Investigating the Robustness of Counterfactual Learning to Rank Models: A Reproducibility Study
2404.03707
0
0
Abstract
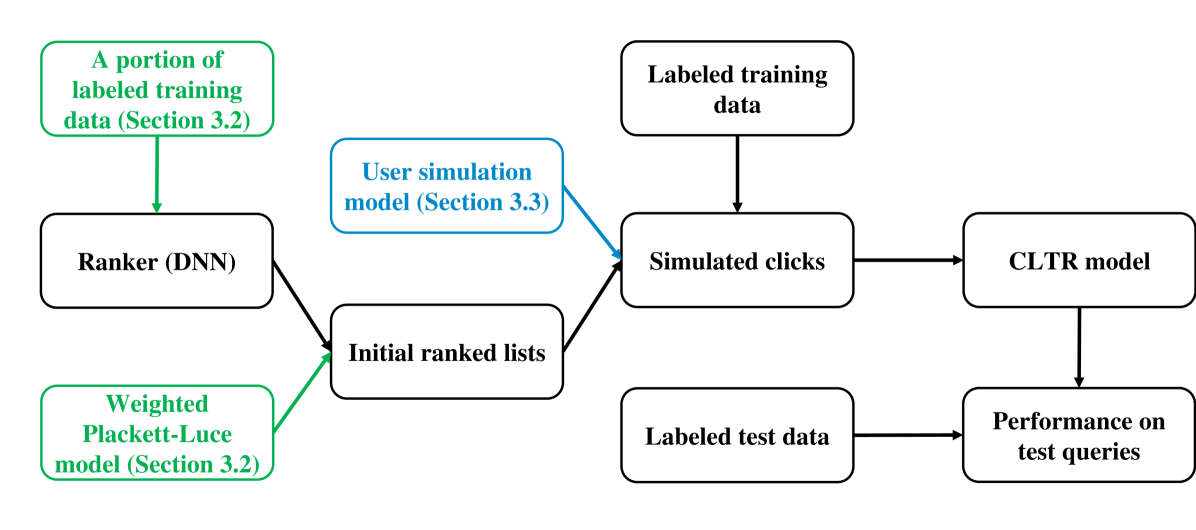
Counterfactual learning to rank (CLTR) has attracted extensive attention in the IR community for its ability to leverage massive logged user interaction data to train ranking models. While the CLTR models can be theoretically unbiased when the user behavior assumption is correct and the propensity estimation is accurate, their effectiveness is usually empirically evaluated via simulation-based experiments due to a lack of widely-available, large-scale, real click logs. However, the mainstream simulation-based experiments are somewhat limited as they often feature a single, deterministic production ranker and simplified user simulation models to generate the synthetic click logs. As a result, the robustness of CLTR models in complex and diverse situations is largely unknown and needs further investigation. To address this problem, in this paper, we aim to investigate the robustness of existing CLTR models in a reproducibility study with extensive simulation-based experiments that (1) use both deterministic and stochastic production rankers, each with different ranking performance, and (2) leverage multiple user simulation models with different user behavior assumptions. We find that the DLA models and IPS-DCM show better robustness under various simulation settings than IPS-PBM and PRS with offline propensity estimation. Besides, the existing CLTR models often fail to outperform the naive click baselines when the production ranker has relatively high ranking performance or certain randomness, which suggests an urgent need for developing new CLTR algorithms that work for these settings.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates the robustness of counterfactual learning-to-rank (CLTR) models, which are used to rank search results based on user feedback rather than manually curated relevance labels.
- The authors conduct a reproducibility study to understand how CLTR models perform under different conditions, such as changes in user behavior or the underlying data distribution.
- The findings have implications for the real-world deployment of CLTR models, which are susceptible to various biases and can produce unreliable rankings if not properly accounted for.
Plain English Explanation
In the world of search engines and recommendation systems, the traditional approach to ranking content has been to manually assign relevance scores to each item. However, this can be time-consuming and subjective. Counterfactual learning-to-rank (CLTR) models offer a more data-driven alternative, where the rankings are based on user feedback rather than manual labeling.
The authors of this paper wanted to understand how robust these CLTR models are to changes in the real-world conditions they might encounter, such as shifts in user behavior or the underlying distribution of the data. To do this, they conducted a reproducibility study, which involves closely replicating the original experiment to see if the same results are obtained.
The findings of this study have important implications for the deployment of CLTR models in practical applications. These models can be susceptible to various biases and may not perform as well as expected if the real-world conditions differ from those used during training. By understanding the limitations and edge cases of CLTR models, researchers and practitioners can take steps to make them more reliable and trustworthy.
Technical Explanation
The authors of this paper conducted a comprehensive simulation-based experiment to assess the robustness of CLTR models. They used a popular CLTR algorithm, called Dueling Bandit Gradient Descent (DBGD), as the basis for their investigation.
The experiment involved simulating different user behavior patterns and data distribution shifts, and then measuring the performance of the DBGD model under these conditions. This allowed the researchers to understand how sensitive the CLTR model was to changes in the real-world environment.
The results of the study showed that the DBGD model was indeed quite fragile and prone to performance degradation when faced with certain types of changes. For example, the model struggled when the user behavior shifted from exploring the full ranked list to only examining the top few results. The authors also found that the model's performance was heavily dependent on the specific characteristics of the underlying data distribution.
These findings highlight the need for further research and development to make CLTR models more robust and reliable. The authors suggest that future work should focus on designing CLTR algorithms that are less sensitive to changes in user behavior and data distribution, as well as developing better techniques for evaluating the real-world performance of these models.
Critical Analysis
The authors of this paper have done a commendable job in highlighting the potential vulnerabilities of CLTR models. By conducting a rigorous reproducibility study, they have uncovered important insights about the fragility of these models in the face of real-world changes.
However, it's worth noting that the study was limited to a single CLTR algorithm (DBGD) and a specific set of simulated conditions. It would be valuable to see the same experiments performed with a wider range of CLTR models and a more diverse set of realistic scenarios.
Additionally, the paper does not provide much detail on the specific biases and limitations of the DBGD model that contributed to its poor performance under certain conditions. A deeper examination of these model-specific issues could help guide the development of more robust CLTR algorithms in the future.
Finally, the authors acknowledge that their simulation-based approach may not fully capture the complexities of real-world deployment scenarios. Further research involving live user studies and A/B testing in production environments could provide additional insights and validation of the findings presented in this paper.
Conclusion
This paper makes a valuable contribution to the field of CLTR by highlighting the potential fragility of these models in real-world applications. The authors' simulation-based reproducibility study has uncovered important limitations and edge cases that must be addressed to ensure the reliable deployment of CLTR systems.
The findings from this research have implications for both researchers and practitioners working in the field of information retrieval and recommender systems. By understanding the vulnerabilities of CLTR models, they can work towards developing more robust and trustworthy algorithms that can better withstand the challenges of dynamic user behavior and shifting data distributions.
Overall, this paper serves as a reminder that the performance of machine learning models, even in well-studied domains like learning to rank, cannot be taken for granted. Rigorous testing and validation are essential to ensuring the reliability and safety of these systems in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Identifiability Matters: Revealing the Hidden Recoverable Condition in Unbiased Learning to Rank
Mouxiang Chen, Chenghao Liu, Zemin Liu, Zhuo Li, Jianling Sun
0
0
Unbiased Learning to Rank (ULTR) aims to train unbiased ranking models from biased click logs, by explicitly modeling a generation process for user behavior and fitting click data based on examination hypothesis. Previous research found empirically that the true latent relevance is mostly recoverable through click fitting. However, we demonstrate that this is not always achievable, resulting in a significant reduction in ranking performance. This research investigates the conditions under which relevance can be recovered from click data in the first principle. We initially characterize a ranking model as identifiable if it can recover the true relevance up to a scaling transformation, a criterion sufficient for the pairwise ranking objective. Subsequently, we investigate an equivalent condition for identifiability, articulated as a graph connectivity test problem: the recovery of relevance is feasible if and only if the identifiability graph (IG), derived from the underlying structure of the dataset, is connected. The presence of a disconnected IG may lead to degenerate cases and suboptimal ranking performance. To tackle this challenge, we introduce two methods, namely node intervention and node merging, designed to modify the dataset and restore the connectivity of the IG. Empirical results derived from a simulated dataset and two real-world LTR benchmark datasets not only validate our proposed theory but also demonstrate the effectiveness of our methods in alleviating data bias when the relevance model is unidentifiable.
5/27/2024

Inference-time Stochastic Ranking with Risk Control
Ruocheng Guo, Jean-Franc{c}ois Ton, Yang Liu, Hang Li
0
0
Learning to Rank (LTR) methods are vital in online economies, affecting users and item providers. Fairness in LTR models is crucial to allocate exposure proportionally to item relevance. Widely used deterministic LTR models can lead to unfair exposure distribution, especially when items with the same relevance receive slightly different ranking scores. Stochastic LTR models, incorporating the Plackett-Luce (PL) ranking model, address fairness issues but suffer from high training cost. In addition, they cannot provide guarantees on the utility or fairness, which can lead to dramatic degraded utility when optimized for fairness. To overcome these limitations, we propose Inference-time Stochastic Ranking with Risk Control (ISRR), a novel method that performs stochastic ranking at inference time with guanranteed utility or fairness given pretrained scoring functions from deterministic or stochastic LTR models. Comprehensive experimental results on three widely adopted datasets demonstrate that our proposed method achieves utility and fairness comparable to existing stochastic ranking methods with much lower computational cost. In addition, results verify that our method provides finite-sample guarantee on utility and fairness. This advancement represents a significant contribution to the field of stochastic ranking and fair LTR with promising real-world applications.
5/21/2024
🔮
Retrieval-Oriented Knowledge for Click-Through Rate Prediction
Huanshuo Liu, Bo Chen, Menghui Zhu, Jianghao Lin, Jiarui Qin, Yang Yang, Hao Zhang, Ruiming Tang
0
0
Click-through rate (CTR) prediction plays an important role in personalized recommendations. Recently, sample-level retrieval-based models (e.g., RIM) have achieved remarkable performance by retrieving and aggregating relevant samples. However, their inefficiency at the inference stage makes them impractical for industrial applications. To overcome this issue, this paper proposes a universal plug-and-play Retrieval-Oriented Knowledge (ROK) framework. Specifically, a knowledge base, consisting of a retrieval-oriented embedding layer and a knowledge encoder, is designed to preserve and imitate the retrieved & aggregated representations in a decomposition-reconstruction paradigm. Knowledge distillation and contrastive learning methods are utilized to optimize the knowledge base, and the learned retrieval-enhanced representations can be integrated with arbitrary CTR models in both instance-wise and feature-wise manners. Extensive experiments on three large-scale datasets show that ROK achieves competitive performance with the retrieval-based CTR models while reserving superior inference efficiency and model compatibility.
4/30/2024
Recall-Augmented Ranking: Enhancing Click-Through Rate Prediction Accuracy with Cross-Stage Data
Junjie Huang, Guohao Cai, Jieming Zhu, Zhenhua Dong, Ruiming Tang, Weinan Zhang, Yong Yu
0
0
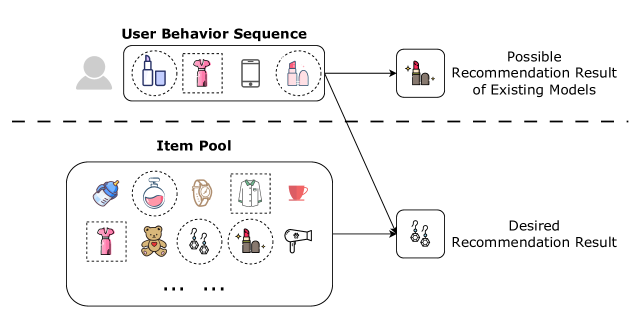
Click-through rate (CTR) prediction plays an indispensable role in online platforms. Numerous models have been proposed to capture users' shifting preferences by leveraging user behavior sequences. However, these historical sequences often suffer from severe homogeneity and scarcity compared to the extensive item pool. Relying solely on such sequences for user representations is inherently restrictive, as user interests extend beyond the scope of items they have previously engaged with. To address this challenge, we propose a data-driven approach to enrich user representations. We recognize user profiling and recall items as two ideal data sources within the cross-stage framework, encompassing the u2u (user-to-user) and i2i (item-to-item) aspects respectively. In this paper, we propose a novel architecture named Recall-Augmented Ranking (RAR). RAR consists of two key sub-modules, which synergistically gather information from a vast pool of look-alike users and recall items, resulting in enriched user representations. Notably, RAR is orthogonal to many existing CTR models, allowing for consistent performance improvements in a plug-and-play manner. Extensive experiments are conducted, which verify the efficacy and compatibility of RAR against the SOTA methods.
4/16/2024