interaction. As the field of language AI continues to evolve, techniques like Wav2Prompt will likely play an increasingly important role in making these powerful models more intuitive and user-friendly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Wav2Prompt: End-to-End Speech Prompt Generation and Tuning For LLM in Zero and Few-shot Learning
Keqi Deng, Guangzhi Sun, Philip C. Woodland
Wav2Prompt is proposed which allows straightforward integration between spoken input and a text-based large language model (LLM). Wav2Prompt uses a simple training process with only the same data used to train an automatic speech recognition (ASR) model. After training, Wav2Prompt learns continuous representations from speech and uses them as LLM prompts. To avoid task over-fitting issues found in prior work and preserve the emergent abilities of LLMs, Wav2Prompt takes LLM token embeddings as the training targets and utilises a continuous integrate-and-fire mechanism for explicit speech-text alignment. Therefore, a Wav2Prompt-LLM combination can be applied to zero-shot spoken language tasks such as speech translation (ST), speech understanding (SLU), speech question answering (SQA) and spoken-query-based QA (SQQA). It is shown that for these zero-shot tasks, Wav2Prompt performs similarly to an ASR-LLM cascade and better than recent prior work. If relatively small amounts of task-specific paired data are available in few-shot scenarios, the Wav2Prompt-LLM combination can be end-to-end (E2E) fine-tuned. The Wav2Prompt-LLM combination then yields greatly improved results relative to an ASR-LLM cascade for the above tasks. For instance, for English-French ST with the BLOOMZ-7B1 LLM, a Wav2Prompt-LLM combination gave a 8.5 BLEU point increase over an ASR-LLM cascade.
Read more6/4/2024

0
Prompting Whisper for QA-driven Zero-shot End-to-end Spoken Language Understanding
Mohan Li, Simon Keizer, Rama Doddipatla
Zero-shot spoken language understanding (SLU) enables systems to comprehend user utterances in new domains without prior exposure to training data. Recent studies often rely on large language models (LLMs), leading to excessive footprints and complexity. This paper proposes the use of Whisper, a standalone speech processing model, for zero-shot end-to-end (E2E) SLU. To handle unseen semantic labels, SLU tasks are integrated into a question-answering (QA) framework, which prompts the Whisper decoder for semantics deduction. The system is efficiently trained with prefix-tuning, optimising a minimal set of parameters rather than the entire Whisper model. We show that the proposed system achieves a 40.7% absolute gain for slot filling (SLU-F1) on SLURP compared to a recently introduced zero-shot benchmark. Furthermore, it performs comparably to a Whisper-GPT-2 modular system under both in-corpus and cross-corpus evaluation settings, but with a relative 34.8% reduction in model parameters.
Read more6/24/2024
🗣️
0
Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao
Zero-shot text-to-speech (TTS) aims to synthesize voices with unseen speech prompts, which significantly reduces the data and computation requirements for voice cloning by skipping the fine-tuning process. However, the prompting mechanisms of zero-shot TTS still face challenges in the following aspects: 1) previous works of zero-shot TTS are typically trained with single-sentence prompts, which significantly restricts their performance when the data is relatively sufficient during the inference stage. 2) The prosodic information in prompts is highly coupled with timbre, making it untransferable to each other. This paper introduces Mega-TTS 2, a generic prompting mechanism for zero-shot TTS, to tackle the aforementioned challenges. Specifically, we design a powerful acoustic autoencoder that separately encodes the prosody and timbre information into the compressed latent space while providing high-quality reconstructions. Then, we propose a multi-reference timbre encoder and a prosody latent language model (P-LLM) to extract useful information from multi-sentence prompts. We further leverage the probabilities derived from multiple P-LLM outputs to produce transferable and controllable prosody. Experimental results demonstrate that Mega-TTS 2 could not only synthesize identity-preserving speech with a short prompt of an unseen speaker from arbitrary sources but consistently outperform the fine-tuning method when the volume of data ranges from 10 seconds to 5 minutes. Furthermore, our method enables to transfer various speaking styles to the target timbre in a fine-grained and controlled manner. Audio samples can be found in https://boostprompt.github.io/boostprompt/.
Read more4/11/2024
0
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan Liu, Furu Wei
The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at url{aka.ms/wavllm}.
Read more9/24/2024