GraphReason: Enhancing Reasoning Capabilities of Large Language Models through A Graph-Based Verification Approach
2308.09267
0
0
💬
Abstract
Large Language Models (LLMs) have showcased impressive reasoning capabilities, particularly when guided by specifically designed prompts in complex reasoning tasks such as math word problems. These models typically solve tasks using a chain-of-thought approach, which not only bolsters their reasoning abilities but also provides valuable insights into their problem-solving process. However, there is still significant room for enhancing the reasoning abilities of LLMs. Some studies suggest that the integration of an LLM output verifier can boost reasoning accuracy without necessitating additional model training. In this paper, we follow these studies and introduce a novel graph-based method to further augment the reasoning capabilities of LLMs. We posit that multiple solutions to a reasoning task, generated by an LLM, can be represented as a reasoning graph due to the logical connections between intermediate steps from different reasoning paths. Therefore, we propose the Reasoning Graph Verifier (GraphReason) to analyze and verify the solutions generated by LLMs. By evaluating these graphs, models can yield more accurate and reliable results.Our experimental results show that our graph-based verification method not only significantly enhances the reasoning abilities of LLMs but also outperforms existing verifier methods in terms of improving these models' reasoning performance.
Create account to get full access
Overview
- Large Language Models (LLMs) have shown impressive reasoning abilities, especially when guided by tailored prompts for complex tasks like math word problems.
- LLMs typically solve these tasks using a "chain-of-thought" approach, which enhances their reasoning and provides insights into their problem-solving process.
- However, there is still room to further improve the reasoning capabilities of LLMs.
- Some studies suggest that integrating an LLM output verifier can boost reasoning accuracy without additional model training.
- This paper introduces a novel graph-based method, called the Reasoning Graph Verifier (GraphReason), to augment the reasoning abilities of LLMs.
Plain English Explanation
Large language models (LLMs) are artificial intelligence systems that can understand and generate human-like text. Researchers have found that these models can excel at complex reasoning tasks, such as solving math word problems, when provided with carefully designed prompts.
The way LLMs solve these problems is by using a "chain-of-thought" approach, where they break down the problem into a series of logical steps and then work through them to arrive at the solution. This not only helps the models reason more effectively, but also provides valuable insights into how they are thinking through the problem.
However, despite these impressive capabilities, there is still room for improvement when it comes to the reasoning abilities of LLMs. Some studies have suggested that integrating a system to verify the output of the LLM can help boost the accuracy of its reasoning, without requiring the model to be retrained from scratch.
This paper introduces a new approach called the Reasoning Graph Verifier (GraphReason) that uses a graph-based method to analyze and validate the reasoning process of an LLM. The key idea is that the different solutions generated by an LLM for a given problem can be represented as a reasoning graph, where the logical connections between the intermediate steps are captured. By evaluating these reasoning graphs, the model can produce more accurate and reliable results.
Technical Explanation
The paper proposes a novel graph-based method, called the Reasoning Graph Verifier (GraphReason), to enhance the reasoning capabilities of large language models (LLMs). The core idea is to represent the multiple solutions generated by an LLM for a reasoning task as a reasoning graph, where the logical connections between the intermediate steps are captured.
The authors argue that this graph-based representation can provide valuable insights into the problem-solving process of the LLM, allowing for more accurate verification and validation of the generated solutions. Previous studies have shown that LLMs can struggle with certain types of structured reasoning tasks, and the authors believe that their graph-based approach can help address these limitations.
The experimental results presented in the paper demonstrate that the GraphReason method significantly enhances the reasoning performance of LLMs, outperforming existing verifier approaches. The authors suggest that this improvement is due to the ability of the graph-based representation to capture the logical structure of the reasoning process, which helps identify and correct errors or inconsistencies in the LLM's solutions.
Furthermore, the paper discusses the potential of the GraphReason approach to provide interpretable insights into the reasoning behavior of LLMs, which could be valuable for understanding and improving these models' capabilities. The authors also highlight the importance of evaluating interventional reasoning capabilities, in addition to accuracy, when assessing the reasoning performance of LLMs.
Critical Analysis
The paper presents a promising approach to enhancing the reasoning abilities of large language models (LLMs) using a graph-based verification method. The authors' focus on capturing the logical structure of the LLM's problem-solving process through the reasoning graph is a thoughtful and innovative approach.
One potential limitation of the study is the scope of the tasks and datasets used for evaluation. While the results demonstrate the effectiveness of the GraphReason method, it would be valuable to see how the approach performs on a broader range of reasoning tasks, including those that may require more complex or domain-specific knowledge.
Additionally, the paper does not provide a detailed analysis of the types of errors or inconsistencies that the GraphReason method is able to identify and correct in the LLM's solutions. A deeper exploration of these aspects could provide further insights into the model's reasoning behavior and the strengths and limitations of the proposed approach.
It would also be interesting to see how the GraphReason method compares to other recent efforts to improve the reasoning capabilities of LLMs, such as the integration of external knowledge sources or the use of specialized reasoning modules. Comparison to these approaches could help contextualize the contributions of this work and identify potential synergies or areas for further research.
Overall, the paper presents a well-designed and potentially impactful approach to enhancing the reasoning abilities of large language models. The authors' focus on interpretability and the evaluation of interventional reasoning capabilities is particularly commendable, as these aspects are crucial for developing more reliable and trustworthy AI systems.
Conclusion
This paper introduces a novel graph-based method, called the Reasoning Graph Verifier (GraphReason), to augment the reasoning capabilities of large language models (LLMs). By representing the multiple solutions generated by an LLM as a reasoning graph, the authors demonstrate that their approach can significantly improve the accuracy and reliability of the model's problem-solving performance.
The key contribution of this work is the insight that capturing the logical structure of the LLM's reasoning process through a graph-based representation can provide valuable insights and facilitate more effective verification of the generated solutions. This approach holds promise for addressing some of the limitations of LLMs in structured reasoning tasks and could pave the way for the development of more interpretable and trustworthy AI systems.
The findings presented in this paper suggest that the integration of graph-based verification methods, such as GraphReason, could be a fruitful direction for further enhancing the reasoning capabilities of large language models. As the field of AI continues to advance, the ability to build models that can engage in reliable and transparent reasoning will be of paramount importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
An Enhanced Prompt-Based LLM Reasoning Scheme via Knowledge Graph-Integrated Collaboration
Yihao Li, Ru Zhang, Jianyi Liu
0
0
While Large Language Models (LLMs) demonstrate exceptional performance in a multitude of Natural Language Processing (NLP) tasks, they encounter challenges in practical applications, including issues with hallucinations, inadequate knowledge updating, and limited transparency in the reasoning process. To overcome these limitations, this study innovatively proposes a collaborative training-free reasoning scheme involving tight cooperation between Knowledge Graph (KG) and LLMs. This scheme first involves using LLMs to iteratively explore KG, selectively retrieving a task-relevant knowledge subgraph to support reasoning. The LLMs are then guided to further combine inherent implicit knowledge to reason on the subgraph while explicitly elucidating the reasoning process. Through such a cooperative approach, our scheme achieves more reliable knowledge-based reasoning and facilitates the tracing of the reasoning results. Experimental results show that our scheme significantly progressed across multiple datasets, notably achieving over a 10% improvement on the QALD10 dataset compared to the best baseline and the fine-tuned state-of-the-art (SOTA) work. Building on this success, this study hopes to offer a valuable reference for future research in the fusion of KG and LLMs, thereby enhancing LLMs' proficiency in solving complex issues.
6/13/2024
💬
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
Bowen Jin, Chulin Xie, Jiawei Zhang, Kashob Kumar Roy, Yu Zhang, Suhang Wang, Yu Meng, Jiawei Han
0
0
Large language models (LLMs), while exhibiting exceptional performance, suffer from hallucinations, especially on knowledge-intensive tasks. Existing works propose to augment LLMs with individual text units retrieved from external knowledge corpora to alleviate the issue. However, in many domains, texts are interconnected (e.g., academic papers in a bibliographic graph are linked by citations and co-authorships) which form a (text-attributed) graph. The knowledge in such graphs is encoded not only in single texts/nodes but also in their associated connections. To facilitate the research of augmenting LLMs with graphs, we manually construct a Graph Reasoning Benchmark dataset called GRBench, containing 1,740 questions that can be answered with the knowledge from 10 domain graphs. Then, we propose a simple and effective framework called Graph Chain-of-thought (Graph-CoT) to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. Each Graph-CoT iteration consists of three sub-steps: LLM reasoning, LLM-graph interaction, and graph execution. We conduct systematic experiments with three LLM backbones on GRBench, where Graph-CoT outperforms the baselines consistently. The code is available at https://github.com/PeterGriffinJin/Graph-CoT.
4/11/2024
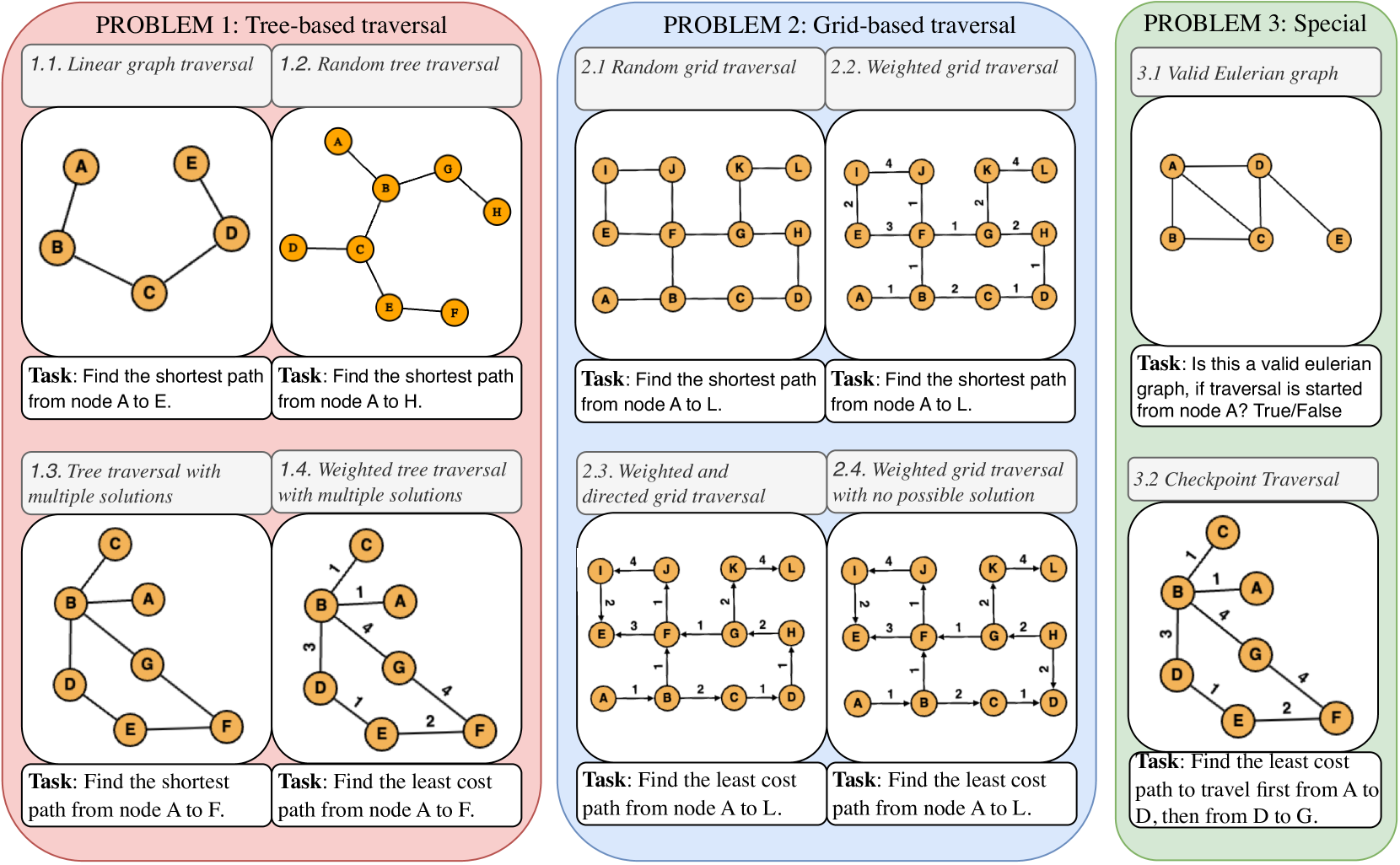
Can LLMs perform structured graph reasoning?
Palaash Agrawal, Shavak Vasania, Cheston Tan
0
0
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
4/19/2024

General Purpose Verification for Chain of Thought Prompting
Robert Vacareanu, Anurag Pratik, Evangelia Spiliopoulou, Zheng Qi, Giovanni Paolini, Neha Anna John, Jie Ma, Yassine Benajiba, Miguel Ballesteros
0
0
Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
5/2/2024