ProxyCLIP: Proxy Attention Improves CLIP for Open-Vocabulary Segmentation

0

Sign in to get full access
Overview
- This paper introduces ProxyCLIP, a method for improving the open-vocabulary segmentation performance of CLIP (Contrastive Language-Image Pre-training).
- ProxyCLIP adds a proxy attention module to CLIP, which helps the model better align text and visual features.
- The authors demonstrate that ProxyCLIP outperforms CLIP on various open-vocabulary segmentation benchmarks.
Plain English Explanation
CLIP is a powerful AI model that can perform a wide range of visual recognition tasks using text descriptions. However, CLIP's performance on open-vocabulary segmentation, where the model needs to identify objects in an image that are described by arbitrary text, has room for improvement.
The researchers behind ProxyCLIP have developed a way to enhance CLIP's open-vocabulary segmentation capabilities. They added a proxy attention module to the model, which helps it better align the text descriptions with the corresponding visual features in the image. This alignment is crucial for accurately identifying and segmenting objects described by arbitrary text.
By incorporating this proxy attention mechanism, ProxyCLIP demonstrates superior performance compared to the original CLIP model on several open-vocabulary segmentation benchmarks. This means that ProxyCLIP can more accurately identify and segment objects in images based on text descriptions, making it a more powerful tool for tasks like image understanding and visual search.
Technical Explanation
The key innovation in ProxyCLIP is the addition of a proxy attention module to the standard CLIP architecture. This proxy attention module is designed to improve the alignment between the text and visual features learned by CLIP.
In the standard CLIP model, the text and image encoders are trained independently to learn representations that are well-aligned in the shared embedding space. However, this alignment is not always perfect, which can limit CLIP's performance on tasks like open-vocabulary segmentation.
The proxy attention module in ProxyCLIP acts as an intermediary between the text and image features. It learns a set of proxy features that can better bridge the gap between the text and visual representations. This is achieved by introducing a learnable proxy feature bank, which is attended to by both the text and image encoders during the training process.
The authors demonstrate that this proxy attention mechanism leads to better alignment between the text and visual features, resulting in improved performance on open-vocabulary segmentation benchmarks compared to the original CLIP model. They evaluate ProxyCLIP on several datasets, including COCO, Pascal VOC, and GoodVision, and show consistent improvements across these benchmarks.
Critical Analysis
The authors acknowledge that while ProxyCLIP outperforms CLIP on open-vocabulary segmentation, there is still room for improvement. They note that the proxy attention module adds some computational overhead, which may be a concern for certain real-world applications.
Additionally, the authors mention that their approach relies on pre-training CLIP on a large-scale dataset, which may not be feasible in all scenarios. It would be interesting to explore whether ProxyCLIP can be effectively fine-tuned on smaller datasets or whether the proxy attention module can be integrated into the initial CLIP training process.
Furthermore, the authors do not provide a thorough analysis of the types of text descriptions or visual scenes where ProxyCLIP excels or struggles compared to CLIP. A deeper understanding of the model's strengths and limitations would help researchers and practitioners better assess its suitability for their specific use cases.
Conclusion
This paper introduces ProxyCLIP, a method for improving the open-vocabulary segmentation performance of the CLIP model. By incorporating a proxy attention mechanism, ProxyCLIP is able to better align the text and visual features, leading to superior performance on various open-vocabulary segmentation benchmarks compared to the original CLIP model.
The improved open-vocabulary segmentation capabilities of ProxyCLIP have the potential to enhance a wide range of applications, such as image understanding, visual search, and content creation. As the authors suggest, further research is needed to explore the model's limitations and explore ways to make it more computationally efficient and adaptable to smaller datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ProxyCLIP: Proxy Attention Improves CLIP for Open-Vocabulary Segmentation
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, Wayne Zhang
Open-vocabulary semantic segmentation requires models to effectively integrate visual representations with open-vocabulary semantic labels. While Contrastive Language-Image Pre-training (CLIP) models shine in recognizing visual concepts from text, they often struggle with segment coherence due to their limited localization ability. In contrast, Vision Foundation Models (VFMs) excel at acquiring spatially consistent local visual representations, yet they fall short in semantic understanding. This paper introduces ProxyCLIP, an innovative framework designed to harmonize the strengths of both CLIP and VFMs, facilitating enhanced open-vocabulary semantic segmentation. ProxyCLIP leverages the spatial feature correspondence from VFMs as a form of proxy attention to augment CLIP, thereby inheriting the VFMs' robust local consistency and maintaining CLIP's exceptional zero-shot transfer capacity. We propose an adaptive normalization and masking strategy to get the proxy attention from VFMs, allowing for adaptation across different VFMs. Remarkably, as a training-free approach, ProxyCLIP significantly improves the average mean Intersection over Union (mIoU) across eight benchmarks from 40.3 to 44.4, showcasing its exceptional efficacy in bridging the gap between spatial precision and semantic richness for the open-vocabulary segmentation task.
Read more8/12/2024
0
CLIP-VIS: Adapting CLIP for Open-Vocabulary Video Instance Segmentation
Wenqi Zhu, Jiale Cao, Jin Xie, Shuangming Yang, Yanwei Pang
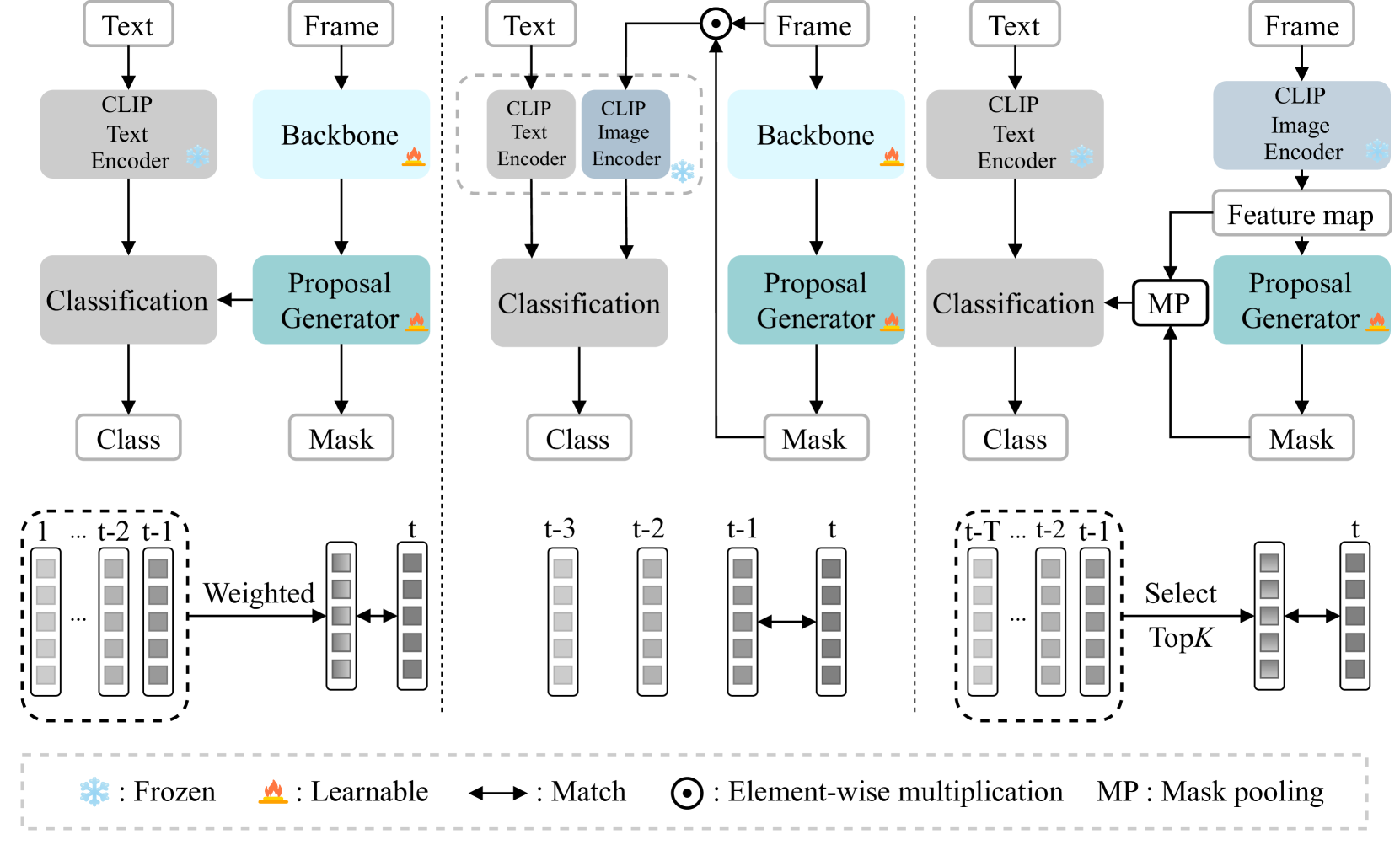
Open-vocabulary video instance segmentation strives to segment and track instances belonging to an open set of categories in a video. The vision-language model Contrastive Language-Image Pre-training (CLIP) has shown robust zero-shot classification ability in image-level open-vocabulary task. In this paper, we propose a simple encoder-decoder network, called CLIP-VIS, to adapt CLIP for open-vocabulary video instance segmentation. Our CLIP-VIS adopts frozen CLIP image encoder and introduces three modules, including class-agnostic mask generation, temporal topK-enhanced matching, and weighted open-vocabulary classification. Given a set of initial queries, class-agnostic mask generation employs a transformer decoder to predict query masks and corresponding object scores and mask IoU scores. Then, temporal topK-enhanced matching performs query matching across frames by using K mostly matched frames. Finally, weighted open-vocabulary classification first generates query visual features with mask pooling, and second performs weighted classification using object scores and mask IoU scores.Our CLIP-VIS does not require the annotations of instance categories and identities. The experiments are performed on various video instance segmentation datasets, which demonstrate the effectiveness of our proposed method, especially on novel categories. When using ConvNeXt-B as backbone, our CLIP-VIS achieves the AP and APn scores of 32.2% and 40.2% on validation set of LV-VIS dataset, which outperforms OV2Seg by 11.1% and 23.9% respectively. We will release the source code and models at https://github.com/zwq456/CLIP-VIS.git.
Read more6/11/2024

0
ClearCLIP: Decomposing CLIP Representations for Dense Vision-Language Inference
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, Wayne Zhang
Despite the success of large-scale pretrained Vision-Language Models (VLMs) especially CLIP in various open-vocabulary tasks, their application to semantic segmentation remains challenging, producing noisy segmentation maps with mis-segmented regions. In this paper, we carefully re-investigate the architecture of CLIP, and identify residual connections as the primary source of noise that degrades segmentation quality. With a comparative analysis of statistical properties in the residual connection and the attention output across different pretrained models, we discover that CLIP's image-text contrastive training paradigm emphasizes global features at the expense of local discriminability, leading to noisy segmentation results. In response, we propose ClearCLIP, a novel approach that decomposes CLIP's representations to enhance open-vocabulary semantic segmentation. We introduce three simple modifications to the final layer: removing the residual connection, implementing the self-self attention, and discarding the feed-forward network. ClearCLIP consistently generates clearer and more accurate segmentation maps and outperforms existing approaches across multiple benchmarks, affirming the significance of our discoveries.
Read more7/18/2024

0
Explore the Potential of CLIP for Training-Free Open Vocabulary Semantic Segmentation
Tong Shao, Zhuotao Tian, Hang Zhao, Jingyong Su
CLIP, as a vision-language model, has significantly advanced Open-Vocabulary Semantic Segmentation (OVSS) with its zero-shot capabilities. Despite its success, its application to OVSS faces challenges due to its initial image-level alignment training, which affects its performance in tasks requiring detailed local context. Our study delves into the impact of CLIP's [CLS] token on patch feature correlations, revealing a dominance of global patches that hinders local feature discrimination. To overcome this, we propose CLIPtrase, a novel training-free semantic segmentation strategy that enhances local feature awareness through recalibrated self-correlation among patches. This approach demonstrates notable improvements in segmentation accuracy and the ability to maintain semantic coherence across objects.Experiments show that we are 22.3% ahead of CLIP on average on 9 segmentation benchmarks, outperforming existing state-of-the-art training-free methods.The code are made publicly available at: https://github.com/leaves162/CLIPtrase.
Read more7/12/2024