A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification

0
🏷️
Sign in to get full access
Overview
- Cross-domain text classification aims to adapt machine learning models to a target domain that lacks labeled data
- This is done by leveraging rich labeled data from a different but related source domain, as well as unlabeled data from the target domain
- Previous approaches have focused on extracting domain-invariant or task-agnostic features, but may have missed useful domain-aware features in the target domain
Plain English Explanation
Cross-domain text classification is a machine learning technique that allows models to be used effectively on new datasets, even if those datasets don't have labeled examples. This is done by taking advantage of data from a related "source" dataset that does have labeled examples, as well as unlabeled data from the new "target" dataset.
Previous methods have tried to find features that are consistent across the source and target domains, or features that are general to the task at hand. However, this paper proposes that there may also be useful features that are specific to the target domain, and these should not be ignored.
Technical Explanation
The paper introduces a two-stage framework for cross-domain text classification. In the first stage, the model is fine-tuned using mask language modeling (MLM) and labeled data from the source domain. This helps the model learn general language understanding.
In the second stage, the model is further fine-tuned using self-supervised distillation (SSD) and unlabeled data from the target domain. This allows the model to learn features that are specific to the target domain, which can then be leveraged for the final classification task.
The researchers evaluate this approach on a standard cross-domain text classification benchmark, and find that it outperforms previous state-of-the-art methods for both single-source and multi-source domain adaptations.
Critical Analysis
The paper makes a compelling case that leveraging domain-aware features in addition to domain-invariant and task-agnostic features can lead to improved cross-domain text classification performance. However, the authors do not extensively explore the types of domain-aware features that are being learned, or provide much insight into why this approach is effective.
Additionally, the experiments are limited to academic benchmark datasets, and it's unclear how well the approach would generalize to real-world applications with more diverse target domains. Further research may be needed to understand the broader applicability and limitations of this technique.
Conclusion
This paper proposes a novel two-stage framework for cross-domain text classification that aims to capture both domain-invariant and domain-aware features. The experimental results demonstrate significant performance improvements over previous state-of-the-art methods, suggesting that this approach could be a valuable tool for adapting natural language processing models to new datasets and applications. The insights from this work may also inspire further research into leveraging domain-specific information for cross-domain learning tasks, as described in related work such as Language-Guided Instance-Aware Domain Adaptive Panoptic Segmentation and Unified Language-Driven Zero-Shot Domain Adaptation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification
Yunlong Feng, Bohan Li, Libo Qin, Xiao Xu, Wanxiang Che
Cross-domain text classification aims to adapt models to a target domain that lacks labeled data. It leverages or reuses rich labeled data from the different but related source domain(s) and unlabeled data from the target domain. To this end, previous work focuses on either extracting domain-invariant features or task-agnostic features, ignoring domain-aware features that may be present in the target domain and could be useful for the downstream task. In this paper, we propose a two-stage framework for cross-domain text classification. In the first stage, we finetune the model with mask language modeling (MLM) and labeled data from the source domain. In the second stage, we further fine-tune the model with self-supervised distillation (SSD) and unlabeled data from the target domain. We evaluate its performance on a public cross-domain text classification benchmark and the experiment results show that our method achieves new state-of-the-art results for both single-source domain adaptations (94.17% $uparrow$1.03%) and multi-source domain adaptations (95.09% $uparrow$1.34%).
Read more4/11/2024
0
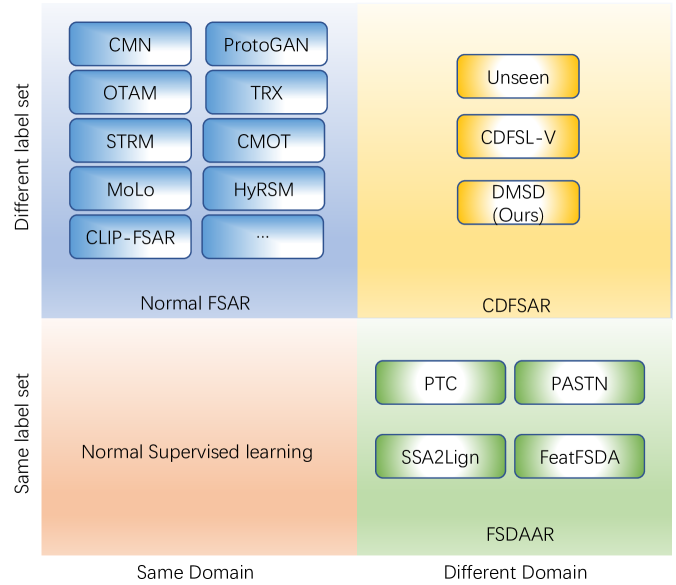
DMSD-CDFSAR: Distillation from Mixed-Source Domain for Cross-Domain Few-shot Action Recognition
Fei Guo, YiKang Wang, Han Qi, Li Zhu, Jing Sun
Few-shot action recognition is an emerging field in computer vision, primarily focused on meta-learning within the same domain. However, challenges arise in real-world scenario deployment, as gathering extensive labeled data within a specific domain is laborious and time-intensive. Thus, attention shifts towards cross-domain few-shot action recognition, requiring the model to generalize across domains with significant deviations. Therefore, we propose a novel approach, ``Distillation from Mixed-Source Domain, tailored to address this conundrum. Our method strategically integrates insights from both labeled data of the source domain and unlabeled data of the target domain during the training. The ResNet18 is used as the backbone to extract spatial features from the source and target domains. We design two branches for meta-training: the original-source and the mixed-source branches. In the first branch, a Domain Temporal Encoder is employed to capture temporal features for both the source and target domains. Additionally, a Domain Temporal Decoder is employed to reconstruct all extracted features. In the other branch, a Domain Mixed Encoder is used to handle labeled source domain data and unlabeled target domain data, generating mixed-source domain features. We incorporate a pre-training stage before meta-training, featuring a network architecture similar to that of the first branch. Lastly, we introduce a dual distillation mechanism to refine the classification probabilities of source domain features, aligning them with those of mixed-source domain features. This iterative process enriches the insights of the original-source branch with knowledge from the mixed-source branch, thereby enhancing the model's generalization capabilities. Our code is available at URL: url{https://xxxx/xxxx/xxxx.git}
Read more7/9/2024
0
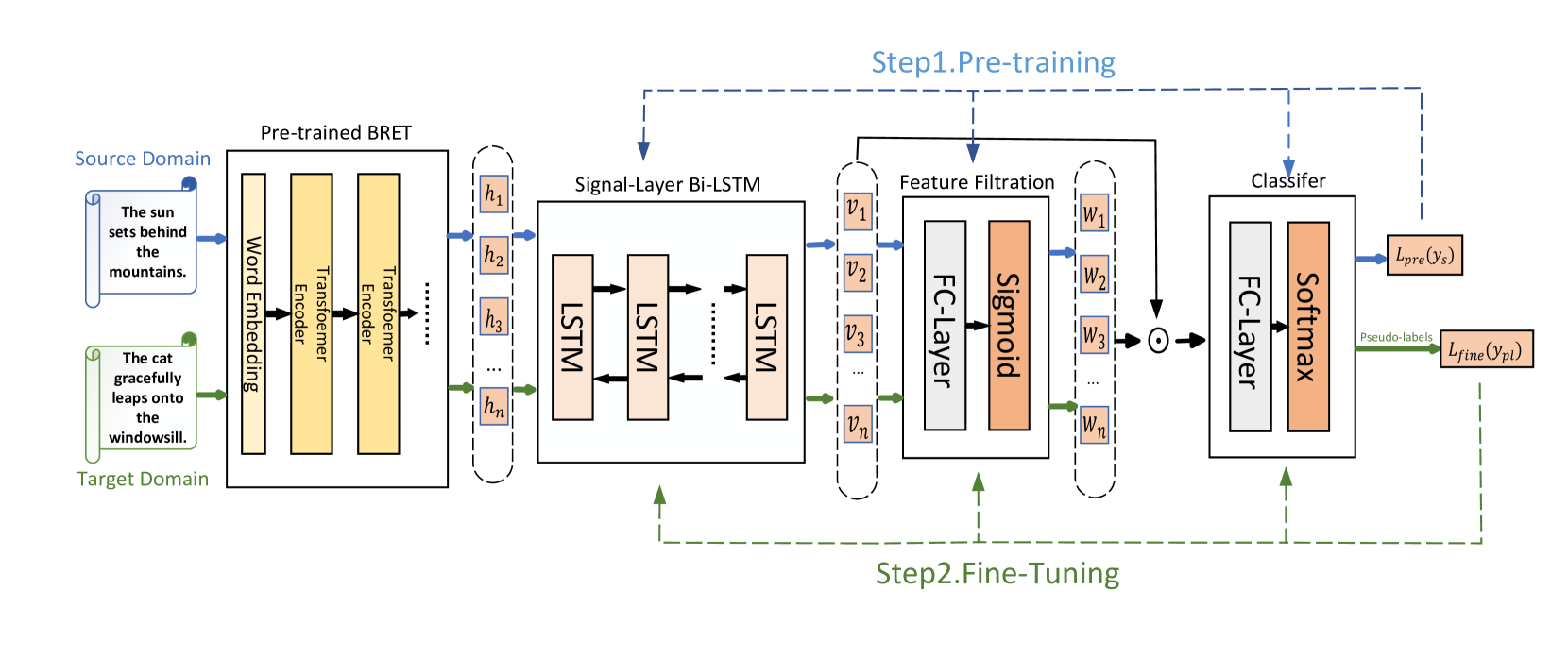
Pseudo-label Based Domain Adaptation for Zero-Shot Text Steganalysis
Yufei Luo, Zhen Yang, Ru Zhang, Jianyi Liu
Currently, most methods for text steganalysis are based on deep neural networks (DNNs). However, in real-life scenarios, obtaining a sufficient amount of labeled stego-text for correctly training networks using a large number of parameters is often challenging and costly. Additionally, due to a phenomenon known as dataset bias or domain shift, recognition models trained on a large dataset exhibit poor generalization performance on novel datasets and tasks. Therefore, to address the issues of missing labeled data and inadequate model generalization in text steganalysis, this paper proposes a cross-domain stego-text analysis method (PDTS) based on pseudo-labeling and domain adaptation (unsupervised learning). Specifically, we propose a model architecture combining pre-trained BERT with a single-layer Bi-LSTM to learn and extract generic features across tasks and generate task-specific representations. Considering the differential contributions of different features to steganalysis, we further design a feature filtering mechanism to achieve selective feature propagation, thereby enhancing classification performance. We train the model using labeled source domain data and adapt it to target domain data distribution using pseudo-labels for unlabeled target domain data through self-training. In the label estimation step, instead of using a static sampling strategy, we propose a progressive sampling strategy to gradually increase the number of selected pseudo-label candidates. Experimental results demonstrate that our method performs well in zero-shot text steganalysis tasks, achieving high detection accuracy even in the absence of labeled data in the target domain, and outperforms current zero-shot text steganalysis methods.
Read more6/28/2024
0
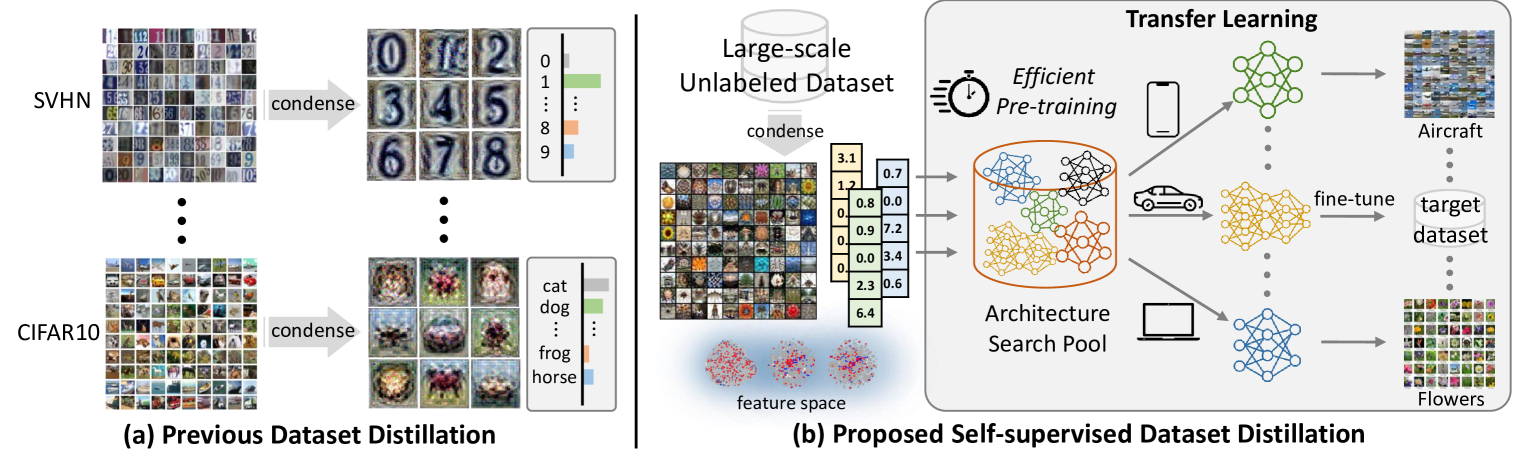
Self-Supervised Dataset Distillation for Transfer Learning
Dong Bok Lee, Seanie Lee, Joonho Ko, Kenji Kawaguchi, Juho Lee, Sung Ju Hwang
Dataset distillation methods have achieved remarkable success in distilling a large dataset into a small set of representative samples. However, they are not designed to produce a distilled dataset that can be effectively used for facilitating self-supervised pre-training. To this end, we propose a novel problem of distilling an unlabeled dataset into a set of small synthetic samples for efficient self-supervised learning (SSL). We first prove that a gradient of synthetic samples with respect to a SSL objective in naive bilevel optimization is textit{biased} due to the randomness originating from data augmentations or masking. To address this issue, we propose to minimize the mean squared error (MSE) between a model's representations of the synthetic examples and their corresponding learnable target feature representations for the inner objective, which does not introduce any randomness. Our primary motivation is that the model obtained by the proposed inner optimization can mimic the textit{self-supervised target model}. To achieve this, we also introduce the MSE between representations of the inner model and the self-supervised target model on the original full dataset for outer optimization. Lastly, assuming that a feature extractor is fixed, we only optimize a linear head on top of the feature extractor, which allows us to reduce the computational cost and obtain a closed-form solution of the head with kernel ridge regression. We empirically validate the effectiveness of our method on various applications involving transfer learning.
Read more4/15/2024