Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging
2406.16330
0
0
Abstract
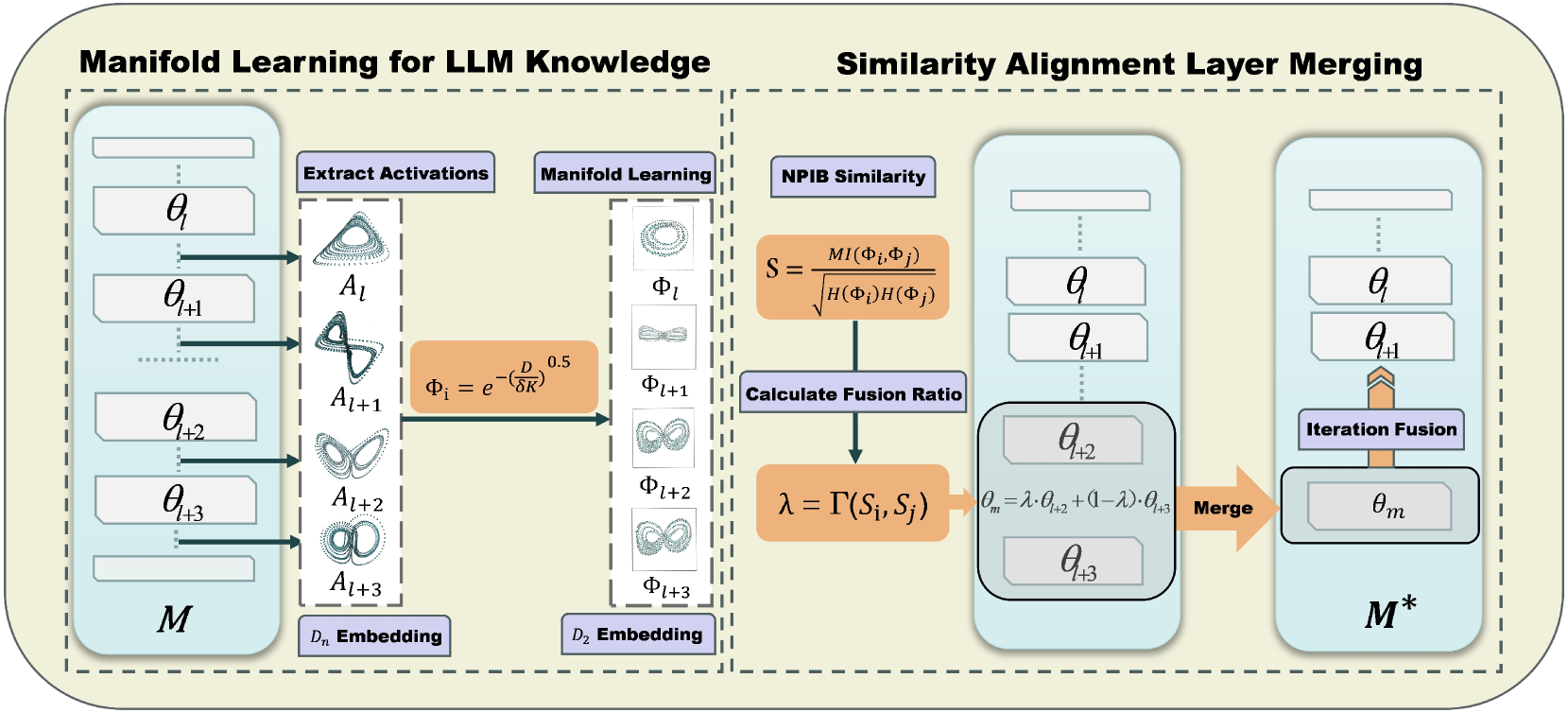
While large language models (LLMs) excel in many domains, their complexity and scale challenge deployment in resource-limited environments. Current compression techniques, such as parameter pruning, often fail to effectively utilize the knowledge from pruned parameters. To address these challenges, we propose Manifold-Based Knowledge Alignment and Layer Merging Compression (MKA), a novel approach that uses manifold learning and the Normalized Pairwise Information Bottleneck (NPIB) measure to merge similar layers, reducing model size while preserving essential performance. We evaluate MKA on multiple benchmark datasets and various LLMs. Our findings show that MKA not only preserves model performance but also achieves substantial compression ratios, outperforming traditional pruning methods. Moreover, when coupled with quantization, MKA delivers even greater compression. Specifically, on the MMLU dataset using the Llama3-8B model, MKA achieves a compression ratio of 43.75% with a minimal performance decrease of only 2.82%. The proposed MKA method offers a resource-efficient and performance-preserving model compression technique for LLMs.
Create account to get full access
Overview
- Proposed a novel layer merging technique called "Pruning via Merging" to compress large language models (LLMs)
- Leverages manifold alignment to identify and merge similar layers, reducing model size without significant performance degradation
- Demonstrated on popular LLMs like GPT-2 and BERT, achieving up to 2.5x compression ratios
Plain English Explanation
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging is a technique that aims to make large language models, like GPT-2 and BERT, more compact without significantly reducing their performance.
The key idea is to identify and merge similar layers in the model. Large language models often have many similar or redundant layers, which can be safely combined to reduce the overall model size. The researchers use a technique called "manifold alignment" to find these similar layers and then merge them together.
Manifold alignment is a way of comparing the internal representations of the model at different layers. By aligning the "manifolds" (the shapes) of these representations, the researchers can identify which layers are doing similar things and can be merged. This allows them to prune, or remove, unnecessary layers, resulting in a more compact model.
The researchers demonstrated this technique on popular language models and were able to achieve compression ratios of up to 2.5x, meaning the model size was reduced by more than half without a significant drop in performance. This could make it easier to deploy these powerful language models on a wider range of devices and applications, such as in mobile devices or embedded systems.
Technical Explanation
The key technical innovation in Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging is the use of manifold alignment to identify and merge similar layers in large language models.
The researchers first extract the activation patterns (the internal representations) of each layer in the model. They then use a technique called Canonical Correlation Analysis (CCA) to align the manifolds of these activation patterns across layers. This allows them to quantify the similarity between layers and identify which ones are redundant or performing similar functions.
Once the similar layers are identified, the researchers merge them together by averaging their weights and biases. This reduces the overall number of parameters in the model, leading to a more compact architecture without significant performance degradation.
The researchers tested this approach on popular language models like GPT-2 and BERT, and were able to achieve compression ratios of up to 2.5x. This means the model size was reduced by more than 50% while maintaining most of the original performance.
Critical Analysis
The Pruning via Merging technique presented in the paper is a promising approach for compressing large language models, but it does have some limitations and potential issues to consider.
One concern is the reliance on Canonical Correlation Analysis (CCA) for manifold alignment. CCA can be sensitive to hyperparameter choices and may not always accurately capture the true similarity between layers. The researchers acknowledge this and suggest exploring alternative alignment methods in future work.
Additionally, the merging process itself may lead to a loss of specialized functionality in certain layers, which could impact the model's performance on specific tasks. The researchers try to mitigate this by only merging layers that are highly similar, but there may still be some tradeoffs in terms of model capabilities.
It's also worth noting that the compression ratios achieved, while significant, may not be sufficient for all deployment scenarios, especially on resource-constrained devices. Further research into even more aggressive compression techniques, potentially in combination with other pruning and quantization methods, could be valuable.
Overall, the Pruning via Merging approach is a promising step forward in the field of language model compression, but there is still room for improvement and further exploration.
Conclusion
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging presents a novel technique for compressing large language models by identifying and merging similar layers using manifold alignment. This can lead to significant reductions in model size, up to 2.5x, without major performance degradation.
The ability to efficiently compress language models is crucial for deploying these powerful AI systems on a wider range of devices and applications, including mobile devices and embedded systems. While the Pruning via Merging approach has some limitations, it represents an important step forward in the field of model compression and could inspire further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Streamlining Redundant Layers to Compress Large Language Models
Xiaodong Chen, Yuxuan Hu, Jing Zhang, Yanling Wang, Cuiping Li, Hong Chen
0
0
This paper introduces LLM-Streamline, a novel layer pruning approach for large language models. It is based on the observation that different layers have varying impacts on hidden states, enabling the identification of less important layers. LLMStreamline comprises two parts: layer pruning, which removes consecutive layers with the lowest importance based on target sparsity, and layer replacement, where a lightweight network is trained to replace the pruned layers to mitigate performance loss. Additionally, a new metric called stability is proposed to address the limitations of accuracy in evaluating model compression. Experiments show that LLM-Streamline surpasses previous state-of-the-art pruning methods in both accuracy and stability.
5/24/2024
💬
Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen
0
0
The popularity of LLaMA (Touvron et al., 2023a;b) and other recently emerged moderate-sized large language models (LLMs) highlights the potential of building smaller yet powerful LLMs. Regardless, the cost of training such models from scratch on trillions of tokens remains high. In this work, we study structured pruning as an effective means to develop smaller LLMs from pre-trained, larger models. Our approach employs two key techniques: (1) targeted structured pruning, which prunes a larger model to a specified target shape by removing layers, heads, and intermediate and hidden dimensions in an end-to-end manner, and (2) dynamic batch loading, which dynamically updates the composition of sampled data in each training batch based on varying losses across different domains. We demonstrate the efficacy of our approach by presenting the Sheared-LLaMA series, pruning the LLaMA2-7B model down to 1.3B and 2.7B parameters. Sheared-LLaMA models outperform state-of-the-art open-source models of equivalent sizes, such as Pythia, INCITE, OpenLLaMA and the concurrent TinyLlama models, on a wide range of downstream and instruction tuning evaluations, while requiring only 3% of compute compared to training such models from scratch. This work provides compelling evidence that leveraging existing LLMs with structured pruning is a far more cost-effective approach for building competitive small-scale LLMs
4/12/2024
Large Language Model Pruning
Hanjuan Huang (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hao-Jia Song (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hsing-Kuo Pao (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan)
0
0
We surely enjoy the larger the better models for their superior performance in the last couple of years when both the hardware and software support the birth of such extremely huge models. The applied fields include text mining and others. In particular, the success of LLMs on text understanding and text generation draws attention from researchers who have worked on NLP and related areas for years or even decades. On the side, LLMs may suffer from problems like model overfitting, hallucination, and device limitation to name a few. In this work, we suggest a model pruning technique specifically focused on LLMs. The proposed methodology emphasizes the explainability of deep learning models. By having the theoretical foundation, we obtain a trustworthy deep model so that huge models with a massive number of model parameters become not quite necessary. A mutual information-based estimation is adopted to find neurons with redundancy to eliminate. Moreover, an estimator with well-tuned parameters helps to find precise estimation to guide the pruning procedure. At the same time, we also explore the difference between pruning on large-scale models vs. pruning on small-scale models. The choice of pruning criteria is sensitive in small models but not for large-scale models. It is a novel finding through this work. Overall, we demonstrate the superiority of the proposed model to the state-of-the-art models.
6/4/2024
💬
CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks
Andrei Tomut, Saeed S. Jahromi, Abhijoy Sarkar, Uygar Kurt, Sukhbinder Singh, Faysal Ishtiaq, Cesar Mu~noz, Prabdeep Singh Bajaj, Ali Elborady, Gianni del Bimbo, Mehrazin Alizadeh, David Montero, Pablo Martin-Ramiro, Muhammad Ibrahim, Oussama Tahiri Alaoui, John Malcolm, Samuel Mugel, Roman Orus
0
0
Large Language Models (LLMs) such as ChatGPT and LlaMA are advancing rapidly in generative Artificial Intelligence (AI), but their immense size poses significant challenges, such as huge training and inference costs, substantial energy demands, and limitations for on-site deployment. Traditional compression methods such as pruning, distillation, and low-rank approximation focus on reducing the effective number of neurons in the network, while quantization focuses on reducing the numerical precision of individual weights to reduce the model size while keeping the number of neurons fixed. While these compression methods have been relatively successful in practice, there is no compelling reason to believe that truncating the number of neurons is an optimal strategy. In this context, this paper introduces CompactifAI, an innovative LLM compression approach using quantum-inspired Tensor Networks that focuses on the model's correlation space instead, allowing for a more controlled, refined and interpretable model compression. Our method is versatile and can be implemented with - or on top of - other compression techniques. As a benchmark, we demonstrate that a combination of CompactifAI with quantization allows to reduce a 93% the memory size of LlaMA 7B, reducing also 70% the number of parameters, accelerating 50% the training and 25% the inference times of the model, and just with a small accuracy drop of 2% - 3%, going much beyond of what is achievable today by other compression techniques. Our methods also allow to perform a refined layer sensitivity profiling, showing that deeper layers tend to be more suitable for tensor network compression, which is compatible with recent observations on the ineffectiveness of those layers for LLM performance. Our results imply that standard LLMs are, in fact, heavily overparametrized, and do not need to be large at all.
5/14/2024