Proximal Policy Distillation

0

Sign in to get full access
Overview
- This paper introduces Proximal Policy Distillation (PPD), a novel technique for training a compact student policy from a larger teacher policy.
- PPD aims to distill the knowledge of a high-performing teacher policy into a smaller student policy, while retaining the teacher's performance.
- The method uses a proximal objective to encourage the student policy to remain close to the teacher's policy, enabling efficient knowledge transfer.
Plain English Explanation
Imagine you have a very skilled teacher who knows how to solve complex problems extremely well. However, their teaching methods are complex and difficult for students to learn. Proximal Policy Distillation is a way to take the knowledge from this expert teacher and transfer it to a simpler, more compact student policy.
The key idea is to use a "proximity" objective that encourages the student to stay close to the teacher's policy, while still allowing the student to learn and improve. This helps the student policy retain the essential knowledge and capabilities of the teacher, but in a more efficient and accessible form.
By distilling the teacher's expertise into a smaller student model, Proximal Policy Distillation can enable the use of powerful AI systems in resource-constrained settings, like running complex decision-making algorithms on low-power devices. It's a way to take advanced AI and make it more practical and widely applicable.
Technical Explanation
Proximal Policy Distillation is a technique for training a compact student policy from a larger, high-performing teacher policy. The method uses a proximal objective to encourage the student policy to remain close to the teacher's policy, enabling efficient knowledge transfer.
Specifically, the authors define a distillation objective that combines the student policy's own reward maximization with a penalty term that measures the divergence between the student and teacher policies. This proximal term encourages the student to mimic the teacher's behavior, while still allowing it to improve and find its own optimal policy.
The authors evaluate PPD on a range of challenging control tasks and demonstrate that the student policy is able to achieve performance comparable to the teacher, while being significantly more compact and efficient. This suggests that PPD is an effective technique for deploying powerful AI systems in resource-constrained settings.
Critical Analysis
The paper provides a thorough evaluation of Proximal Policy Distillation, testing it on a diverse set of environments and comparing to relevant baselines. The results show the method is effective at transferring knowledge from a teacher to a student policy while retaining the teacher's performance.
However, the paper does not extensively discuss potential limitations or caveats of the approach. For example, it is unclear how sensitive PPD is to the choice of hyperparameters or the specific architectural differences between the teacher and student models. Additionally, the paper does not explore how PPD might scale to extremely large or complex teacher-student pairs.
Further research could investigate these areas to better understand the strengths, weaknesses, and broader applicability of Proximal Policy Distillation. Nonetheless, the core idea of using a proximity-based objective for efficient policy distillation is a valuable contribution to the field of deep reinforcement learning.
Conclusion
Proximal Policy Distillation is a novel technique that enables the transfer of knowledge from a high-performing teacher policy to a more compact student policy. By using a proximal objective to encourage the student to stay close to the teacher's behavior, PPD can effectively distill the teacher's expertise into a smaller, more efficient model.
This method has significant practical implications, as it allows powerful AI systems to be deployed in resource-constrained settings where computational power and memory are limited. By compressing complex decision-making capabilities into a smaller form, Proximal Policy Distillation opens up new avenues for the real-world application of advanced reinforcement learning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Proximal Policy Distillation
Giacomo Spigler
We introduce Proximal Policy Distillation (PPD), a novel policy distillation method that integrates student-driven distillation and Proximal Policy Optimization (PPO) to increase sample efficiency and to leverage the additional rewards that the student policy collects during distillation. To assess the efficacy of our method, we compare PPD with two common alternatives, student-distill and teacher-distill, over a wide range of reinforcement learning environments that include discrete actions and continuous control (ATARI, Mujoco, and Procgen). For each environment and method, we perform distillation to a set of target student neural networks that are smaller, identical (self-distillation), or larger than the teacher network. Our findings indicate that PPD improves sample efficiency and produces better student policies compared to typical policy distillation approaches. Moreover, PPD demonstrates greater robustness than alternative methods when distilling policies from imperfect demonstrations. The code for the paper is released as part of a new Python library built on top of stable-baselines3 to facilitate policy distillation: `sb3-distill'.
Read more7/23/2024

0
Online Policy Distillation with Decision-Attention
Xinqiang Yu, Chuanguang Yang, Chengqing Yu, Libo Huang, Zhulin An, Yongjun Xu
Policy Distillation (PD) has become an effective method to improve deep reinforcement learning tasks. The core idea of PD is to distill policy knowledge from a teacher agent to a student agent. However, the teacher-student framework requires a well-trained teacher model which is computationally expensive.In the light of online knowledge distillation, we study the knowledge transfer between different policies that can learn diverse knowledge from the same environment.In this work, we propose Online Policy Distillation (OPD) with Decision-Attention (DA), an online learning framework in which different policies operate in the same environment to learn different perspectives of the environment and transfer knowledge to each other to obtain better performance together. With the absence of a well-performance teacher policy, the group-derived targets play a key role in transferring group knowledge to each student policy. However, naive aggregation functions tend to cause student policies quickly homogenize. To address the challenge, we introduce the Decision-Attention module to the online policies distillation framework. The Decision-Attention module can generate a distinct set of weights for each policy to measure the importance of group members. We use the Atari platform for experiments with various reinforcement learning algorithms, including PPO and DQN. In different tasks, our method can perform better than an independent training policy on both PPO and DQN algorithms. This suggests that our OPD-DA can transfer knowledge between different policies well and help agents obtain more rewards.
Read more6/11/2024
0
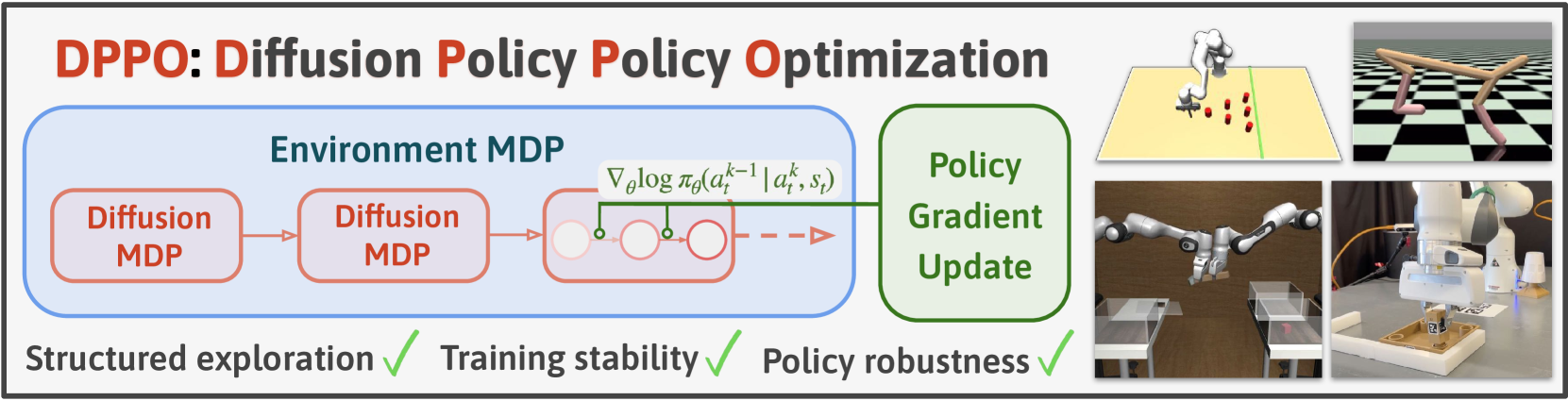
Diffusion Policy Policy Optimization
Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, Max Simchowitz
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
Read more9/4/2024
🏅
0
Enhancing Sample Efficiency and Exploration in Reinforcement Learning through the Integration of Diffusion Models and Proximal Policy Optimization
Gao Tianci, Dmitriev D. Dmitry, Konstantin A. Neusypin, Yang Bo, Rao Shengren
Recent advancements in reinforcement learning (RL) have been fueled by large-scale data and deep neural networks, particularly for high-dimensional and complex tasks. Online RL methods like Proximal Policy Optimization (PPO) are effective in dynamic scenarios but require substantial real-time data, posing challenges in resource-constrained or slow simulation environments. Offline RL addresses this by pre-learning policies from large datasets, though its success depends on the quality and diversity of the data. This work proposes a framework that enhances PPO algorithms by incorporating a diffusion model to generate high-quality virtual trajectories for offline datasets. This approach improves exploration and sample efficiency, leading to significant gains in cumulative rewards, convergence speed, and strategy stability in complex tasks. Our contributions are threefold: we explore the potential of diffusion models in RL, particularly for offline datasets, extend the application of online RL to offline environments, and experimentally validate the performance improvements of PPO with diffusion models. These findings provide new insights and methods for applying RL to high-dimensional, complex tasks. Finally, we open-source our code at https://github.com/TianciGao/DiffPPO
Read more9/17/2024