Pseudo-label Based Domain Adaptation for Zero-Shot Text Steganalysis

0
Sign in to get full access
Overview
- This paper proposes a pseudo-label-based domain adaptation approach for zero-shot text steganalysis, which aims to detect hidden messages in text without any labeled data from the target domain.
- The method uses self-training to generate pseudo-labels for the target domain, which are then used to fine-tune a pre-trained model to improve its performance on the target domain.
- The approach is evaluated on two real-world datasets and shows significant improvements over existing zero-shot and domain adaptation techniques for text steganalysis.
Plain English Explanation
In the field of text steganalysis, the goal is to detect hidden messages in text. This can be challenging when you don't have any labeled data from the target domain (the specific type of text you're trying to analyze).
The researchers in this paper developed a new approach to tackle this problem. They use a technique called "self-training" to generate their own "pseudo-labels" for the target domain data. These pseudo-labels are essentially the researchers' best guesses about whether the text contains a hidden message or not.
Once they have these pseudo-labels, the researchers can use them to fine-tune a pre-trained model, helping it become better at detecting hidden messages in the target domain. This "pseudo-label-based domain adaptation" allows the model to adapt to the target domain without any labeled data from that domain.
The researchers tested their approach on two real-world datasets and found that it significantly outperformed existing zero-shot and domain adaptation techniques for text steganalysis. In other words, their method was much better at detecting hidden messages in new types of text, even when they didn't have any labeled examples from that text.
Technical Explanation
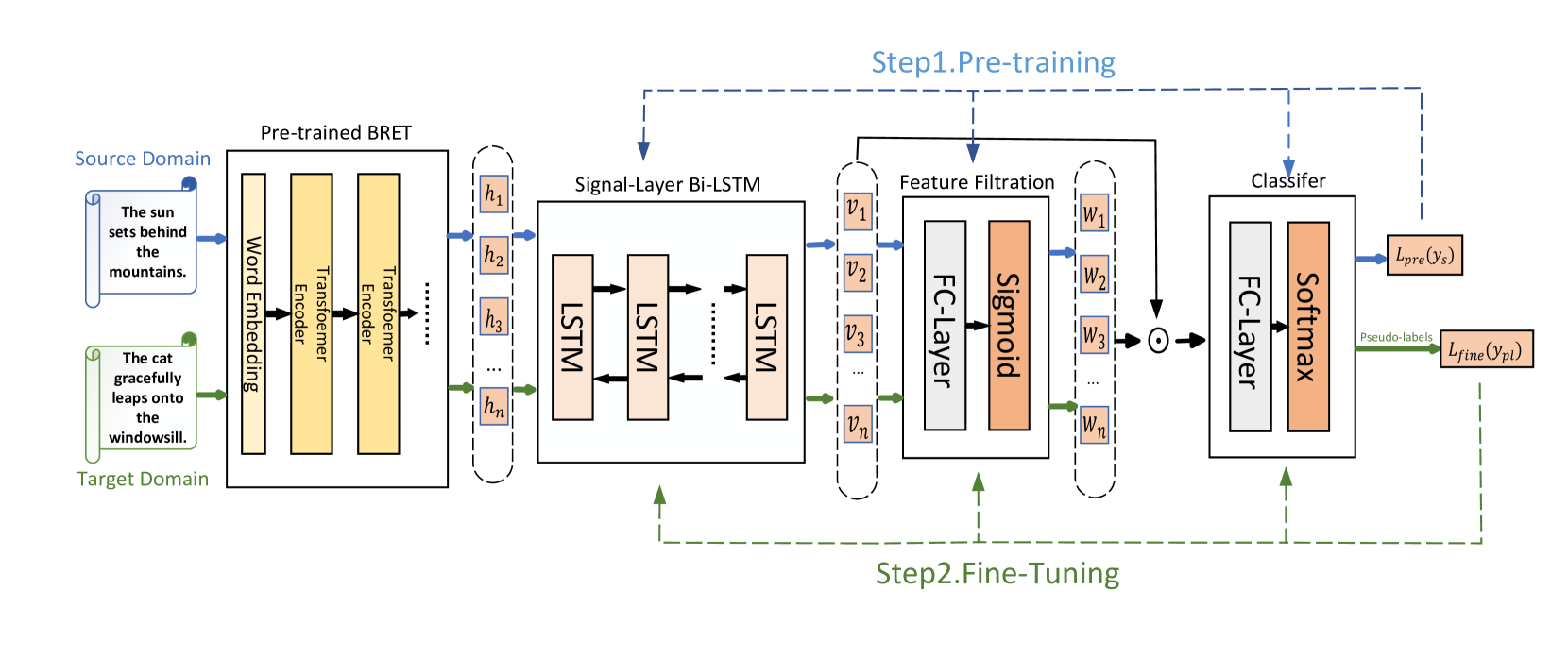
The paper proposes a pseudo-label-based domain adaptation approach for zero-shot text steganalysis. The key components of the method are:
-
Pre-trained Model: The researchers start with a pre-trained text steganalysis model, which has been trained on labeled data from a source domain.
-
Pseudo-Label Generation: For the target domain, where no labeled data is available, the researchers use self-training to generate pseudo-labels. They first use the pre-trained model to make predictions on the target domain data, and then select the most confident predictions to serve as pseudo-labels.
-
Fine-tuning: The researchers then fine-tune the pre-trained model using the pseudo-labeled target domain data, allowing the model to adapt to the characteristics of the target domain.
The method is evaluated on two real-world text steganalysis datasets: BOSS and TwitInS. The results show that the proposed pseudo-label-based domain adaptation approach significantly outperforms existing zero-shot and domain adaptation techniques for text steganalysis.
Critical Analysis
The paper presents a novel and effective approach for addressing the challenge of zero-shot text steganalysis. The key strength of the method is its ability to adapt to the target domain without any labeled data, which is a common problem in real-world applications.
However, the paper does not fully address the potential limitations of the pseudo-label generation process. The quality of the pseudo-labels is crucial to the success of the fine-tuning step, and the paper could have provided more insights into the factors that influence the reliability of the pseudo-labels.
Additionally, the paper could have explored the generalizability of the approach by evaluating it on a wider range of text steganalysis datasets, including those with different characteristics or from different domains. This could help identify potential limitations or boundary conditions of the proposed method.
Further research could also investigate ways to improve the pseudo-label generation process, such as incorporating uncertainty estimates or leveraging additional unlabeled data, as seen in techniques like source-free domain adaptation or unsupervised domain adaptation.
Conclusion
This paper presents a novel pseudo-label-based domain adaptation approach for zero-shot text steganalysis. The method effectively leverages self-training to generate pseudo-labels for the target domain, which are then used to fine-tune a pre-trained model and improve its performance on the target domain.
The results demonstrate significant improvements over existing zero-shot and domain adaptation techniques, highlighting the potential of this approach for real-world applications where labeled data from the target domain is scarce or unavailable. While the paper could have explored some additional aspects, it represents an important contribution to the field of text steganalysis and domain adaptation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pseudo-label Based Domain Adaptation for Zero-Shot Text Steganalysis
Yufei Luo, Zhen Yang, Ru Zhang, Jianyi Liu
Currently, most methods for text steganalysis are based on deep neural networks (DNNs). However, in real-life scenarios, obtaining a sufficient amount of labeled stego-text for correctly training networks using a large number of parameters is often challenging and costly. Additionally, due to a phenomenon known as dataset bias or domain shift, recognition models trained on a large dataset exhibit poor generalization performance on novel datasets and tasks. Therefore, to address the issues of missing labeled data and inadequate model generalization in text steganalysis, this paper proposes a cross-domain stego-text analysis method (PDTS) based on pseudo-labeling and domain adaptation (unsupervised learning). Specifically, we propose a model architecture combining pre-trained BERT with a single-layer Bi-LSTM to learn and extract generic features across tasks and generate task-specific representations. Considering the differential contributions of different features to steganalysis, we further design a feature filtering mechanism to achieve selective feature propagation, thereby enhancing classification performance. We train the model using labeled source domain data and adapt it to target domain data distribution using pseudo-labels for unlabeled target domain data through self-training. In the label estimation step, instead of using a static sampling strategy, we propose a progressive sampling strategy to gradually increase the number of selected pseudo-label candidates. Experimental results demonstrate that our method performs well in zero-shot text steganalysis tasks, achieving high detection accuracy even in the absence of labeled data in the target domain, and outperforms current zero-shot text steganalysis methods.
Read more6/28/2024
🏷️
0
A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification
Yunlong Feng, Bohan Li, Libo Qin, Xiao Xu, Wanxiang Che
Cross-domain text classification aims to adapt models to a target domain that lacks labeled data. It leverages or reuses rich labeled data from the different but related source domain(s) and unlabeled data from the target domain. To this end, previous work focuses on either extracting domain-invariant features or task-agnostic features, ignoring domain-aware features that may be present in the target domain and could be useful for the downstream task. In this paper, we propose a two-stage framework for cross-domain text classification. In the first stage, we finetune the model with mask language modeling (MLM) and labeled data from the source domain. In the second stage, we further fine-tune the model with self-supervised distillation (SSD) and unlabeled data from the target domain. We evaluate its performance on a public cross-domain text classification benchmark and the experiment results show that our method achieves new state-of-the-art results for both single-source domain adaptations (94.17% $uparrow$1.03%) and multi-source domain adaptations (95.09% $uparrow$1.34%).
Read more4/11/2024
👀
0
Source-Free Domain Adaptation Guided by Vision and Vision-Language Pre-Training
Wenyu Zhang, Li Shen, Chuan-Sheng Foo
Source-free domain adaptation (SFDA) aims to adapt a source model trained on a fully-labeled source domain to a related but unlabeled target domain. While the source model is a key avenue for acquiring target pseudolabels, the generated pseudolabels may exhibit source bias. In the conventional SFDA pipeline, a large data (e.g. ImageNet) pre-trained feature extractor is used to initialize the source model at the start of source training, and subsequently discarded. Despite having diverse features important for generalization, the pre-trained feature extractor can overfit to the source data distribution during source training and forget relevant target domain knowledge. Rather than discarding this valuable knowledge, we introduce an integrated framework to incorporate pre-trained networks into the target adaptation process. The proposed framework is flexible and allows us to plug modern pre-trained networks into the adaptation process to leverage their stronger representation learning capabilities. For adaptation, we propose the Co-learn algorithm to improve target pseudolabel quality collaboratively through the source model and a pre-trained feature extractor. Building on the recent success of the vision-language model CLIP in zero-shot image recognition, we present an extension Co-learn++ to further incorporate CLIP's zero-shot classification decisions. We evaluate on 4 benchmark datasets and include more challenging scenarios such as open-set, partial-set and open-partial SFDA. Experimental results demonstrate that our proposed strategy improves adaptation performance and can be successfully integrated with existing SFDA methods.
Read more8/22/2024
0
Zero-shot domain adaptation based on dual-level mix and contrast
Yu Zhe, Jun Sakuma
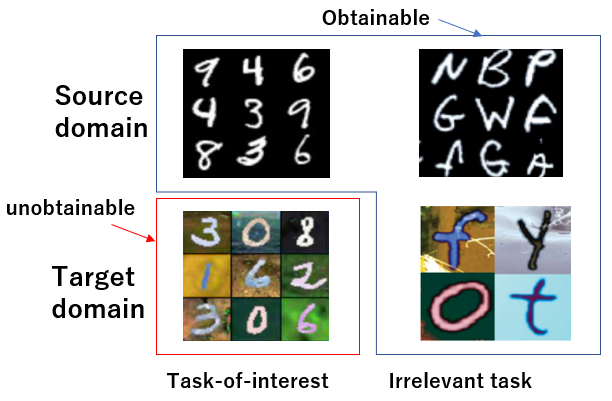
Zero-shot domain adaptation (ZSDA) is a domain adaptation problem in the situation that labeled samples for a target task (task of interest) are only available from the source domain at training time, but for a task different from the task of interest (irrelevant task), labeled samples are available from both source and target domains. In this situation, classical domain adaptation techniques can only learn domain-invariant features in the irrelevant task. However, due to the difference in sample distribution between the two tasks, domain-invariant features learned in the irrelevant task are biased and not necessarily domain-invariant in the task of interest. To solve this problem, this paper proposes a new ZSDA method to learn domain-invariant features with low task bias. To this end, we propose (1) data augmentation with dual-level mixups in both task and domain to fill the absence of target task-of-interest data, (2) an extension of domain adversarial learning to learn domain-invariant features with less task bias, and (3) a new dual-level contrastive learning method that enhances domain-invariance and less task biasedness of features. Experimental results show that our proposal achieves good performance on several benchmarks.
Read more6/28/2024