Provable Imbalanced Point Clustering

0

Sign in to get full access
Overview
- This paper presents a provable clustering algorithm for imbalanced data points.
- The algorithm aims to efficiently cluster data points with varying densities and sizes.
- The authors provide theoretical guarantees on the clustering quality and runtime of their approach.
Plain English Explanation
The paper describes a new way to group data points together into clusters that works well even when the data is imbalanced - meaning some clusters are much larger or smaller than others.
Clustering is a common task in machine learning where you try to automatically find groups of similar data points. This can be challenging when the clusters have very different sizes, as the algorithm may struggle to identify the smaller clusters.
The approach presented in this paper aims to overcome this issue. It uses a mathematical technique called "provable imbalanced point clustering" to efficiently cluster the data, even when the clusters vary greatly in size. The authors prove that their algorithm can provide guarantees on the quality of the clusters it finds, as well as how long it takes to run.
This could be useful in real-world applications where data is often imbalanced, such as anomaly detection or customer segmentation. By being able to reliably cluster imbalanced data, the algorithm may lead to better insights and decisions.
Technical Explanation
The paper introduces a new algorithm for clustering imbalanced data points. The key idea is to formulate the clustering problem as an optimization task that aims to minimize a specific objective function.
This objective function takes into account both the distance between points within a cluster (to ensure clusters are compact) and the differences in cluster sizes (to handle imbalanced data). The authors prove that minimizing this objective function leads to high-quality clustering results, even when the data is highly imbalanced.
Importantly, the authors also provide theoretical guarantees on the runtime and approximation quality of their algorithm. Specifically, they show that their approach can find a near-optimal solution in polynomial time. This is a significant improvement over classic clustering methods, which may struggle to handle imbalanced data efficiently.
The paper includes experiments on both synthetic and real-world datasets that demonstrate the effectiveness of the proposed algorithm compared to existing methods. The results show that the new approach can reliably cluster imbalanced data while achieving better runtime performance.
Critical Analysis
The paper provides a strong theoretical foundation for its imbalanced clustering algorithm and backs up the claims with thorough experiments. The authors acknowledge some limitations, such as the need for the data to satisfy certain geometric assumptions for the provable guarantees to hold.
Additionally, the algorithm may be sensitive to the choice of hyperparameters, which could impact its practical performance. Further research could explore techniques to automatically tune these parameters or make the algorithm more robust to parameter selection.
It would also be interesting to see how the approach scales to truly massive datasets or high-dimensional feature spaces, as the runtime and memory requirements were only analyzed for the specific problem setting considered in the paper.
Overall, the paper presents a compelling and well-executed approach to a challenging problem in machine learning. The theoretical insights and empirical results suggest that the proposed algorithm could be a valuable tool for practitioners working with imbalanced data.
Conclusion
This paper introduces a new clustering algorithm designed to handle imbalanced data effectively. By formulating the problem as an optimization task with a carefully constructed objective function, the authors are able to provide strong theoretical guarantees on the clustering quality and runtime of their approach.
The experimental results demonstrate the algorithm's ability to reliably cluster datasets with varying cluster sizes, which could make it a useful tool in applications like anomaly detection, customer segmentation, and other areas where imbalanced data is common.
While the paper outlines some limitations and avenues for future work, the core ideas presented here represent an important contribution to the field of unsupervised learning. By addressing the challenges of imbalanced data clustering, this research could help unlock new insights and drive better decision-making across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Provable Imbalanced Point Clustering
David Denisov, Dan Feldman, Shlomi Dolev, Michael Segal
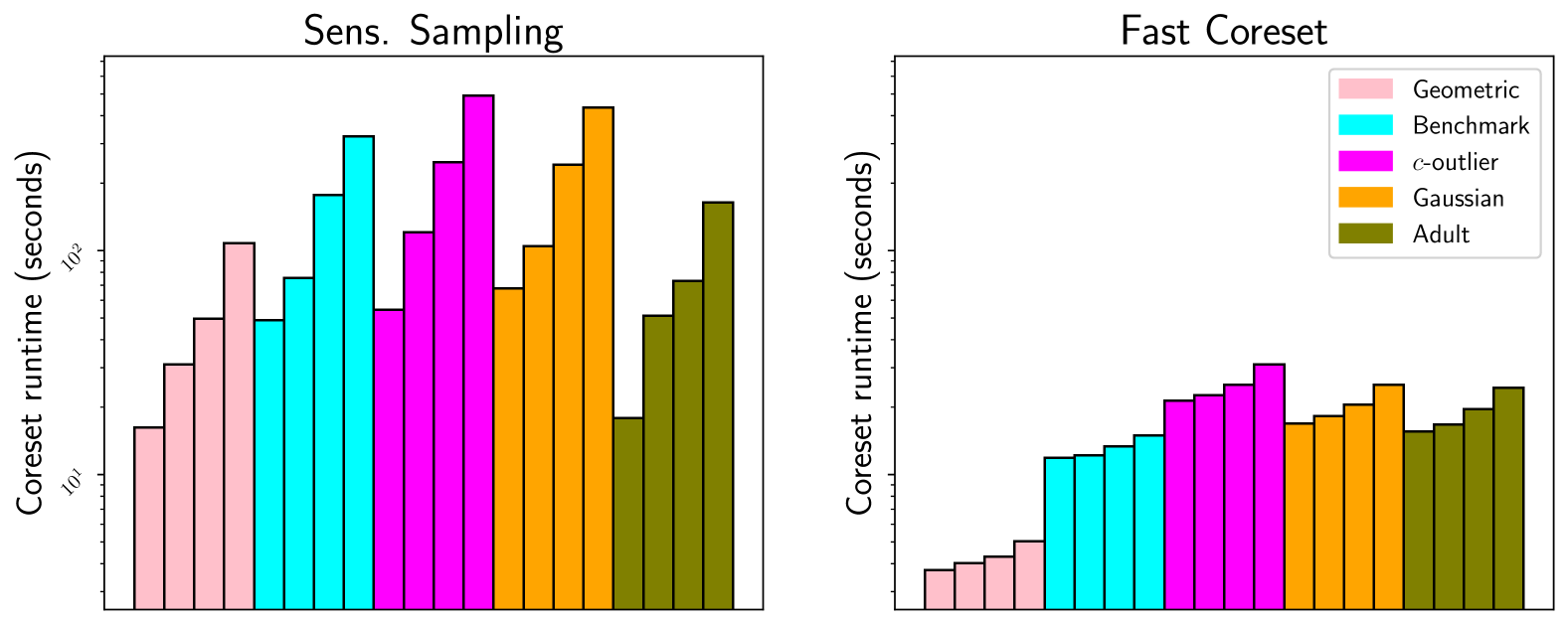
We suggest efficient and provable methods to compute an approximation for imbalanced point clustering, that is, fitting $k$-centers to a set of points in $mathbb{R}^d$, for any $d,kgeq 1$. To this end, we utilize emph{coresets}, which, in the context of the paper, are essentially weighted sets of points in $mathbb{R}^d$ that approximate the fitting loss for every model in a given set, up to a multiplicative factor of $1pmvarepsilon$. We provide [Section 3 and Section E in the appendix] experiments that show the empirical contribution of our suggested methods for real images (novel and reference), synthetic data, and real-world data. We also propose choice clustering, which by combining clustering algorithms yields better performance than each one separately.
Read more8/27/2024
0
Settling Time vs. Accuracy Tradeoffs for Clustering Big Data
Andrew Draganov, David Saulpic, Chris Schwiegelshohn
We study the theoretical and practical runtime limits of k-means and k-median clustering on large datasets. Since effectively all clustering methods are slower than the time it takes to read the dataset, the fastest approach is to quickly compress the data and perform the clustering on the compressed representation. Unfortunately, there is no universal best choice for compressing the number of points - while random sampling runs in sublinear time and coresets provide theoretical guarantees, the former does not enforce accuracy while the latter is too slow as the numbers of points and clusters grow. Indeed, it has been conjectured that any sensitivity-based coreset construction requires super-linear time in the dataset size. We examine this relationship by first showing that there does exist an algorithm that obtains coresets via sensitivity sampling in effectively linear time - within log-factors of the time it takes to read the data. Any approach that significantly improves on this must then resort to practical heuristics, leading us to consider the spectrum of sampling strategies across both real and artificial datasets in the static and streaming settings. Through this, we show the conditions in which coresets are necessary for preserving cluster validity as well as the settings in which faster, cruder sampling strategies are sufficient. As a result, we provide a comprehensive theoretical and practical blueprint for effective clustering regardless of data size. Our code is publicly available and has scripts to recreate the experiments.
Read more4/3/2024
🔗
0
New!Parameterized Approximation for Robust Clustering in Discrete Geometric Spaces
Fateme Abbasi, Sandip Banerjee, Jaros{l}aw Byrka, Parinya Chalermsook, Ameet Gadekar, Kamyar Khodamoradi, D'aniel Marx, Roohani Sharma, Joachim Spoerhase
We consider the well-studied Robust $(k, z)$-Clustering problem, which generalizes the classic $k$-Median, $k$-Means, and $k$-Center problems. Given a constant $zge 1$, the input to Robust $(k, z)$-Clustering is a set $P$ of $n$ weighted points in a metric space $(M,delta)$ and a positive integer $k$. Further, each point belongs to one (or more) of the $m$ many different groups $S_1,S_2,ldots,S_m$. Our goal is to find a set $X$ of $k$ centers such that $max_{i in [m]} sum_{p in S_i} w(p) delta(p,X)^z$ is minimized. This problem arises in the domains of robust optimization [Anthony, Goyal, Gupta, Nagarajan, Math. Oper. Res. 2010] and in algorithmic fairness. For polynomial time computation, an approximation factor of $O(log m/loglog m)$ is known [Makarychev, Vakilian, COLT $2021$], which is tight under a plausible complexity assumption even in the line metrics. For FPT time, there is a $(3^z+epsilon)$-approximation algorithm, which is tight under GAP-ETH [Goyal, Jaiswal, Inf. Proc. Letters, 2023]. Motivated by the tight lower bounds for general discrete metrics, we focus on emph{geometric} spaces such as the (discrete) high-dimensional Euclidean setting and metrics of low doubling dimension, which play an important role in data analysis applications. First, for a universal constant $eta_0 >0.0006$, we devise a $3^z(1-eta_{0})$-factor FPT approximation algorithm for discrete high-dimensional Euclidean spaces thereby bypassing the lower bound for general metrics. We complement this result by showing that even the special case of $k$-Center in dimension $Theta(log n)$ is $(sqrt{3/2}- o(1))$-hard to approximate for FPT algorithms. Finally, we complete the FPT approximation landscape by designing an FPT $(1+epsilon)$-approximation scheme (EPAS) for the metric of sub-logarithmic doubling dimension.
Read more9/17/2024
0
Robust Fair Clustering with Group Membership Uncertainty Sets
Sharmila Duppala, Juan Luque, John P. Dickerson, Seyed A. Esmaeili
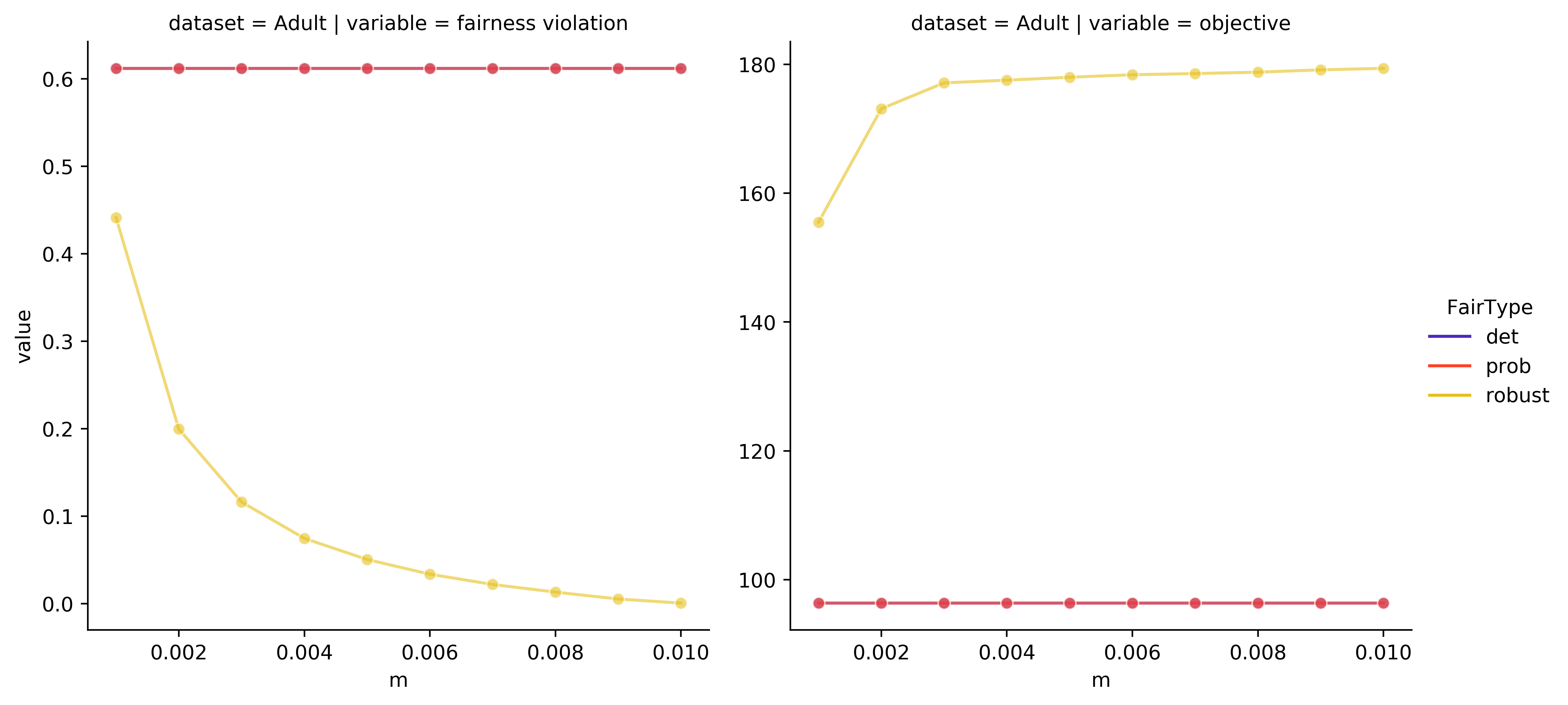
We study the canonical fair clustering problem where each cluster is constrained to have close to population-level representation of each group. Despite significant attention, the salient issue of having incomplete knowledge about the group membership of each point has been superficially addressed. In this paper, we consider a setting where errors exist in the assigned group memberships. We introduce a simple and interpretable family of error models that require a small number of parameters to be given by the decision maker. We then present an algorithm for fair clustering with provable robustness guarantees. Our framework enables the decision maker to trade off between the robustness and the clustering quality. Unlike previous work, our algorithms are backed by worst-case theoretical guarantees. Finally, we empirically verify the performance of our algorithm on real world datasets and show its superior performance over existing baselines.
Read more6/4/2024