Online Policy Distillation with Decision-Attention

0

Sign in to get full access
Overview
• This paper presents a novel method called "Online Policy Distillation with Decision-Attention" for transferring knowledge from a complex policy model to a more efficient and interpretable student model.
• The approach uses attention-based decision-making to guide the distillation process, allowing the student model to focus on the most important aspects of the teacher's behavior.
• The method is evaluated on several reinforcement learning benchmarks and shows improved performance and interpretability compared to standard policy distillation techniques.
Plain English Explanation
In machine learning, there is often a trade-off between the complexity of a model and its efficiency and interpretability. Robust Preference Optimization Through Reward Model Distillation and Preferred Action Optimized Diffusion Policies for Offline Reinforcement Learning have explored ways to address this, but the authors of this paper have a new approach.
Their method, called "Online Policy Distillation with Decision-Attention," allows a complex, high-performing policy model (the "teacher") to transfer its knowledge to a simpler, more efficient model (the "student"). The key innovation is the use of "decision-attention," which helps the student model focus on the most important parts of the teacher's decision-making process.
This means the student model can capture the essential aspects of the teacher's behavior without needing to fully replicate its complexity. The authors show that this leads to improved performance and interpretability on several reinforcement learning tasks, compared to standard policy distillation techniques like Diffusion Policies: Creating Trust Region Offline Reinforcement Learning and Towards Scalable and Efficient Interaction-Aware Planning for Autonomous Driving.
Technical Explanation
The key idea behind "Online Policy Distillation with Decision-Attention" is to guide the knowledge distillation process by focusing the student model on the most important aspects of the teacher's decision-making. This is achieved through an attention mechanism that identifies the critical decision points and allocates more training resources to these areas.
The authors first train a complex policy model (the "teacher") using standard reinforcement learning techniques. They then train a simpler "student" model to mimic the teacher's behavior, but with the addition of a decision-attention module. This module learns to selectively attend to the relevant parts of the teacher's policy, allowing the student to capture the essential decision-making logic without needing to replicate the full complexity of the teacher.
The authors evaluate their approach on several reinforcement learning benchmarks, including Online Adaptation to Enhance Imitation Learning Policies, and show that it outperforms standard policy distillation techniques in terms of both performance and interpretability.
Critical Analysis
The authors provide a thorough evaluation of their method and highlight several important limitations and areas for future research. One key limitation is that the decision-attention mechanism is trained in an unsupervised manner, which means it may not always focus on the most meaningful aspects of the teacher's policy. The authors suggest that incorporating additional supervision or guidance could help address this issue.
Additionally, the authors note that their approach may be sensitive to the specific choice of teacher model and hyperparameters, and that further work is needed to understand the robustness of the method across a wider range of settings.
Despite these limitations, the core idea of using attention-based decision-making to guide policy distillation is a promising direction for improving the interpretability and efficiency of complex machine learning models. The authors' work represents an important step in this direction and could inspire further research in this area.
Conclusion
The "Online Policy Distillation with Decision-Attention" method presented in this paper offers a new approach to transferring knowledge from a complex policy model to a more efficient and interpretable student model. By incorporating an attention-based mechanism that focuses the student on the most important aspects of the teacher's decision-making, the authors demonstrate improved performance and interpretability on several reinforcement learning benchmarks.
This work contributes to the broader effort to develop more transparent and efficient AI systems, which is crucial for building trust and ensuring the responsible deployment of these technologies. While the method has some limitations, the authors' innovative use of attention-based decision-making is an exciting development in the field of knowledge distillation and could inspire further advancements in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Online Policy Distillation with Decision-Attention
Xinqiang Yu, Chuanguang Yang, Chengqing Yu, Libo Huang, Zhulin An, Yongjun Xu
Policy Distillation (PD) has become an effective method to improve deep reinforcement learning tasks. The core idea of PD is to distill policy knowledge from a teacher agent to a student agent. However, the teacher-student framework requires a well-trained teacher model which is computationally expensive.In the light of online knowledge distillation, we study the knowledge transfer between different policies that can learn diverse knowledge from the same environment.In this work, we propose Online Policy Distillation (OPD) with Decision-Attention (DA), an online learning framework in which different policies operate in the same environment to learn different perspectives of the environment and transfer knowledge to each other to obtain better performance together. With the absence of a well-performance teacher policy, the group-derived targets play a key role in transferring group knowledge to each student policy. However, naive aggregation functions tend to cause student policies quickly homogenize. To address the challenge, we introduce the Decision-Attention module to the online policies distillation framework. The Decision-Attention module can generate a distinct set of weights for each policy to measure the importance of group members. We use the Atari platform for experiments with various reinforcement learning algorithms, including PPO and DQN. In different tasks, our method can perform better than an independent training policy on both PPO and DQN algorithms. This suggests that our OPD-DA can transfer knowledge between different policies well and help agents obtain more rewards.
Read more6/11/2024

0
Proximal Policy Distillation
Giacomo Spigler
We introduce Proximal Policy Distillation (PPD), a novel policy distillation method that integrates student-driven distillation and Proximal Policy Optimization (PPO) to increase sample efficiency and to leverage the additional rewards that the student policy collects during distillation. To assess the efficacy of our method, we compare PPD with two common alternatives, student-distill and teacher-distill, over a wide range of reinforcement learning environments that include discrete actions and continuous control (ATARI, Mujoco, and Procgen). For each environment and method, we perform distillation to a set of target student neural networks that are smaller, identical (self-distillation), or larger than the teacher network. Our findings indicate that PPD improves sample efficiency and produces better student policies compared to typical policy distillation approaches. Moreover, PPD demonstrates greater robustness than alternative methods when distilling policies from imperfect demonstrations. The code for the paper is released as part of a new Python library built on top of stable-baselines3 to facilitate policy distillation: `sb3-distill'.
Read more7/23/2024
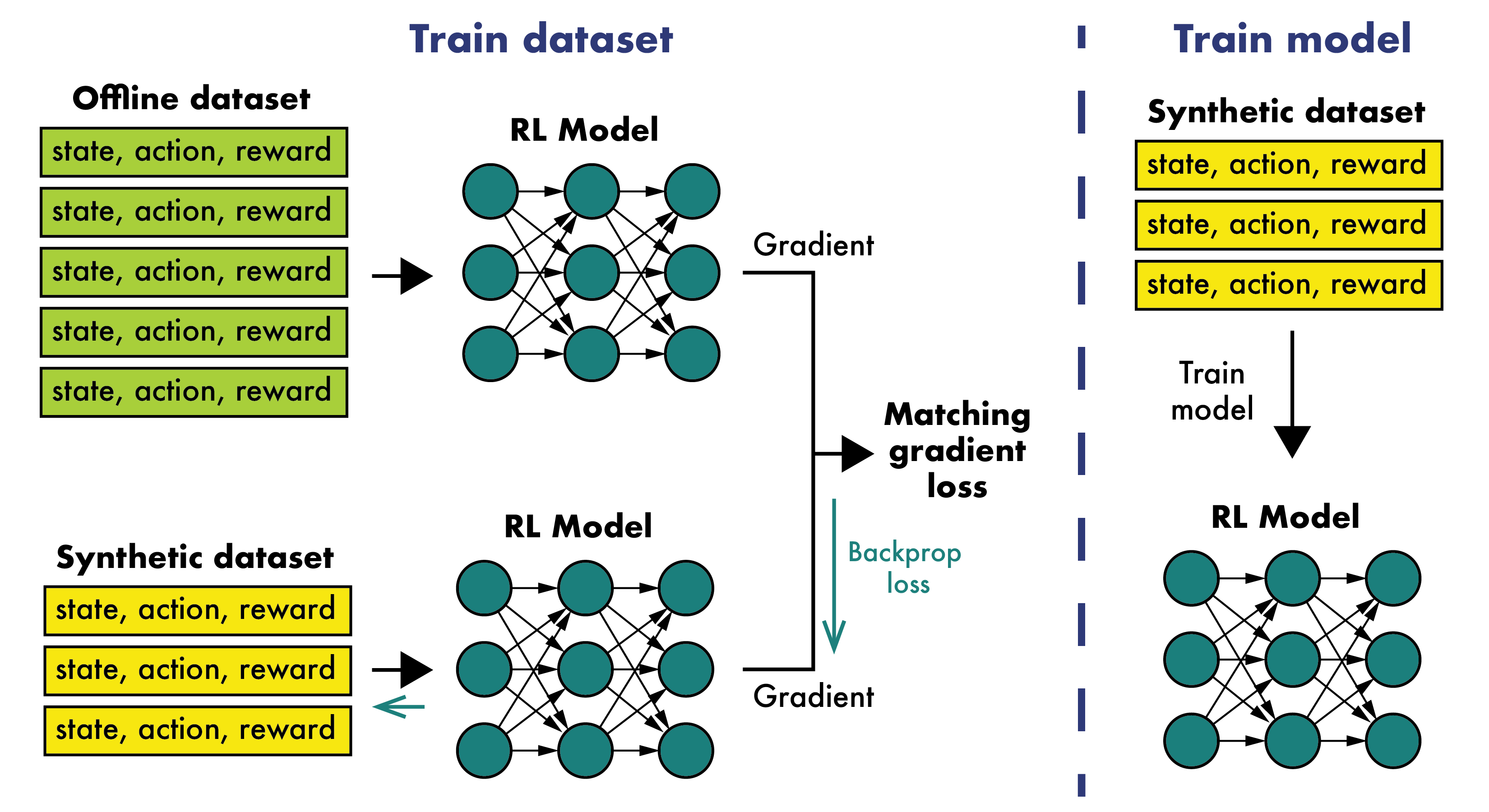
0
Dataset Distillation for Offline Reinforcement Learning
Jonathan Light, Yuanzhe Liu, Ziniu Hu
Offline reinforcement learning often requires a quality dataset that we can train a policy on. However, in many situations, it is not possible to get such a dataset, nor is it easy to train a policy to perform well in the actual environment given the offline data. We propose using data distillation to train and distill a better dataset which can then be used for training a better policy model. We show that our method is able to synthesize a dataset where a model trained on it achieves similar performance to a model trained on the full dataset or a model trained using percentile behavioral cloning. Our project site is available at $href{https://datasetdistillation4rl.github.io}{text{here}}$. We also provide our implementation at $href{https://github.com/ggflow123/DDRL}{text{this GitHub repository}}$.
Read more8/2/2024

0
Exploring and Enhancing the Transfer of Distribution in Knowledge Distillation for Autoregressive Language Models
Jun Rao, Xuebo Liu, Zepeng Lin, Liang Ding, Jing Li, Dacheng Tao, Min Zhang
Knowledge distillation (KD) is a technique that compresses large teacher models by training smaller student models to mimic them. The success of KD in auto-regressive language models mainly relies on Reverse KL for mode-seeking and student-generated output (SGO) to combat exposure bias. Our theoretical analyses and experimental validation reveal that while Reverse KL effectively mimics certain features of the teacher distribution, it fails to capture most of its behaviors. Conversely, SGO incurs higher computational costs and presents challenges in optimization, particularly when the student model is significantly smaller than the teacher model. These constraints are primarily due to the immutable distribution of the teacher model, which fails to adjust adaptively to models of varying sizes. We introduce Online Knowledge Distillation (OKD), where the teacher network integrates small online modules to concurrently train with the student model. This strategy abolishes the necessity for on-policy sampling and merely requires minimal updates to the parameters of the teacher's online module during training, thereby allowing dynamic adaptation to the student's distribution to make distillation better. Extensive results across multiple generation datasets show that OKD achieves or exceeds the performance of leading methods in various model architectures and sizes, reducing training time by up to fourfold.
Read more9/23/2024