Standard Gaussian Process Can Be Excellent for High-Dimensional Bayesian Optimization
2402.02746
0
0

Abstract
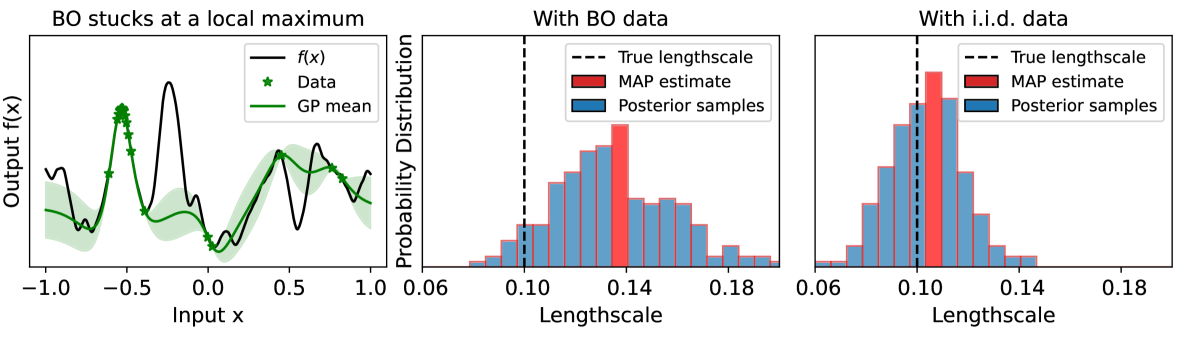
There has been a long-standing and widespread belief that Bayesian Optimization (BO) with standard Gaussian process (GP), referred to as standard BO, is ineffective in high-dimensional optimization problems. While this belief sounds reasonable, strong empirical evidence is lacking. In this paper, we systematically investigated BO with standard GP regression across a variety of synthetic and real-world benchmark problems for high-dimensional optimization. We found that, surprisingly, when using Mat'ern kernels and Upper Confidence Bound (UCB), standard BO consistently achieves top-tier performance, often outperforming other BO methods specifically designed for high-dimensional optimization. Contrary to the stereotype, we found that standard GP equipped with Mat'ern kernels can serve as a capable surrogate for learning high-dimensional functions. Without strong structural assumptions, BO with standard GP not only excels in high-dimensional optimization but also is robust in accommodating various structures within target functions. Furthermore, with standard GP, achieving promising optimization performance is possible via maximum a posterior (MAP) estimation with diffuse priors or merely maximum likelihood estimation, eliminating the need for expensive Markov-Chain Monte Carlo (MCMC) sampling that might be required by more complex surrogate models. In parallel, we also investigated and analyzed alternative popular settings in running standard BO, which, however, often fail in high-dimensional optimization. This might link to the a few failure cases reported in literature. We thus advocate for a re-evaluation and in-depth study of the potential of standard BO in addressing high-dimensional problems.
Create account to get full access
High Dimensional Bayesian Optimization
Overview
- Bayesian optimization is a powerful technique for optimizing expensive black-box functions, but it can struggle with high-dimensional problems.
- This paper proposes using a standard Gaussian process model for high-dimensional Bayesian optimization, challenging the conventional wisdom that specialized models are required.
- The authors demonstrate the effectiveness of this approach on a range of high-dimensional optimization tasks, outperforming more complex alternatives.
Plain English Explanation
Bayesian optimization is a way of finding the best settings for complex mathematical functions. These functions can be very expensive to evaluate, so Bayesian optimization tries to intelligently choose which settings to try in order to find the optimum quickly.
However, Bayesian optimization can become less effective as the number of settings (the "dimensionality") gets very large. The conventional thinking is that you need specialized, complex models to handle high-dimensional optimization problems.
This paper challenges that idea. The authors show that you can actually use a basic Gaussian process model - a relatively simple statistical tool - and still get great results on high-dimensional optimization tasks. They demonstrate this on a variety of problems, and find that their approach outperforms more sophisticated models.
The key insight is that the standard Gaussian process, when combined with the right acquisition function (a way of deciding which settings to try next), is powerful enough to handle high-dimensional optimization without needing complex bells and whistles. This is an important finding, as it means you can apply Bayesian optimization to a wider range of problems without having to develop specialized models.
Technical Explanation
The paper explores the use of standard Gaussian process models for high-dimensional Bayesian optimization. Bayesian optimization is a sample-efficient technique for optimizing expensive black-box functions, but it can struggle as the dimensionality of the problem increases.
Conventional wisdom suggests that specialized models, such as Variational Bayesian Surrogate Modeling or Stochastic Gradient Descent Gaussian Processes, are required to handle high-dimensional settings. However, the authors show that a standard Gaussian process model, combined with an appropriate acquisition function, can actually outperform these more complex approaches.
The key components of their approach are:
- Using a standard Gaussian process as the surrogate model.
- Employing the Upper Confidence Bound (UCB) acquisition function, which balances exploration and exploitation.
- Leveraging recent advances in Quadrature-based Batch Bayesian Optimization to efficiently handle the high-dimensional setting.
Through extensive experiments on a range of high-dimensional optimization tasks, the authors demonstrate the effectiveness of their proposed approach. They show that it can outperform more specialized models, such as Bayesian Neural Network Surrogates and Quantile Transformation Bayesian Optimization.
Critical Analysis
The authors make a compelling case for the use of standard Gaussian processes in high-dimensional Bayesian optimization. By challenging the conventional wisdom that specialized models are required, they have shown that simpler approaches can be surprisingly effective.
However, the paper does not explore the limitations of this technique. It would be valuable to understand the types of problems or scenarios where the standard Gaussian process may struggle, and how the performance might degrade as the dimensionality increases further.
Additionally, the authors do not compare their approach to other dimensionality reduction techniques that could potentially be combined with Bayesian optimization, such as active subspaces . Exploring these alternative strategies could provide a more comprehensive understanding of the tradeoffs involved.
Overall, the paper presents an important and practical contribution to the field of Bayesian optimization. By demonstrating the effectiveness of a straightforward approach, the authors have opened up new avenues for further research and real-world applications.
Conclusion
This paper challenges the conventional wisdom in Bayesian optimization by showing that a standard Gaussian process model can be highly effective for high-dimensional problems, outperforming more complex approaches. The key insights are that the standard Gaussian process, when combined with the right acquisition function, can handle high-dimensional settings without the need for specialized models.
This is an important finding, as it means researchers and practitioners can apply Bayesian optimization to a wider range of problems without having to develop complex custom solutions. The simplicity and effectiveness of the proposed approach could make Bayesian optimization more accessible and widely adopted, with potential applications in areas such as hyperparameter tuning, experimental design, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Provably Efficient Bayesian Optimization with Unbiased Gaussian Process Hyperparameter Estimation
Huong Ha, Vu Nguyen, Hung Tran-The, Hongyu Zhang, Xiuzhen Zhang, Anton van den Hengel
0
0
Gaussian process (GP) based Bayesian optimization (BO) is a powerful method for optimizing black-box functions efficiently. The practical performance and theoretical guarantees of this approach depend on having the correct GP hyperparameter values, which are usually unknown in advance and need to be estimated from the observed data. However, in practice, these estimations could be incorrect due to biased data sampling strategies used in BO. This can lead to degraded performance and break the sub-linear global convergence guarantee of BO. To address this issue, we propose a new BO method that can sub-linearly converge to the objective function's global optimum even when the true GP hyperparameters are unknown in advance and need to be estimated from the observed data. Our method uses a multi-armed bandit technique (EXP3) to add random data points to the BO process, and employs a novel training loss function for the GP hyperparameter estimation process that ensures consistent estimation. We further provide theoretical analysis of our proposed method. Finally, we demonstrate empirically that our method outperforms existing approaches on various synthetic and real-world problems.
6/7/2024
🛠️
Vanilla Bayesian Optimization Performs Great in High Dimensions
Carl Hvarfner, Erik Orm Hellsten, Luigi Nardi
0
0
High-dimensional problems have long been considered the Achilles' heel of Bayesian optimization algorithms. Spurred by the curse of dimensionality, a large collection of algorithms aim to make it more performant in this setting, commonly by imposing various simplifying assumptions on the objective. In this paper, we identify the degeneracies that make vanilla Bayesian optimization poorly suited to high-dimensional tasks, and further show how existing algorithms address these degeneracies through the lens of lowering the model complexity. Moreover, we propose an enhancement to the prior assumptions that are typical to vanilla Bayesian optimization algorithms, which reduces the complexity to manageable levels without imposing structural restrictions on the objective. Our modification - a simple scaling of the Gaussian process lengthscale prior with the dimensionality - reveals that standard Bayesian optimization works drastically better than previously thought in high dimensions, clearly outperforming existing state-of-the-art algorithms on multiple commonly considered real-world high-dimensional tasks.
6/27/2024
🛠️
Pseudo-Bayesian Optimization
Haoxian Chen, Henry Lam
0
0
Bayesian Optimization is a popular approach for optimizing expensive black-box functions. Its key idea is to use a surrogate model to approximate the objective and, importantly, quantify the associated uncertainty that allows a sequential search of query points that balance exploitation-exploration. Gaussian process (GP) has been a primary candidate for the surrogate model, thanks to its Bayesian-principled uncertainty quantification power and modeling flexibility. However, its challenges have also spurred an array of alternatives whose convergence properties could be more opaque. Motivated by these, we study in this paper an axiomatic framework that elicits the minimal requirements to guarantee black-box optimization convergence that could apply beyond GP-based methods. Moreover, we leverage the design freedom in our framework, which we call Pseudo-Bayesian Optimization, to construct empirically superior algorithms. In particular, we show how using simple local regression, and a suitable randomized prior construction to quantify uncertainty, not only guarantees convergence but also consistently outperforms state-of-the-art benchmarks in examples ranging from high-dimensional synthetic experiments to realistic hyperparameter tuning and robotic applications.
6/21/2024

Approximation-Aware Bayesian Optimization
Natalie Maus, Kyurae Kim, Geoff Pleiss, David Eriksson, John P. Cunningham, Jacob R. Gardner
0
0
High-dimensional Bayesian optimization (BO) tasks such as molecular design often require 10,000 function evaluations before obtaining meaningful results. While methods like sparse variational Gaussian processes (SVGPs) reduce computational requirements in these settings, the underlying approximations result in suboptimal data acquisitions that slow the progress of optimization. In this paper we modify SVGPs to better align with the goals of BO: targeting informed data acquisition rather than global posterior fidelity. Using the framework of utility-calibrated variational inference, we unify GP approximation and data acquisition into a joint optimization problem, thereby ensuring optimal decisions under a limited computational budget. Our approach can be used with any decision-theoretic acquisition function and is compatible with trust region methods like TuRBO. We derive efficient joint objectives for the expected improvement and knowledge gradient acquisition functions in both the standard and batch BO settings. Our approach outperforms standard SVGPs on high-dimensional benchmark tasks in control and molecular design.
6/7/2024