Proximal Ranking Policy Optimization for Practical Safety in Counterfactual Learning to Rank

0

Sign in to get full access
Overview
- Explains a new technique called "Proximal Ranking Policy Optimization" for safely optimizing ranking policies in counterfactual Learning to Rank (LTR) systems.
- Addresses key challenges in applying counterfactual LTR in practice, such as potential reward hacking, unintended behavior, and lack of safety guarantees.
- Proposes a practical approach that provides robust safety guarantees while still optimizing ranking performance.
Plain English Explanation
Ranking algorithms are used extensively online to present the most relevant content to users, such as search results or product recommendations. Counterfactual Learning to Rank (LTR) is a powerful technique that can optimize these ranking algorithms using historical data about user interactions.
However, directly optimizing ranking policies using counterfactual LTR can be risky in practice. The algorithm may learn to "game the system" and optimize for metrics that don't actually benefit users, or it could exhibit other unintended and unsafe behaviors. This paper introduces a new technique called "Proximal Ranking Policy Optimization" that addresses these safety concerns.
The key idea is to constrain the ranking policy updates to stay close to the current policy, rather than making large changes. This provides robust safety guarantees - the updated policy will behave similarly to the current one, avoiding potential reward hacking or unintended consequences. At the same time, the technique still allows the policy to be optimized for improved ranking performance over time.
By combining the power of counterfactual LTR with strong safety protections, this method enables practical deployment of advanced ranking systems that benefit both businesses and their users.
Technical Explanation
The paper proposes a Proximal Ranking Policy Optimization (PRPO) algorithm for safe counterfactual LTR. PRPO builds on Proximal Policy Optimization, a reinforcement learning technique that constrains policy updates to stay close to the current policy.
The key contributions are:
-
Counterfactual LTR Formulation: The paper formalizes counterfactual LTR as a reinforcement learning problem, with the ranking policy as the agent and the user feedback/engagement as the reward signal.
-
Proximal Ranking Policy Optimization: PRPO optimizes the ranking policy by maximizing a lower bound on the expected counterfactual reward, with an additional constraint that limits the distance between the updated and current policies. This provides robust safety guarantees.
-
Practical Adoption: The authors demonstrate the effectiveness of PRPO on real-world datasets, showing that it can optimize ranking performance while maintaining safety and avoiding unintended behaviors.
The experiments compare PRPO to baseline counterfactual LTR techniques, as well as a "naive" approach that directly optimizes the ranking policy without safety constraints. The results indicate that PRPO achieves superior ranking performance while ensuring practical safety for real-world deployment.
Critical Analysis
The paper presents a compelling solution to an important practical challenge in deploying advanced ranking systems. By addressing the safety and robustness concerns inherent in counterfactual LTR, PRPO enables these powerful techniques to be used in real-world applications.
However, the paper does not explore the potential limitations or drawbacks of the PRPO approach. For example, the degree of safety guarantee provided by the proximity constraint is not quantified, nor is the potential impact on ranking performance compared to an unconstrained approach.
Additionally, the paper focuses on a single-stage ranking scenario, but many real-world systems involve multistage ranking or other complexities that could affect the applicability of PRPO. Further research is needed to understand the broader implications and limitations of this technique.
Overall, the PRPO method represents an important step forward in making counterfactual LTR practical and safe for real-world use. But there remains room for further exploration and refinement of the approach to address its potential shortcomings and expand its capabilities.
Conclusion
This paper introduces a novel technique called Proximal Ranking Policy Optimization (PRPO) that enables the practical application of advanced counterfactual Learning to Rank (LTR) methods. By incorporating robust safety constraints into the optimization process, PRPO can optimize ranking policies to improve performance while avoiding potential reward hacking or other unintended behaviors.
The authors demonstrate the effectiveness of PRPO on real-world datasets, showing that it can outperform baseline counterfactual LTR techniques in terms of ranking performance while maintaining strong safety guarantees. This represents an important advance in making cutting-edge ranking algorithms safe and practical for deployment in high-stakes applications.
Overall, the PRPO approach provides a promising pathway for businesses and researchers to harness the power of counterfactual LTR to benefit their users, while ensuring the safe and responsible development of these influential systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Proximal Ranking Policy Optimization for Practical Safety in Counterfactual Learning to Rank
Shashank Gupta, Harrie Oosterhuis, Maarten de Rijke
Counterfactual learning to rank (CLTR) can be risky and, in various circumstances, can produce sub-optimal models that hurt performance when deployed. Safe CLTR was introduced to mitigate these risks when using inverse propensity scoring to correct for position bias. However, the existing safety measure for CLTR is not applicable to state-of-the-art CLTR methods, cannot handle trust bias, and relies on specific assumptions about user behavior. We propose a novel approach, proximal ranking policy optimization (PRPO), that provides safety in deployment without assumptions about user behavior. PRPO removes incentives for learning ranking behavior that is too dissimilar to a safe ranking model. Thereby, PRPO imposes a limit on how much learned models can degrade performance metrics, without relying on any specific user assumptions. Our experiments show that PRPO provides higher performance than the existing safe inverse propensity scoring approach. PRPO always maintains safety, even in maximally adversarial situations. By avoiding assumptions, PRPO is the first method with unconditional safety in deployment that translates to robust safety for real-world applications.
Read more9/17/2024

0
Practical and Robust Safety Guarantees for Advanced Counterfactual Learning to Rank
Shashank Gupta, Harrie Oosterhuis, Maarten de Rijke
Counterfactual learning to rank (CLTR) can be risky and, in various circumstances, can produce sub-optimal models that hurt performance when deployed. Safe CLTR was introduced to mitigate these risks when using inverse propensity scoring to correct for position bias. However, the existing safety measure for CLTR is not applicable to state-of-the-art CLTR methods, cannot handle trust bias, and relies on specific assumptions about user behavior. Our contributions are two-fold. First, we generalize the existing safe CLTR approach to make it applicable to state-of-the-art doubly robust CLTR and trust bias. Second, we propose a novel approach, proximal ranking policy optimization (PRPO), that provides safety in deployment without assumptions about user behavior. PRPO removes incentives for learning ranking behavior that is too dissimilar to a safe ranking model. Thereby, PRPO imposes a limit on how much learned models can degrade performance metrics, without relying on any specific user assumptions. Our experiments show that both our novel safe doubly robust method and PRPO provide higher performance than the existing safe inverse propensity scoring approach. However, in unexpected circumstances, the safe doubly robust approach can become unsafe and bring detrimental performance. In contrast, PRPO always maintains safety, even in maximally adversarial situations. By avoiding assumptions, PRPO is the first method with unconditional safety in deployment that translates to robust safety for real-world applications.
Read more8/9/2024
0
Solving a Real-World Optimization Problem Using Proximal Policy Optimization with Curriculum Learning and Reward Engineering
Abhijeet Pendyala, Asma Atamna, Tobias Glasmachers
We present a proximal policy optimization (PPO) agent trained through curriculum learning (CL) principles and meticulous reward engineering to optimize a real-world high-throughput waste sorting facility. Our work addresses the challenge of effectively balancing the competing objectives of operational safety, volume optimization, and minimizing resource usage. A vanilla agent trained from scratch on these multiple criteria fails to solve the problem due to its inherent complexities. This problem is particularly difficult due to the environment's extremely delayed rewards with long time horizons and class (or action) imbalance, with important actions being infrequent in the optimal policy. This forces the agent to anticipate long-term action consequences and prioritize rare but rewarding behaviours, creating a non-trivial reinforcement learning task. Our five-stage CL approach tackles these challenges by gradually increasing the complexity of the environmental dynamics during policy transfer while simultaneously refining the reward mechanism. This iterative and adaptable process enables the agent to learn a desired optimal policy. Results demonstrate that our approach significantly improves inference-time safety, achieving near-zero safety violations in addition to enhancing waste sorting plant efficiency.
Read more7/24/2024
0
Investigating the Robustness of Counterfactual Learning to Rank Models: A Reproducibility Study
Zechun Niu, Jiaxin Mao, Qingyao Ai, Ji-Rong Wen
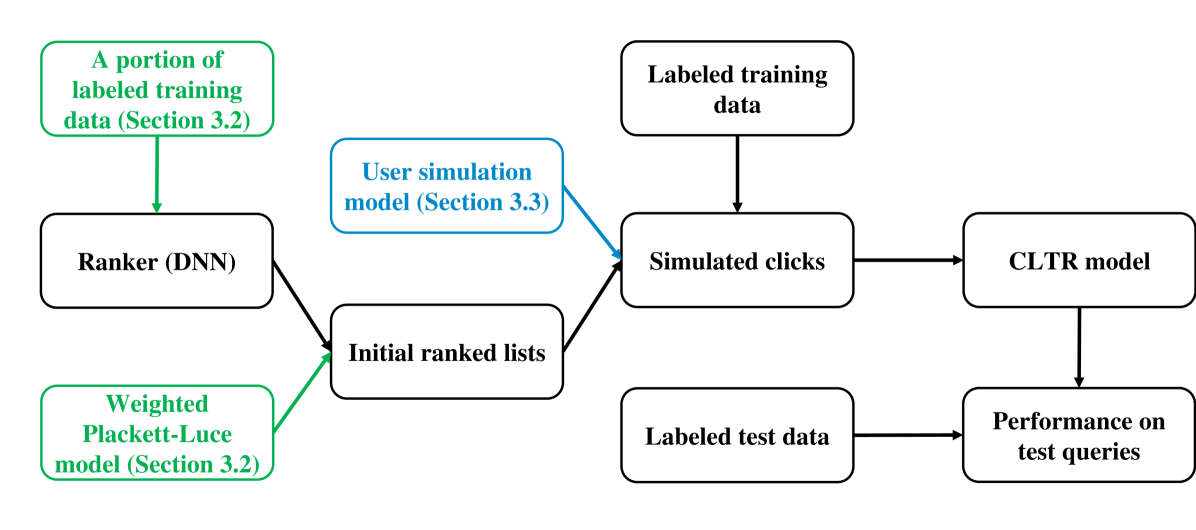
Counterfactual learning to rank (CLTR) has attracted extensive attention in the IR community for its ability to leverage massive logged user interaction data to train ranking models. While the CLTR models can be theoretically unbiased when the user behavior assumption is correct and the propensity estimation is accurate, their effectiveness is usually empirically evaluated via simulation-based experiments due to a lack of widely-available, large-scale, real click logs. However, the mainstream simulation-based experiments are somewhat limited as they often feature a single, deterministic production ranker and simplified user simulation models to generate the synthetic click logs. As a result, the robustness of CLTR models in complex and diverse situations is largely unknown and needs further investigation. To address this problem, in this paper, we aim to investigate the robustness of existing CLTR models in a reproducibility study with extensive simulation-based experiments that (1) use both deterministic and stochastic production rankers, each with different ranking performance, and (2) leverage multiple user simulation models with different user behavior assumptions. We find that the DLA models and IPS-DCM show better robustness under various simulation settings than IPS-PBM and PRS with offline propensity estimation. Besides, the existing CLTR models often fail to outperform the naive click baselines when the production ranker has relatively high ranking performance or certain randomness, which suggests an urgent need for developing new CLTR algorithms that work for these settings.
Read more4/8/2024