Explore the Potential of CLIP for Training-Free Open Vocabulary Semantic Segmentation

0

Sign in to get full access
Overview
- This paper explores using the CLIP (Contrastive Language-Image Pre-training) model for training-free, open-vocabulary semantic segmentation.
- The proposed approach leverages CLIP's ability to map images and text to a shared embedding space, allowing it to perform zero-shot classification of image regions without any task-specific training.
- The paper demonstrates the potential of this approach on various datasets, showing its effectiveness in segmenting objects and scenes with a broad range of semantic categories.
Plain English Explanation
The researchers in this paper looked at using a pre-trained AI model called CLIP to do a task called semantic segmentation without any additional training. Semantic segmentation is when you take an image and automatically identify and label the different objects, scenes, and elements in it.
Typically, to do semantic segmentation, you need to train a machine learning model on a large dataset of labeled images. But the researchers found that they could use CLIP, which was trained on a huge amount of online data to learn how images and text are related, to do semantic segmentation without any additional training.
The key idea is that CLIP can map both images and text descriptions into a shared mathematical space. So if you show CLIP an image, it can compare that to the "visual embeddings" it has learned for different object and scene categories, and then label the relevant parts of the image without having seen those specific objects or scenes before.
This is known as "zero-shot" classification, because the model is able to classify things it hasn't been explicitly trained on. The paper demonstrates that this CLIP-based approach works surprisingly well for segmenting a wide variety of objects and scenes, opening up new possibilities for training-free, open-vocabulary semantic understanding of images.
Technical Explanation
The key innovation in this paper is the use of the CLIP model for training-free, open-vocabulary semantic segmentation. CLIP is a large, pre-trained vision-language model that can map both images and text descriptions into a shared embedding space.
The researchers leverage this capability to perform zero-shot classification of image regions. Given an input image, they first generate region proposals using off-the-shelf object detectors. They then use CLIP to compute the similarity between each region and a set of text prompts describing various semantic categories. The regions are then classified based on the highest similarity scores, without any task-specific training.
The paper evaluates this CLIP-based approach on several popular semantic segmentation datasets, including PASCAL VOC, ADE20K, and COCO-Stuff. The results demonstrate that the CLIP-based segmentation outperforms previous training-free approaches and can rival the performance of fully supervised models in many cases.
Critical Analysis
The paper presents a compelling and novel approach to semantic segmentation that leverages the powerful, pre-trained CLIP model. The key strength of this work is its ability to perform open-vocabulary, training-free segmentation, which could greatly expand the applicability of semantic understanding to a broader range of real-world scenarios.
However, the paper also acknowledges several limitations of the current approach. First, the performance is still behind state-of-the-art supervised methods, particularly on more complex datasets. Additionally, the approach relies on region proposals from external object detectors, which could introduce errors and biases.
One potential area for further research would be to explore end-to-end CLIP-based segmentation models that can jointly generate region proposals and classify them. This could help the model better adapt to the specific segmentation task and improve overall performance.
Another interesting direction would be to investigate the robustness and generalization of the CLIP-based segmentation, such as how it handles novel or unusual object/scene categories, occlusions, and variations in viewpoint and lighting conditions.
Overall, this paper presents a promising step towards more flexible and accessible semantic understanding of visual data, and the continued development of this line of research could have important implications for a wide range of computer vision applications.
Conclusion
This paper explores the use of the pre-trained CLIP model for training-free, open-vocabulary semantic segmentation. By leveraging CLIP's ability to map images and text into a shared embedding space, the proposed approach can perform zero-shot classification of image regions without any task-specific training.
The results demonstrate the potential of this CLIP-based approach, showing competitive performance on various semantic segmentation datasets compared to previous training-free methods and even fully supervised models. While there are still some limitations to address, this work opens up exciting possibilities for more flexible and accessible visual understanding systems that can adapt to a broad range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Explore the Potential of CLIP for Training-Free Open Vocabulary Semantic Segmentation
Tong Shao, Zhuotao Tian, Hang Zhao, Jingyong Su
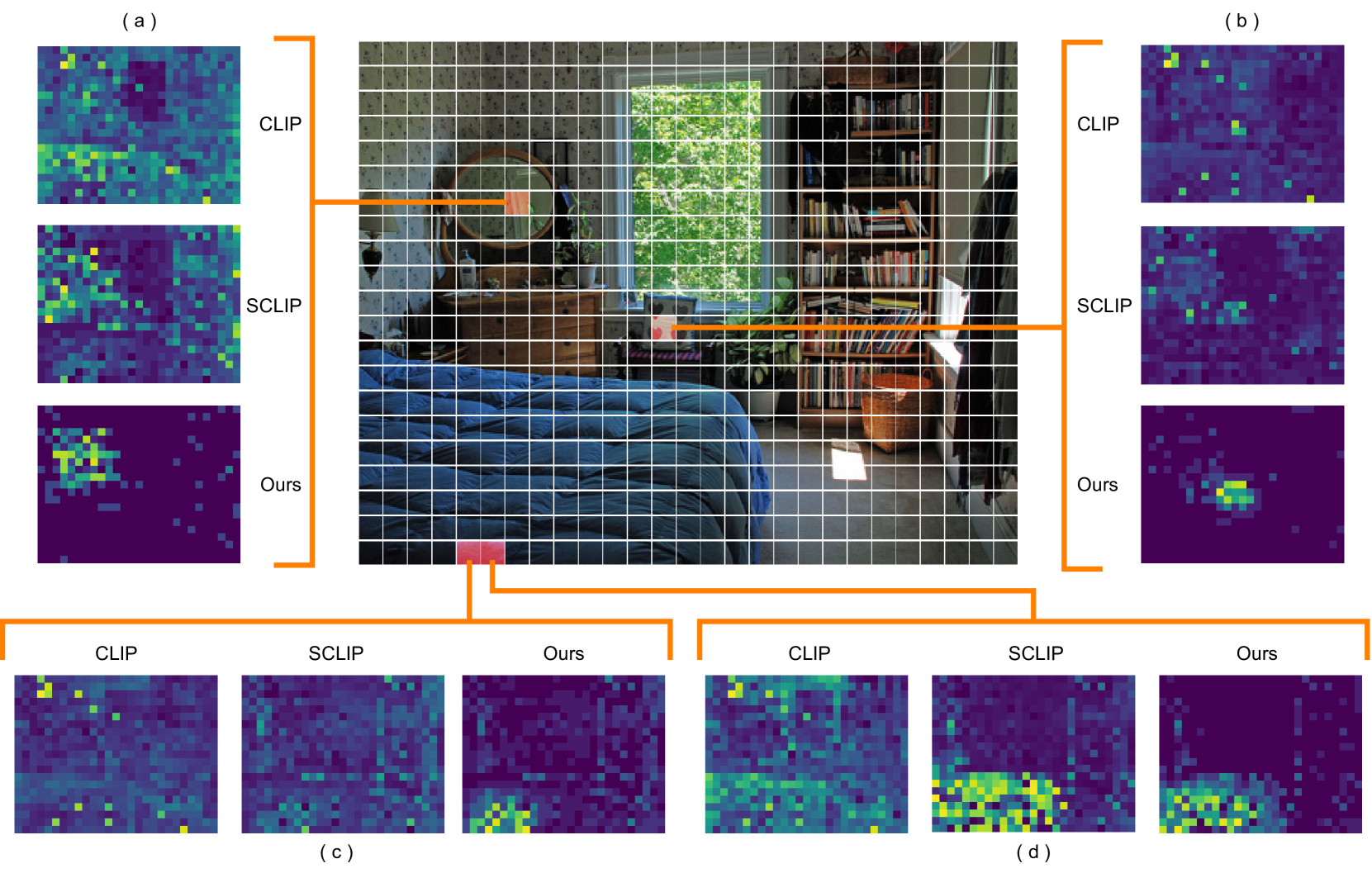
CLIP, as a vision-language model, has significantly advanced Open-Vocabulary Semantic Segmentation (OVSS) with its zero-shot capabilities. Despite its success, its application to OVSS faces challenges due to its initial image-level alignment training, which affects its performance in tasks requiring detailed local context. Our study delves into the impact of CLIP's [CLS] token on patch feature correlations, revealing a dominance of global patches that hinders local feature discrimination. To overcome this, we propose CLIPtrase, a novel training-free semantic segmentation strategy that enhances local feature awareness through recalibrated self-correlation among patches. This approach demonstrates notable improvements in segmentation accuracy and the ability to maintain semantic coherence across objects.Experiments show that we are 22.3% ahead of CLIP on average on 9 segmentation benchmarks, outperforming existing state-of-the-art training-free methods.The code are made publicly available at: https://github.com/leaves162/CLIPtrase.
Read more7/12/2024
0
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
Sina Hajimiri, Ismail Ben Ayed, Jose Dolz
Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporating design choices favouring segmentation, our approach significantly improves performance without requiring additional data, auxiliary pre-trained networks, or extensive hyperparameter tuning, making it highly practical for real-world applications. Experiments are performed on 8 popular semantic segmentation benchmarks, yielding state-of-the-art performance on most scenarios. Our code is publicly available at https://github.com/sinahmr/NACLIP .
Read more4/15/2024
🧪
0
TagCLIP: Improving Discrimination Ability of Open-Vocabulary Semantic Segmentation
Jingyao Li, Pengguang Chen, Shengju Qian, Shu Liu, Jiaya Jia
Contrastive Language-Image Pre-training (CLIP) has recently shown great promise in pixel-level zero-shot learning tasks. However, existing approaches utilizing CLIP's text and patch embeddings to generate semantic masks often misidentify input pixels from unseen classes, leading to confusion between novel classes and semantically similar ones. In this work, we propose a novel approach, TagCLIP (Trusty-aware guided CLIP), to address this issue. We disentangle the ill-posed optimization problem into two parallel processes: semantic matching performed individually and reliability judgment for improving discrimination ability. Building on the idea of special tokens in language modeling representing sentence-level embeddings, we introduce a trusty token that enables distinguishing novel classes from known ones in prediction. To evaluate our approach, we conduct experiments on two benchmark datasets, PASCAL VOC 2012, COCO-Stuff 164K and PASCAL Context. Our results show that TagCLIP improves the Intersection over Union (IoU) of unseen classes by 7.4%, 1.7% and 2.1%, respectively, with negligible overheads. The code is available at https://github.com/dvlab-research/TagCLIP.
Read more9/4/2024
🛸
0
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
Read more6/7/2024