Streamlining Redundant Layers to Compress Large Language Models
2403.19135
0
0
Abstract
This paper introduces LLM-Streamline, a novel layer pruning approach for large language models. It is based on the observation that different layers have varying impacts on hidden states, enabling the identification of less important layers. LLMStreamline comprises two parts: layer pruning, which removes consecutive layers with the lowest importance based on target sparsity, and layer replacement, where a lightweight network is trained to replace the pruned layers to mitigate performance loss. Additionally, a new metric called stability is proposed to address the limitations of accuracy in evaluating model compression. Experiments show that LLM-Streamline surpasses previous state-of-the-art pruning methods in both accuracy and stability.
Create account to get full access
Overview
- This paper proposes a method for compressing large language models by streamlining the unimportant layers.
- The key idea is to identify and remove the least important layers in the model, which can significantly reduce the model size without significantly impacting performance.
- The authors evaluate their approach on various language tasks and show that it can achieve substantial compression rates while maintaining high accuracy.
Plain English Explanation
Large language models like BERT and GPT-3 have become increasingly powerful and useful, but they also require a lot of computational resources to run. This can be a problem, especially on devices with limited processing power like smartphones or embedded systems.
The authors of this paper have come up with a way to make these large models smaller and more efficient to run, without losing too much of their performance. The key idea is to identify the "unimportant" layers in the model - the ones that don't contribute much to the overall performance - and remove them. This way, you end up with a smaller, more streamlined model that can run faster and use less memory, while still maintaining most of the original model's capabilities.
The authors tested their approach on a variety of language tasks, and found that they could achieve significant compression rates (up to 50% or more) while only losing a small amount of accuracy. This could be really helpful for deploying large language models on resource-constrained devices or in applications where speed and efficiency are important.
Technical Explanation
The paper proposes a method for compressing large language models by streamlining the unimportant layers. The authors start by training a large, high-performance language model using standard techniques. They then analyze the importance of each layer in the model, identifying the layers that contribute the least to the overall performance.
Next, they remove these "unimportant" layers, resulting in a smaller and more efficient model. This process is inspired by techniques like pruning and model distillation, but the key innovation is the way they determine which layers are unimportant.
The authors evaluate their approach on a range of language tasks, including text classification, question answering, and natural language inference. They show that their compressed models can achieve substantial reductions in size (up to 50% or more) while maintaining high accuracy, outperforming other compression techniques like simple pruning.
Critical Analysis
The paper presents a promising approach for compressing large language models, but there are a few potential limitations and areas for further research:
-
Layer importance estimation: The method for identifying unimportant layers relies on analyzing the contribution of each layer to the overall model performance. While the authors' approach seems effective, there may be more sophisticated ways to measure layer importance that could further improve the compression rates.
-
Task-specific optimization: The compression technique is evaluated on a range of language tasks, but it's possible that the optimal layer removal strategy could vary depending on the specific task or application. Exploring task-specific compression methods could lead to even more efficient models.
-
Hardware-aware optimization: The paper focuses on reducing the overall model size, but in some cases, it may be more important to optimize for specific hardware constraints, such as memory usage or inference latency. Incorporating hardware-aware optimization into the compression process could lead to even more practical and impactful results.
-
Generalization to other model architectures: The experiments in the paper are limited to transformer-based language models, but it would be valuable to see how the compression technique performs on other model architectures, such as recurrent neural networks or convolutional neural networks.
Overall, the paper presents a compelling approach to compressing large language models, and the results suggest that it could have significant practical applications. However, further research and refinement of the technique could lead to even more efficient and versatile models.
Conclusion
This paper introduces a novel method for compressing large language models by selectively removing the least important layers in the model. By identifying and removing these "unimportant" layers, the authors are able to achieve substantial reductions in model size (up to 50% or more) while maintaining high accuracy across a range of language tasks.
The key innovation of this work is the way it determines the importance of each layer, which allows for more targeted and effective compression compared to simpler pruning or distillation techniques. This could have important implications for deploying large language models on resource-constrained devices or in applications where speed and efficiency are critical.
While the paper presents promising results, there are also opportunities for further research and refinement, such as exploring more advanced layer importance estimation methods, task-specific optimization, and hardware-aware compression. Overall, this work represents an important step forward in making large language models more practical and accessible for a wider range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
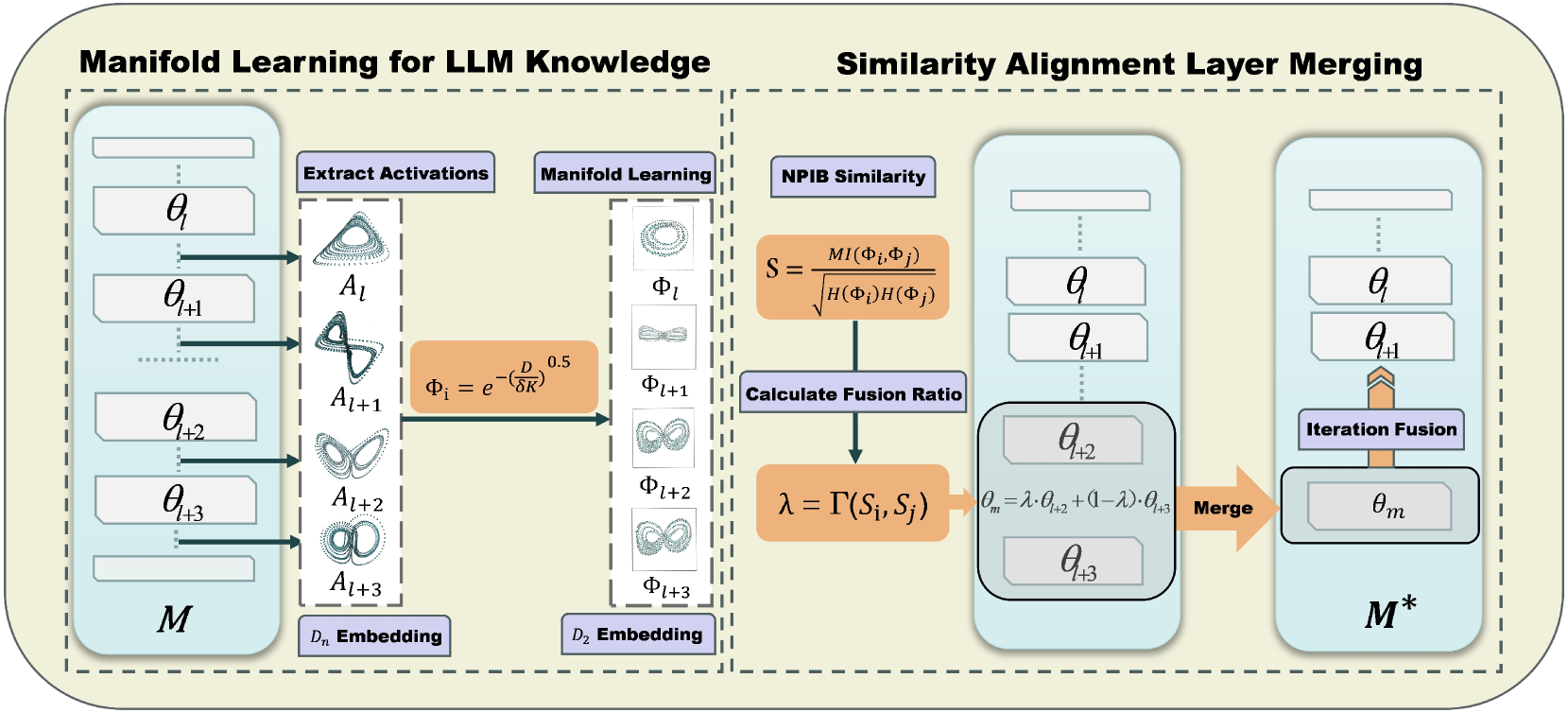
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging
Deyuan Liu, Zhanyue Qin, Hairu Wang, Zhao Yang, Zecheng Wang, Fangying Rong, Qingbin Liu, Yanchao Hao, Xi Chen, Cunhang Fan, Zhao Lv, Zhiying Tu, Dianhui Chu, Bo Li, Dianbo Sui
0
0
While large language models (LLMs) excel in many domains, their complexity and scale challenge deployment in resource-limited environments. Current compression techniques, such as parameter pruning, often fail to effectively utilize the knowledge from pruned parameters. To address these challenges, we propose Manifold-Based Knowledge Alignment and Layer Merging Compression (MKA), a novel approach that uses manifold learning and the Normalized Pairwise Information Bottleneck (NPIB) measure to merge similar layers, reducing model size while preserving essential performance. We evaluate MKA on multiple benchmark datasets and various LLMs. Our findings show that MKA not only preserves model performance but also achieves substantial compression ratios, outperforming traditional pruning methods. Moreover, when coupled with quantization, MKA delivers even greater compression. Specifically, on the MMLU dataset using the Llama3-8B model, MKA achieves a compression ratio of 43.75% with a minimal performance decrease of only 2.82%. The proposed MKA method offers a resource-efficient and performance-preserving model compression technique for LLMs.
6/26/2024
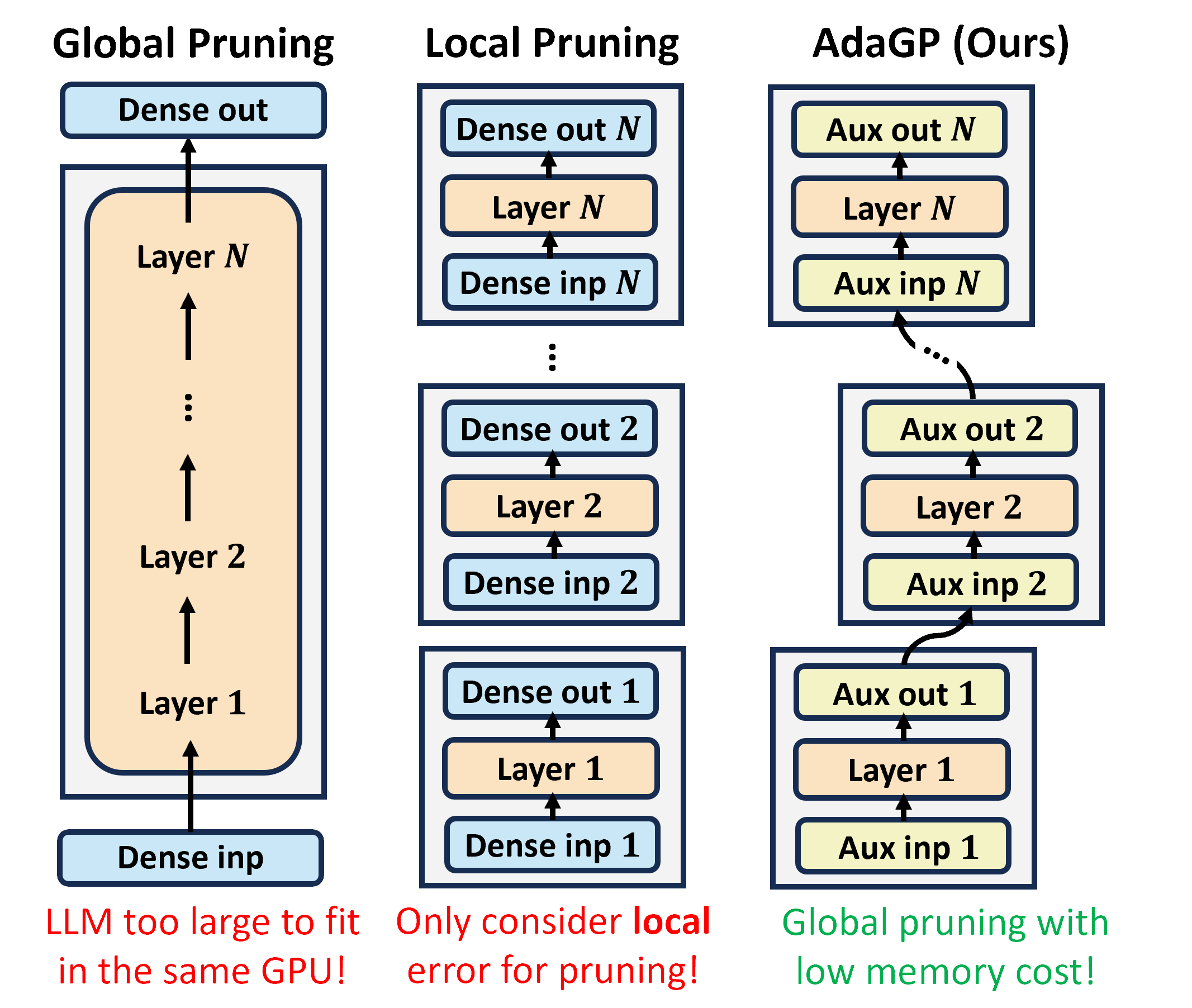
SparseLLM: Towards Global Pruning for Pre-trained Language Models
Guangji Bai, Yijiang Li, Chen Ling, Kibaek Kim, Liang Zhao
0
0
The transformative impact of large language models (LLMs) like LLaMA and GPT on natural language processing is countered by their prohibitive computational demands. Pruning has emerged as a pivotal compression strategy, introducing sparsity to enhance both memory and computational efficiency. Yet, traditional global pruning is impractical for LLMs due to scalability issues, while local pruning, despite its efficiency, leads to suboptimal solutions. Addressing these challenges, we propose SparseLLM, a novel framework that redefines the global pruning process into manageable, coordinated subproblems, allowing for resource-efficient optimization with global optimality. SparseLLM's approach, which conceptualizes LLMs as a chain of modular functions and leverages auxiliary variables for problem decomposition, not only facilitates a pragmatic application on LLMs but also demonstrates significant performance improvements, particularly in high-sparsity regimes where it surpasses current state-of-the-art methods.
5/27/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024

Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
0
0
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
5/16/2024