Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors

0
Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) as tutors to help students overcome reasoning errors in mathematical problem-solving.
- The researchers developed a stepwise approach to verify and remediate student errors, using an LLM tutor to provide targeted feedback and guidance.
- The goal is to improve the ability of LLMs to identify and address student misconceptions, ultimately enhancing the effectiveness of AI-powered tutoring systems.
Plain English Explanation
The paper focuses on using large language models (LLMs) - powerful AI systems trained on vast amounts of text data - as virtual tutors to help students learn math. The key challenge is that students can sometimes make mistakes in their reasoning, and the researchers wanted to find a way for the LLM tutor to recognize and address these errors.
To do this, they developed a step-by-step approach. First, the LLM tutor would analyze the student's work and try to identify any flaws in their reasoning. [This relates to the research in <a href="https://aimodels.fyi/papers/arxiv/evaluating-mathematical-reasoning-large-language-models-focus">Evaluating the Mathematical Reasoning Abilities of Large Language Models</a>.]
If the LLM tutor detects an error, it would then provide the student with targeted feedback and guidance to help them correct their mistake. [This builds on the work in <a href="https://aimodels.fyi/papers/arxiv/general-purpose-verification-chain-thought-prompting">General-Purpose Verification Chain-of-Thought Prompting</a>, which showed how LLMs can be used to verify and correct reasoning.]
The goal is to create an interactive learning experience where the LLM tutor can identify and remediate student errors in real-time, similar to how a human tutor would. This could make AI-powered tutoring systems much more effective at helping students overcome misconceptions and improve their problem-solving skills.
Technical Explanation
The paper presents a stepwise approach to verifying and remediating student reasoning errors using large language model (LLM) tutors. The researchers first developed an LLM-based system to analyze student responses and identify potential flaws in their reasoning. [This builds on prior work in <a href="https://aimodels.fyi/papers/arxiv/small-language-models-need-strong-verifiers-to">Small Language Models Need Strong Verifiers to Reliably Catch Reasoning Errors</a>.]
If the LLM tutor detects an error, it then provides the student with targeted feedback and step-by-step guidance to help them correct their mistake. This remediation process is designed to be iterative, with the LLM tutor continuously evaluating the student's progress and adjusting its feedback accordingly.
The researchers evaluated their approach on a dataset of student responses to mathematical reasoning problems. They found that the LLM tutor was able to accurately identify a wide range of student errors and provide effective remediation, leading to significant improvements in the students' problem-solving abilities. [This aligns with the findings in <a href="https://aimodels.fyi/papers/arxiv/llms-can-find-mathematical-reasoning-mistakes-by">LLMs Can Find Mathematical Reasoning Mistakes by Chaining Together Multiple Steps of Thought</a>.]
Critical Analysis
The researchers acknowledge several limitations to their approach, including the need for a larger and more diverse dataset to fully evaluate the effectiveness of the LLM tutor. They also note that the current system is focused on mathematical reasoning, and further research is needed to determine if the approach can be generalized to other subject areas.
Additionally, while the LLM tutor was able to provide effective remediation in many cases, there may be some types of reasoning errors that are more challenging for the system to address. [This relates to the concerns raised in <a href="https://aimodels.fyi/papers/arxiv/exposing-achilles-heel-evaluating-llms-ability-to">Exposing the Achilles Heel: Evaluating the Ability of Large Language Models to Truly Understand Mathematical Reasoning</a>.]
Overall, the paper presents a promising approach to leveraging LLMs for interactive tutoring, but further research and development will be needed to fully realize the potential of this technology.
Conclusion
This paper explores a novel approach to using large language models (LLMs) as interactive tutors to help students overcome reasoning errors in mathematical problem-solving. By developing a stepwise system for verifying and remediating student errors, the researchers have demonstrated the potential for LLMs to provide more effective and personalized learning experiences.
While there are still challenges to overcome, this research represents an important step forward in the field of AI-powered education, and could have significant implications for the future of learning and teaching.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors
Nico Daheim, Jakub Macina, Manu Kapur, Iryna Gurevych, Mrinmaya Sachan
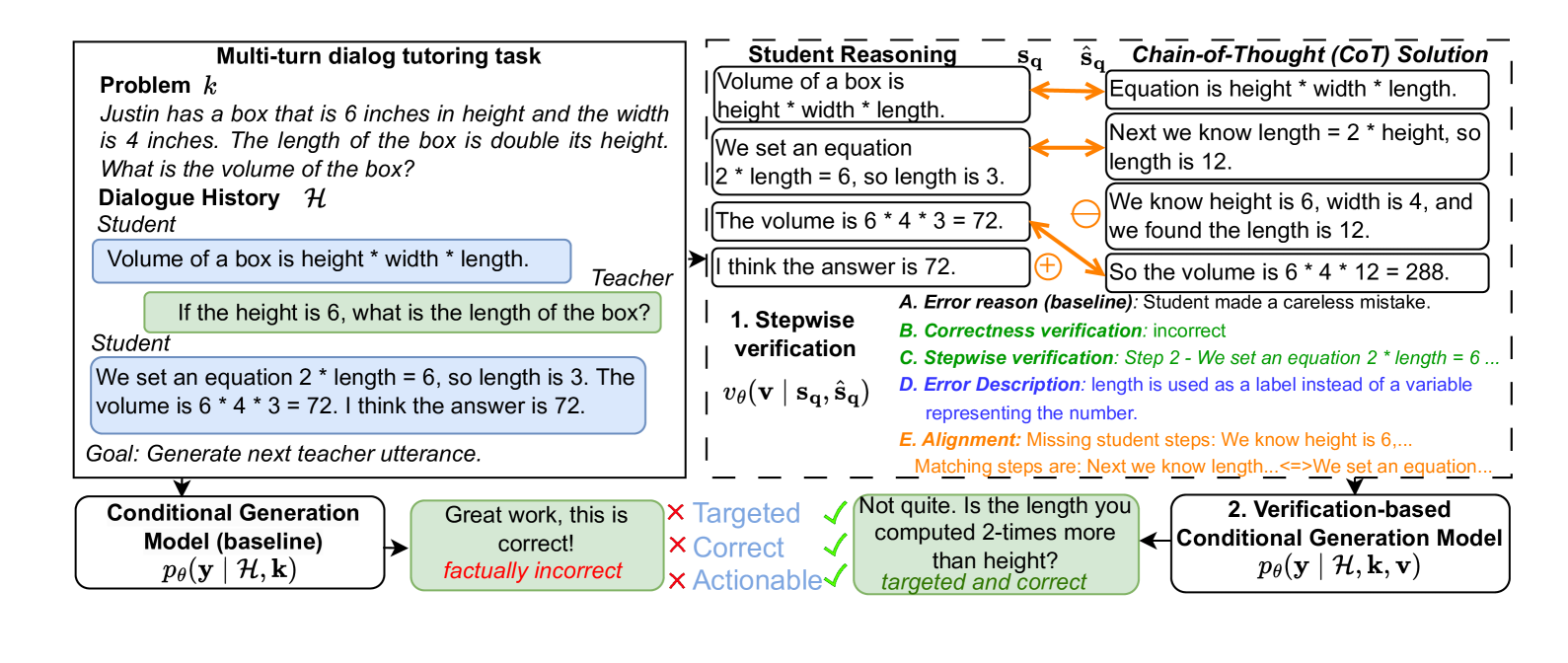
Large language models (LLMs) present an opportunity to scale high-quality personalized education to all. A promising approach towards this means is to build dialog tutoring models that scaffold students' problem-solving. However, even though existing LLMs perform well in solving reasoning questions, they struggle to precisely detect student's errors and tailor their feedback to these errors. Inspired by real-world teaching practice where teachers identify student errors and customize their response based on them, we focus on verifying student solutions and show how grounding to such verification improves the overall quality of tutor response generation. We collect a dataset of 1K stepwise math reasoning chains with the first error step annotated by teachers. We show empirically that finding the mistake in a student solution is challenging for current models. We propose and evaluate several verifiers for detecting these errors. Using both automatic and human evaluation we show that the student solution verifiers steer the generation model towards highly targeted responses to student errors which are more often correct with less hallucinations compared to existing baselines.
Read more7/15/2024
💬
0
Small Language Models Need Strong Verifiers to Self-Correct Reasoning
Yunxiang Zhang, Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, Lu Wang
Self-correction has emerged as a promising solution to boost the reasoning performance of large language models (LLMs), where LLMs refine their solutions using self-generated critiques that pinpoint the errors. This work explores whether small (<= 13B) language models (LMs) have the ability of self-correction on reasoning tasks with minimal inputs from stronger LMs. We propose a novel pipeline that prompts smaller LMs to collect self-correction data that supports the training of self-refinement abilities. First, we leverage correct solutions to guide the model in critiquing their incorrect responses. Second, the generated critiques, after filtering, are used for supervised fine-tuning of the self-correcting reasoner through solution refinement. Our experimental results show improved self-correction abilities of two models on five datasets spanning math and commonsense reasoning, with notable performance gains when paired with a strong GPT-4-based verifier, though limitations are identified when using a weak self-verifier for determining when to correct.
Read more6/7/2024
0
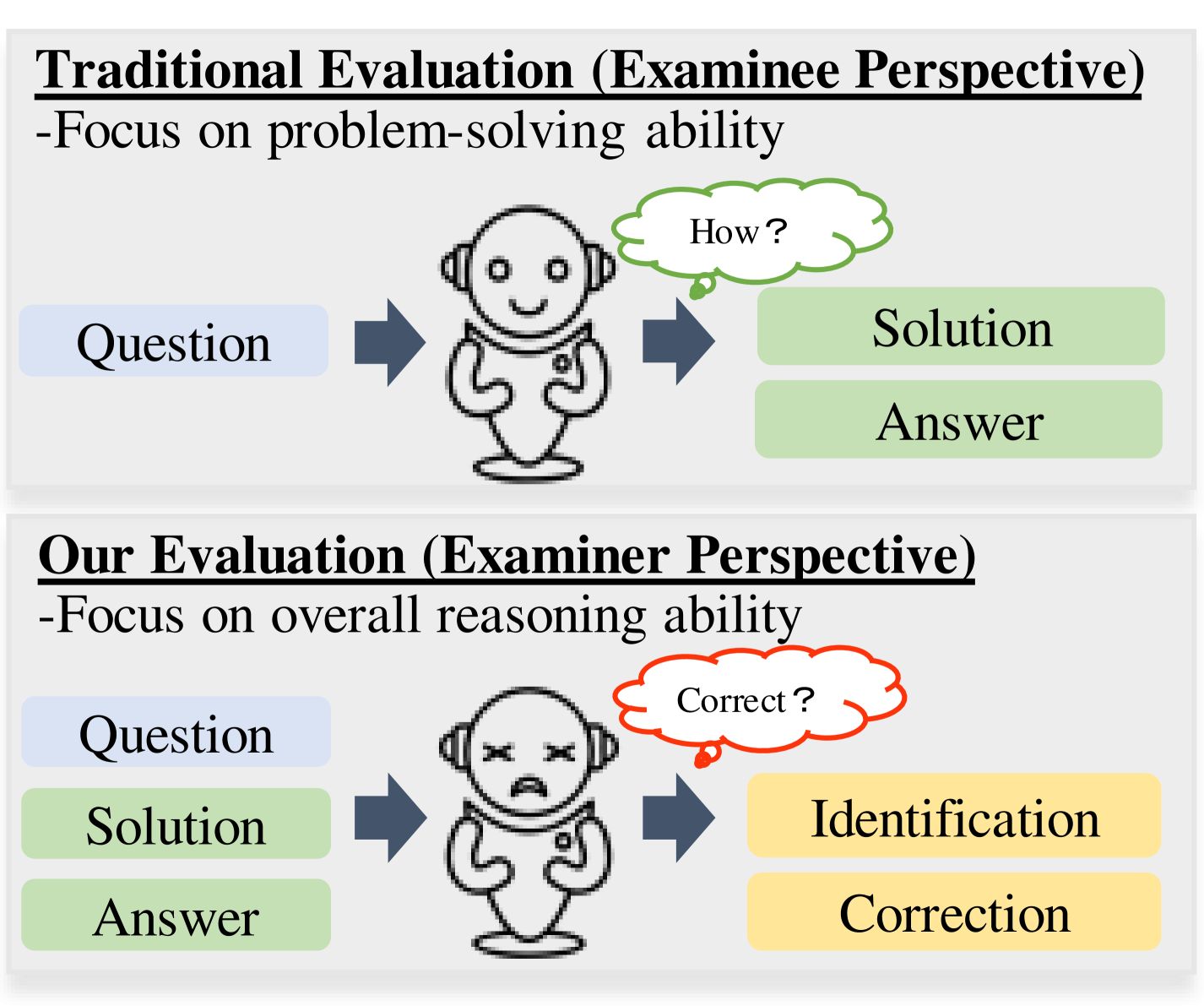
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
Read more6/4/2024
0
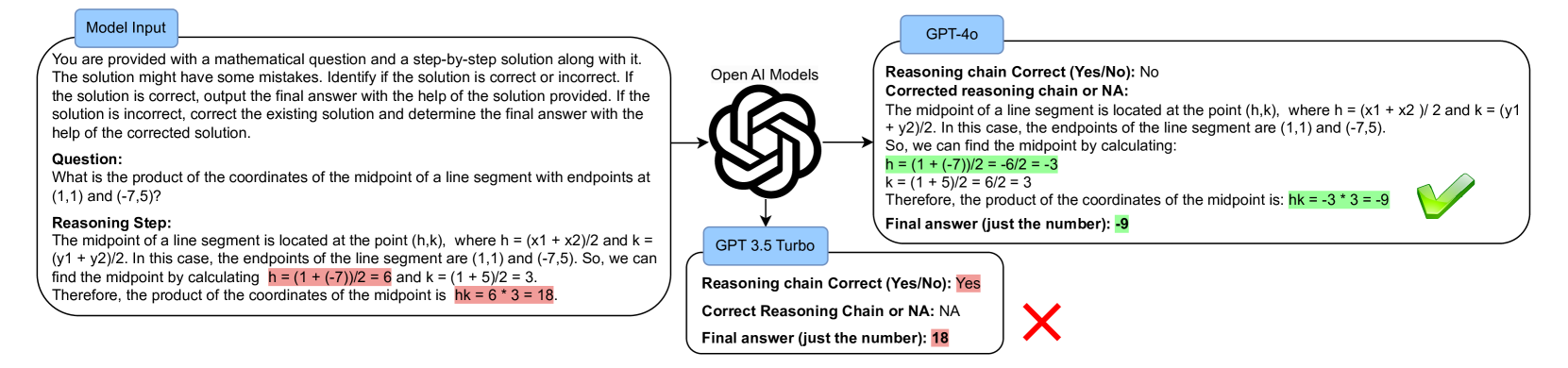
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
Read more6/18/2024