Protein Representation Learning with Sequence Information Embedding: Does it Always Lead to a Better Performance?

0

Sign in to get full access
Overview
- This paper explores the effectiveness of incorporating protein sequence information into deep learning models for protein representation learning.
- The researchers investigate whether this approach always leads to improved performance compared to models that do not use sequence information.
- The paper compares different protein representation learning methods, including those that capture protein sequence information and those that focus on protein structure.
Plain English Explanation
Proteins are complex molecules that play a crucial role in the functioning of living organisms. Understanding how proteins work and what they do is important for many areas of science, from biology to medicine. Researchers have developed various computational techniques to study and represent proteins, including deep learning models that can capture the structure and sequence of these molecules.
This paper examines whether incorporating information about the sequence of amino acids that make up a protein (its "sequence information") always leads to better performance in deep learning models for protein representation learning. The researchers compare models that use sequence information to those that focus solely on the three-dimensional structure of the protein.
The key idea is that while sequence information can provide valuable insights, it may not always be the most important factor in accurately representing and understanding a protein's behavior. In some cases, focusing on the protein's structure may be more important for certain tasks or applications.
Technical Explanation
The paper presents several experiments that compare different protein representation learning methods, including:
- Approaches that incorporate protein sequence information
- Methods that focus on learning from protein structure data
- Geometric self-supervised pretraining techniques for 3D protein structures
- Bi-level representation learning methods that combine sequence and structure information
The researchers evaluate the performance of these different approaches on a range of protein structure alignment and function prediction tasks. They find that while incorporating sequence information can sometimes improve performance, it does not always lead to the best results. In some cases, models that focus solely on protein structure outperform those that use both sequence and structure information.
Critical Analysis
The paper provides a nuanced view of the role of sequence information in protein representation learning. While sequence data can be valuable, the researchers demonstrate that it is not always the most important factor, and that focusing on structural information can be equally or more effective for certain tasks.
One potential limitation of the study is that it does not explore the interplay between sequence and structure in greater depth. It would be interesting to see how different ways of combining these two types of information, or how the relative importance of each, varies across different protein-related tasks and applications.
Additionally, the paper does not delve into the potential reasons why sequence information may not always be the most important factor. Further research could investigate the underlying mechanisms and factors that influence the relative importance of sequence versus structure in protein representation learning.
Conclusion
This paper challenges the assumption that incorporating protein sequence information is always the key to achieving the best performance in deep learning models for protein representation learning. The researchers demonstrate that in some cases, focusing on the three-dimensional structure of proteins can be more important than using sequence data.
The findings of this study have important implications for the development of more effective computational tools for studying and understanding proteins. By considering both sequence and structure information, and understanding their relative importance for different tasks, researchers can build more sophisticated and accurate models to support a wide range of applications, from drug discovery to evolutionary biology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Protein Representation Learning with Sequence Information Embedding: Does it Always Lead to a Better Performance?
Yang Tan, Lirong Zheng, Bozitao Zhong, Liang Hong, Bingxin Zhou
Deep learning has become a crucial tool in studying proteins. While the significance of modeling protein structure has been discussed extensively in the literature, amino acid types are typically included in the input as a default operation for many inference tasks. This study demonstrates with structure alignment task that embedding amino acid types in some cases may not help a deep learning model learn better representation. To this end, we propose ProtLOCA, a local geometry alignment method based solely on amino acid structure representation. The effectiveness of ProtLOCA is examined by a global structure-matching task on protein pairs with an independent test dataset based on CATH labels. Our method outperforms existing sequence- and structure-based representation learning methods by more quickly and accurately matching structurally consistent protein domains. Furthermore, in local structure pairing tasks, ProtLOCA for the first time provides a valid solution to highlight common local structures among proteins with different overall structures but the same function. This suggests a new possibility for using deep learning methods to analyze protein structure to infer function.
Read more7/1/2024
0
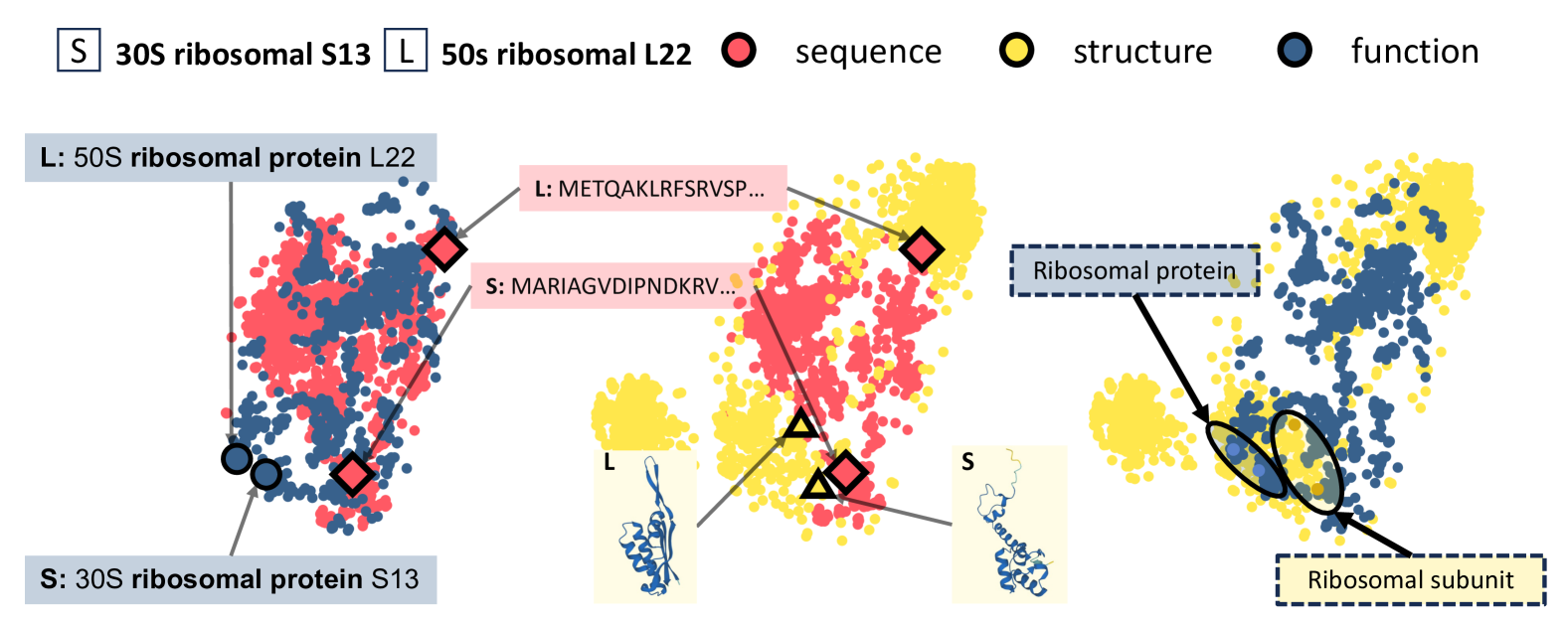
Protein Representation Learning by Capturing Protein Sequence-Structure-Function Relationship
Eunji Ko, Seul Lee, Minseon Kim, Dongki Kim
The goal of protein representation learning is to extract knowledge from protein databases that can be applied to various protein-related downstream tasks. Although protein sequence, structure, and function are the three key modalities for a comprehensive understanding of proteins, existing methods for protein representation learning have utilized only one or two of these modalities due to the difficulty of capturing the asymmetric interrelationships between them. To account for this asymmetry, we introduce our novel asymmetric multi-modal masked autoencoder (AMMA). AMMA adopts (1) a unified multi-modal encoder to integrate all three modalities into a unified representation space and (2) asymmetric decoders to ensure that sequence latent features reflect structural and functional information. The experiments demonstrate that the proposed AMMA is highly effective in learning protein representations that exhibit well-aligned inter-modal relationships, which in turn makes it effective for various downstream protein-related tasks.
Read more5/14/2024
0
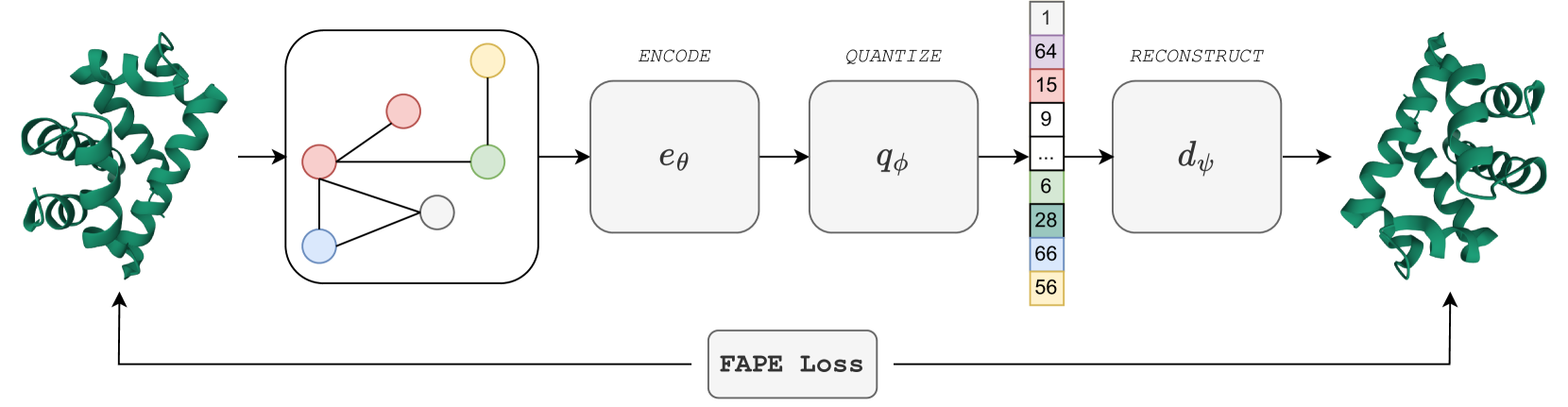
Learning the Language of Protein Structure
Benoit Gaujac, J'er'emie Don`a, Liviu Copoiu, Timothy Atkinson, Thomas Pierrot, Thomas D. Barrett
Representation learning and emph{de novo} generation of proteins are pivotal computational biology tasks. Whilst natural language processing (NLP) techniques have proven highly effective for protein sequence modelling, structure modelling presents a complex challenge, primarily due to its continuous and three-dimensional nature. Motivated by this discrepancy, we introduce an approach using a vector-quantized autoencoder that effectively tokenizes protein structures into discrete representations. This method transforms the continuous, complex space of protein structures into a manageable, discrete format with a codebook ranging from 4096 to 64000 tokens, achieving high-fidelity reconstructions with backbone root mean square deviations (RMSD) of approximately 1-5 AA. To demonstrate the efficacy of our learned representations, we show that a simple GPT model trained on our codebooks can generate novel, diverse, and designable protein structures. Our approach not only provides representations of protein structure, but also mitigates the challenges of disparate modal representations and sets a foundation for seamless, multi-modal integration, enhancing the capabilities of computational methods in protein design.
Read more5/28/2024

0
GOProteinGNN: Leveraging Protein Knowledge Graphs for Protein Representation Learning
Dan Kalifa, Uriel Singer, Kira Radinsky
Proteins play a vital role in biological processes and are indispensable for living organisms. Accurate representation of proteins is crucial, especially in drug development. Recently, there has been a notable increase in interest in utilizing machine learning and deep learning techniques for unsupervised learning of protein representations. However, these approaches often focus solely on the amino acid sequence of proteins and lack factual knowledge about proteins and their interactions, thus limiting their performance. In this study, we present GOProteinGNN, a novel architecture that enhances protein language models by integrating protein knowledge graph information during the creation of amino acid level representations. Our approach allows for the integration of information at both the individual amino acid level and the entire protein level, enabling a comprehensive and effective learning process through graph-based learning. By doing so, we can capture complex relationships and dependencies between proteins and their functional annotations, resulting in more robust and contextually enriched protein representations. Unlike previous fusion methods, GOProteinGNN uniquely learns the entire protein knowledge graph during training, which allows it to capture broader relational nuances and dependencies beyond mere triplets as done in previous work. We perform a comprehensive evaluation on several downstream tasks demonstrating that GOProteinGNN consistently outperforms previous methods, showcasing its effectiveness and establishing it as a state-of-the-art solution for protein representation learning.
Read more8/2/2024