Prover-Verifier Games improve legibility of LLM outputs

37

Sign in to get full access
Overview
- The paper proposes a novel approach to improving the legibility and transparency of large language model (LLM) outputs using prover-verifier games.
- The key idea is to have the LLM engage in an interactive game with a verifier agent, where the LLM must prove the correctness of its outputs.
- This approach aims to enhance the interpretability and reliability of LLM-generated content, addressing concerns about the "black box" nature of these models.
Plain English Explanation
The research paper introduces a new way to make the outputs of large language models (LLMs) - the powerful AI systems that can generate human-like text - more understandable and trustworthy. LLMs can be powerful tools, but their inner workings are often opaque, like a "black box." This can make it difficult to know why they produce certain outputs or whether those outputs are accurate.
The researchers propose a solution: a game-like interaction between the LLM and a separate "verifier" agent. In this game, the LLM must demonstrate or "prove" that its outputs are correct. The verifier agent can challenge the LLM's claims and ask for further explanation or justification. By engaging in this back-and-forth, the LLM's reasoning becomes more transparent, and users can better understand and trust the model's outputs.
This approach aims to make LLM systems more interpretable and reliable, addressing a key concern about their use in high-stakes applications like medical diagnosis or legal decision-making. By requiring the LLM to justify its outputs, the researchers hope to reduce the risk of the model producing incorrect or misleading information.
Technical Explanation
The paper proposes a novel framework called "Prover-Verifier Games" to improve the legibility and transparency of LLM outputs. The core idea is to have the LLM engage in an interactive game-like process with a separate "verifier" agent.
In this game, the LLM acts as a "prover," attempting to demonstrate the correctness of its outputs. The verifier agent can then challenge the LLM's claims, asking for additional explanations or justifications. Through this back-and-forth interaction, the LLM's reasoning process becomes more transparent, allowing users to better understand and assess the model's outputs.
The authors describe several variants of the prover-verifier game, including:
- [Link: https://aimodels.fyi/papers/arxiv/graphreason-enhancing-reasoning-capabilities-large-language-models] Graph-based reasoning, where the LLM must explain its outputs using a structured knowledge graph.
- [Link: https://aimodels.fyi/papers/arxiv/stepwise-verification-remediation-student-reasoning-errors-large] Stepwise verification, where the LLM must break down its reasoning into a series of steps that can be verified independently.
- [Link: https://aimodels.fyi/papers/arxiv/general-purpose-verification-chain-thought-prompting] Chain-of-thought prompting, where the LLM must explicitly articulate its reasoning process.
- [Link: https://aimodels.fyi/papers/arxiv/theoremllama-transforming-general-purpose-llms-into-lean4] Transformation to theorem-proving systems, where the LLM is fine-tuned to behave more like a formal logical prover.
The authors evaluate the effectiveness of these prover-verifier game approaches through a series of experiments, demonstrating improvements in the legibility and reliability of LLM outputs.
Critical Analysis
The paper presents a promising approach to enhancing the interpretability and trustworthiness of LLM systems. By requiring the LLM to engage in a interactive verification process, the researchers aim to address a key limitation of these models - their "black box" nature.
However, the paper acknowledges several potential challenges and limitations of the prover-verifier game approach. For example, the additional computational overhead and interaction time required may limit the practical deployment of these systems, especially in time-sensitive applications.
Additionally, the effectiveness of the prover-verifier games may depend on the complexity of the LLM's reasoning and the capabilities of the verifier agent. Ensuring the verifier can accurately assess the LLM's justifications and detect potential flaws or inconsistencies is a critical challenge.
Further research is needed to explore the scalability of these approaches, as well as their generalizability to a broader range of LLM tasks and domains. Investigating the impact of prover-verifier games on end-user trust and decision-making would also be a valuable area of study.
Conclusion
The paper introduces a novel "prover-verifier game" framework to improve the legibility and transparency of LLM outputs. By requiring the LLM to engage in an interactive verification process, the researchers aim to enhance the interpretability and reliability of these powerful AI systems.
The proposed approaches, including graph-based reasoning, stepwise verification, and transformation to theorem-proving, demonstrate promising results in improving the legibility of LLM outputs. However, challenges remain in terms of scalability, practical deployment, and ensuring the verifier agent can accurately assess the LLM's justifications.
Overall, this research represents an important step towards addressing the "black box" nature of LLMs and building more trustworthy and explainable AI systems. As LLMs continue to be deployed in high-stakes applications, techniques like prover-verifier games may play a crucial role in ensuring the safety and reliability of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
37
Prover-Verifier Games improve legibility of LLM outputs
Jan Hendrik Kirchner, Yining Chen, Harri Edwards, Jan Leike, Nat McAleese, Yuri Burda
One way to increase confidence in the outputs of Large Language Models (LLMs) is to support them with reasoning that is clear and easy to check -- a property we call legibility. We study legibility in the context of solving grade-school math problems and show that optimizing chain-of-thought solutions only for answer correctness can make them less legible. To mitigate the loss in legibility, we propose a training algorithm inspired by Prover-Verifier Game from Anil et al. (2021). Our algorithm iteratively trains small verifiers to predict solution correctness, helpful provers to produce correct solutions that the verifier accepts, and sneaky provers to produce incorrect solutions that fool the verifier. We find that the helpful prover's accuracy and the verifier's robustness to adversarial attacks increase over the course of training. Furthermore, we show that legibility training transfers to time-constrained humans tasked with verifying solution correctness. Over course of LLM training human accuracy increases when checking the helpful prover's solutions, and decreases when checking the sneaky prover's solutions. Hence, training for checkability by small verifiers is a plausible technique for increasing output legibility. Our results suggest legibility training against small verifiers as a practical avenue for increasing legibility of large LLMs to humans, and thus could help with alignment of superhuman models.
Read more8/2/2024
💬
0
GraphReason: Enhancing Reasoning Capabilities of Large Language Models through A Graph-Based Verification Approach
Lang Cao
Large Language Models (LLMs) have showcased impressive reasoning capabilities, particularly when guided by specifically designed prompts in complex reasoning tasks such as math word problems. These models typically solve tasks using a chain-of-thought approach, which not only bolsters their reasoning abilities but also provides valuable insights into their problem-solving process. However, there is still significant room for enhancing the reasoning abilities of LLMs. Some studies suggest that the integration of an LLM output verifier can boost reasoning accuracy without necessitating additional model training. In this paper, we follow these studies and introduce a novel graph-based method to further augment the reasoning capabilities of LLMs. We posit that multiple solutions to a reasoning task, generated by an LLM, can be represented as a reasoning graph due to the logical connections between intermediate steps from different reasoning paths. Therefore, we propose the Reasoning Graph Verifier (GraphReason) to analyze and verify the solutions generated by LLMs. By evaluating these graphs, models can yield more accurate and reliable results.Our experimental results show that our graph-based verification method not only significantly enhances the reasoning abilities of LLMs but also outperforms existing verifier methods in terms of improving these models' reasoning performance.
Read more4/23/2024
0
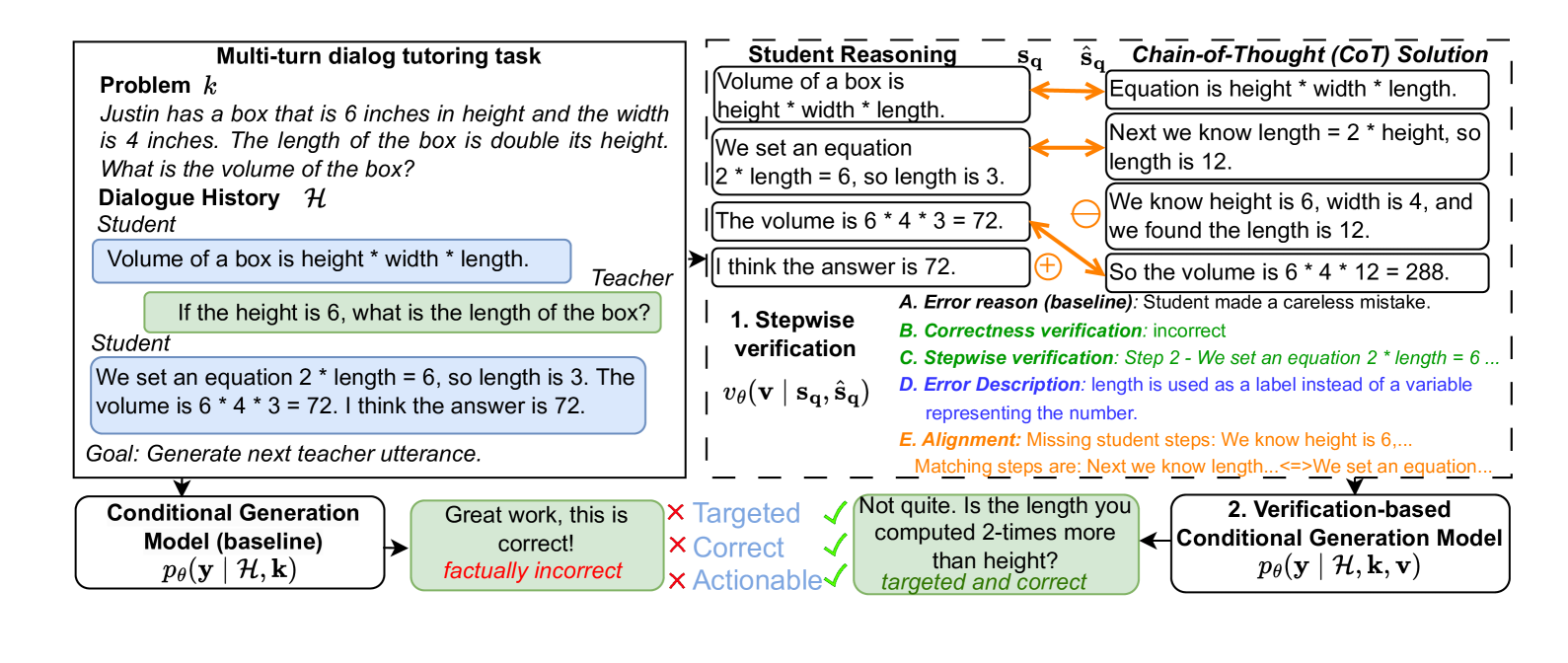
Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors
Nico Daheim, Jakub Macina, Manu Kapur, Iryna Gurevych, Mrinmaya Sachan
Large language models (LLMs) present an opportunity to scale high-quality personalized education to all. A promising approach towards this means is to build dialog tutoring models that scaffold students' problem-solving. However, even though existing LLMs perform well in solving reasoning questions, they struggle to precisely detect student's errors and tailor their feedback to these errors. Inspired by real-world teaching practice where teachers identify student errors and customize their response based on them, we focus on verifying student solutions and show how grounding to such verification improves the overall quality of tutor response generation. We collect a dataset of 1K stepwise math reasoning chains with the first error step annotated by teachers. We show empirically that finding the mistake in a student solution is challenging for current models. We propose and evaluate several verifiers for detecting these errors. Using both automatic and human evaluation we show that the student solution verifiers steer the generation model towards highly targeted responses to student errors which are more often correct with less hallucinations compared to existing baselines.
Read more7/15/2024

0
General Purpose Verification for Chain of Thought Prompting
Robert Vacareanu, Anurag Pratik, Evangelia Spiliopoulou, Zheng Qi, Giovanni Paolini, Neha Anna John, Jie Ma, Yassine Benajiba, Miguel Ballesteros
Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
Read more5/2/2024