Practical and Robust Safety Guarantees for Advanced Counterfactual Learning to Rank

0

Sign in to get full access
Overview
- This paper presents a novel approach for ensuring practical and robust safety guarantees in advanced counterfactual learning to rank (CFLTR) models.
- The researchers develop a robust training framework that can provide provable safety bounds on the model's ranking outputs, even in the presence of distribution shift or adversarial attacks.
- The proposed method is evaluated on real-world datasets and shown to outperform existing CFLTR techniques in terms of ranking performance and safety guarantees.
Plain English Explanation
The paper focuses on an important issue in the field of learning to rank - ensuring the safety and reliability of these models, especially when they are deployed in real-world applications.
Counterfactual Learning to Rank (CFLTR) is a powerful technique that allows ranking models to be trained on historical user interaction data, rather than manually curated relevance judgments. This can lead to more accurate and personalized ranking results. However, CFLTR models can be vulnerable to distribution shifts or adversarial attacks, which can cause them to produce unsafe or unreliable ranking outputs.
To address this, the researchers have developed a robust training framework for CFLTR models that can provide provable safety bounds on the model's ranking outputs. This means the model can give guarantees that its rankings will not deviate too far from what is considered safe or acceptable, even in the face of challenges like distribution shift or adversarial attacks.
The key innovation is a novel optimization objective that balances the model's ranking performance with its ability to provide these safety guarantees. The researchers show that this approach outperforms existing CFLTR techniques, both in terms of ranking quality and the robustness of the safety bounds.
Technical Explanation
The paper proposes a novel robust training framework for Counterfactual Learning to Rank (CFLTR) models that can provide provable safety guarantees on the model's ranking outputs.
The core idea is to formulate the CFLTR training as a constrained optimization problem, where the objective is to maximize the model's ranking performance, subject to safety constraints that bound the deviation of the model's rankings from a set of "safe" rankings.
Specifically, the researchers define a safety set that represents the space of acceptable or safe ranking outputs. They then incorporate this safety set into the training objective as a set-valued constraint, ensuring that the learned CFLTR model's rankings always remain within the safe region.
To solve this constrained optimization problem, the authors propose a robust training algorithm that alternates between optimizing the model's ranking performance and enforcing the safety constraints. This is achieved using a projected gradient descent approach, where the model parameters are updated in the direction of improving ranking performance, followed by a projection step that ensures the updated parameters satisfy the safety constraints.
The key technical contributions include:
-
Safety Set Formulation: The researchers provide a formal definition of the "safe" ranking space, capturing both relevance-based safety (e.g., ensuring high-quality rankings) and diversity-based safety (e.g., maintaining a diverse set of results).
-
Robust Optimization Framework: The authors develop a constrained optimization formulation and a corresponding robust training algorithm to learn CFLTR models that satisfy the safety constraints.
-
Theoretical Analysis: The paper provides a theoretical analysis of the proposed framework, establishing convergence guarantees and safety bounds on the model's rankings.
-
Empirical Evaluation: The researchers evaluate their approach on several real-world learning to rank datasets, demonstrating superior ranking performance and robustness compared to existing CFLTR techniques.
Critical Analysis
The paper presents a well-designed and comprehensive approach to ensuring the safety and robustness of CFLTR models, which is a crucial concern for real-world deployment. The researchers have carefully addressed both relevance-based and diversity-based safety aspects, providing a holistic solution.
However, the theoretical analysis could be further strengthened by considering tighter safety bounds and exploring the dependence of the safety guarantees on the problem parameters. Additionally, the practical applicability of the method may be limited by the computational complexity of the robust optimization procedure, especially for large-scale ranking problems.
It would also be interesting to see how the proposed framework generalizes to other domains beyond learning to rank, such as recommender systems or multimodal ranking, where safety and robustness are equally important concerns.
Conclusion
This paper presents a novel and robust training framework for Counterfactual Learning to Rank (CFLTR) models that can provide practical and provable safety guarantees on the model's ranking outputs. The proposed approach outperforms existing CFLTR techniques in terms of both ranking performance and safety, making it a promising solution for real-world applications where the reliability and safety of ranking systems are critical.
The key contributions of this work include the formulation of a safety-constrained optimization problem, the development of a robust training algorithm, and the theoretical and empirical analysis of the proposed framework. While there are some potential limitations, this research represents an important step towards building safe and trustworthy learning to rank systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Practical and Robust Safety Guarantees for Advanced Counterfactual Learning to Rank
Shashank Gupta, Harrie Oosterhuis, Maarten de Rijke
Counterfactual learning to rank (CLTR) can be risky and, in various circumstances, can produce sub-optimal models that hurt performance when deployed. Safe CLTR was introduced to mitigate these risks when using inverse propensity scoring to correct for position bias. However, the existing safety measure for CLTR is not applicable to state-of-the-art CLTR methods, cannot handle trust bias, and relies on specific assumptions about user behavior. Our contributions are two-fold. First, we generalize the existing safe CLTR approach to make it applicable to state-of-the-art doubly robust CLTR and trust bias. Second, we propose a novel approach, proximal ranking policy optimization (PRPO), that provides safety in deployment without assumptions about user behavior. PRPO removes incentives for learning ranking behavior that is too dissimilar to a safe ranking model. Thereby, PRPO imposes a limit on how much learned models can degrade performance metrics, without relying on any specific user assumptions. Our experiments show that both our novel safe doubly robust method and PRPO provide higher performance than the existing safe inverse propensity scoring approach. However, in unexpected circumstances, the safe doubly robust approach can become unsafe and bring detrimental performance. In contrast, PRPO always maintains safety, even in maximally adversarial situations. By avoiding assumptions, PRPO is the first method with unconditional safety in deployment that translates to robust safety for real-world applications.
Read more8/9/2024

0
New!Proximal Ranking Policy Optimization for Practical Safety in Counterfactual Learning to Rank
Shashank Gupta, Harrie Oosterhuis, Maarten de Rijke
Counterfactual learning to rank (CLTR) can be risky and, in various circumstances, can produce sub-optimal models that hurt performance when deployed. Safe CLTR was introduced to mitigate these risks when using inverse propensity scoring to correct for position bias. However, the existing safety measure for CLTR is not applicable to state-of-the-art CLTR methods, cannot handle trust bias, and relies on specific assumptions about user behavior. We propose a novel approach, proximal ranking policy optimization (PRPO), that provides safety in deployment without assumptions about user behavior. PRPO removes incentives for learning ranking behavior that is too dissimilar to a safe ranking model. Thereby, PRPO imposes a limit on how much learned models can degrade performance metrics, without relying on any specific user assumptions. Our experiments show that PRPO provides higher performance than the existing safe inverse propensity scoring approach. PRPO always maintains safety, even in maximally adversarial situations. By avoiding assumptions, PRPO is the first method with unconditional safety in deployment that translates to robust safety for real-world applications.
Read more9/17/2024
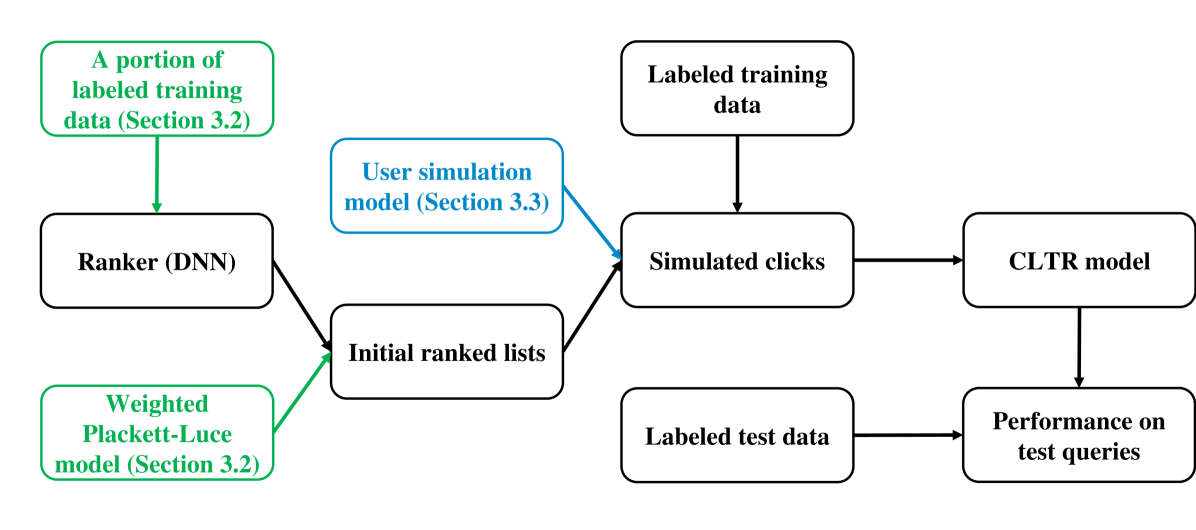
0
Investigating the Robustness of Counterfactual Learning to Rank Models: A Reproducibility Study
Zechun Niu, Jiaxin Mao, Qingyao Ai, Ji-Rong Wen
Counterfactual learning to rank (CLTR) has attracted extensive attention in the IR community for its ability to leverage massive logged user interaction data to train ranking models. While the CLTR models can be theoretically unbiased when the user behavior assumption is correct and the propensity estimation is accurate, their effectiveness is usually empirically evaluated via simulation-based experiments due to a lack of widely-available, large-scale, real click logs. However, the mainstream simulation-based experiments are somewhat limited as they often feature a single, deterministic production ranker and simplified user simulation models to generate the synthetic click logs. As a result, the robustness of CLTR models in complex and diverse situations is largely unknown and needs further investigation. To address this problem, in this paper, we aim to investigate the robustness of existing CLTR models in a reproducibility study with extensive simulation-based experiments that (1) use both deterministic and stochastic production rankers, each with different ranking performance, and (2) leverage multiple user simulation models with different user behavior assumptions. We find that the DLA models and IPS-DCM show better robustness under various simulation settings than IPS-PBM and PRS with offline propensity estimation. Besides, the existing CLTR models often fail to outperform the naive click baselines when the production ranker has relatively high ranking performance or certain randomness, which suggests an urgent need for developing new CLTR algorithms that work for these settings.
Read more4/8/2024

0
Inference-time Stochastic Ranking with Risk Control
Ruocheng Guo, Jean-Franc{c}ois Ton, Yang Liu, Hang Li
Learning to Rank (LTR) methods are vital in online economies, affecting users and item providers. Fairness in LTR models is crucial to allocate exposure proportionally to item relevance. Widely used deterministic LTR models can lead to unfair exposure distribution, especially when items with the same relevance receive slightly different ranking scores. Stochastic LTR models, incorporating the Plackett-Luce (PL) ranking model, address fairness issues but suffer from high training cost. In addition, they cannot provide guarantees on the utility or fairness, which can lead to dramatic degraded utility when optimized for fairness. To overcome these limitations, we propose Inference-time Stochastic Ranking with Risk Control (ISRR), a novel method that performs stochastic ranking at inference time with guanranteed utility or fairness given pretrained scoring functions from deterministic or stochastic LTR models. Comprehensive experimental results on three widely adopted datasets demonstrate that our proposed method achieves utility and fairness comparable to existing stochastic ranking methods with much lower computational cost. In addition, results verify that our method provides finite-sample guarantee on utility and fairness. This advancement represents a significant contribution to the field of stochastic ranking and fair LTR with promising real-world applications.
Read more5/21/2024