PSM: Learning Probabilistic Embeddings for Multi-scale Zero-Shot Soundscape Mapping

0

Sign in to get full access
Overview
- This paper presents a novel method called PSM (Probabilistic Soundscape Mapping) for learning probabilistic embeddings for multi-scale zero-shot soundscape mapping.
- The approach aims to capture the semantic and spatial relationships between sounds at different scales, enabling zero-shot transfer of sound knowledge to new environments.
- Key features include a multi-scale audio-visual representation learning framework and a probabilistic soundscape mapping module.
Plain English Explanation
The paper introduces a new technique called Probabilistic Soundscape Mapping (PSM) that can learn how different sounds are related to each other and their spatial locations, even for sounds it hasn't encountered before. This allows the system to understand and map out soundscapes in new environments without requiring extensive training data.
At the core of PSM is a way to represent sounds in a probabilistic "embedding" space. This embedding captures the semantic meaning and spatial relationships between different sounds, so the system can reason about how they might interact in a new setting. For example, it might know that the sound of a dog barking is likely to be near the sound of a person walking, even if it's never encountered that exact combination before.
The authors develop a multi-scale approach, which means the system can understand sounds at different levels of detail - from broad categories like "animal sounds" down to specific instances like "a poodle barking." This gives it more flexibility to apply its knowledge to diverse soundscapes.
By learning these rich, probabilistic representations of sounds and their spatial associations, the PSM system can be deployed in new environments and still make reasonably accurate guesses about what the soundscape might contain, without requiring extensive retraining. This "zero-shot" capability is a key advantage over previous approaches.
Technical Explanation
The core contribution of this paper is the Probabilistic Soundscape Mapping (PSM) framework, which learns probabilistic sound embeddings that capture semantic and spatial relationships between sounds at multiple scales.
At the heart of PSM is a multi-scale audio-visual representation learning module. This takes in audio data (e.g. recordings of different sounds) and visual data (e.g. images of the environments those sounds occur in) and learns a shared embedding space that represents the semantic meaning and spatial properties of the sounds.
The authors use a contrastive learning objective to push sounds with similar semantic meanings and spatial associations closer together in the embedding space, while pushing dissimilar sounds further apart. This allows the model to build rich probabilistic representations of sounds that encode both what they are and where they tend to occur.
Critically, the multi-scale nature of the embeddings means the model can reason about sounds at different levels of granularity - from broad sound categories down to specific instances. This enables zero-shot transfer, where the model can apply its learned knowledge about sound relationships to new environments it hasn't been explicitly trained on.
The paper also introduces a probabilistic soundscape mapping module that takes these learned sound embeddings and uses them to generate a probabilistic map of the likely soundscape in a new environment. This allows the model to make informed guesses about what sounds might be present and where, without requiring exhaustive training data for that specific location.
Overall, the PSM framework advances the state-of-the-art in audio-visual scene understanding, with the key novelty being the probabilistic, multi-scale approach to learning sound representations and spatial relationships.
Critical Analysis
The PSM approach demonstrated impressive zero-shot transfer capabilities, allowing the model to reason about soundscapes in new environments it had not been trained on. This is an important advance, as collecting comprehensive training data for acoustic scene understanding can be extremely challenging.
However, the paper does not provide a thorough analysis of the model's limitations or potential failure cases. For example, it's unclear how well PSM would perform in highly complex or noisy soundscapes, or how sensitive it is to variations in audio and visual data quality.
Additionally, while the multi-scale nature of the embeddings is a strength, the authors could have explored in more depth how the different scales interact and contribute to the overall performance. A deeper analysis of the tradeoffs and complementary roles of the coarse and fine-grained representations could provide valuable insights.
Finally, the paper does not discuss potential societal implications or ethical considerations around the use of such a system. As soundscape mapping could have applications in domains like urban planning or surveillance, it would be prudent for the authors to reflect on potential misuse cases and how to mitigate them.
Overall, the PSM framework represents an important advance in audio-visual scene understanding, but deeper examination of its limitations and broader impacts would strengthen the research.
Conclusion
This paper introduces a novel Probabilistic Soundscape Mapping (PSM) framework that learns rich, probabilistic embeddings to capture the semantic and spatial relationships between sounds at multiple scales. By leveraging these representations, the PSM system can effectively transfer its sound knowledge to new environments, enabling "zero-shot" soundscape mapping without requiring extensive retraining.
The key innovations include the multi-scale audio-visual representation learning module and the probabilistic soundscape mapping component. These allow the model to build versatile, hierarchical understandings of acoustic scenes that can generalize to novel settings.
While the paper demonstrates impressive results, further exploration of the model's limitations and potential societal impacts would help contextualize the significance of this work. Nonetheless, the PSM framework represents an important step forward in audio-visual scene understanding, with applications in areas like urban planning, environmental monitoring, and assistive technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PSM: Learning Probabilistic Embeddings for Multi-scale Zero-Shot Soundscape Mapping
Subash Khanal, Eric Xing, Srikumar Sastry, Aayush Dhakal, Zhexiao Xiong, Adeel Ahmad, Nathan Jacobs
A soundscape is defined by the acoustic environment a person perceives at a location. In this work, we propose a framework for mapping soundscapes across the Earth. Since soundscapes involve sound distributions that span varying spatial scales, we represent locations with multi-scale satellite imagery and learn a joint representation among this imagery, audio, and text. To capture the inherent uncertainty in the soundscape of a location, we design the representation space to be probabilistic. We also fuse ubiquitous metadata (including geolocation, time, and data source) to enable learning of spatially and temporally dynamic representations of soundscapes. We demonstrate the utility of our framework by creating large-scale soundscape maps integrating both audio and text with temporal control. To facilitate future research on this task, we also introduce a large-scale dataset, GeoSound, containing over $300k$ geotagged audio samples paired with both low- and high-resolution satellite imagery. We demonstrate that our method outperforms the existing state-of-the-art on both GeoSound and the existing SoundingEarth dataset. Our dataset and code is available at https://github.com/mvrl/PSM.
Read more8/14/2024

0
Soundscape Captioning using Sound Affective Quality Network and Large Language Model
Yuanbo Hou, Qiaoqiao Ren, Andrew Mitchell, Wenwu Wang, Jian Kang, Tony Belpaeme, Dick Botteldooren
We live in a rich and varied acoustic world, which is experienced by individuals or communities as a soundscape. Computational auditory scene analysis, disentangling acoustic scenes by detecting and classifying events, focuses on objective attributes of sounds, such as their category and temporal characteristics, ignoring the effect of sounds on people and failing to explore the relationship between sounds and the emotions they evoke within a context. To fill this gap and to automate soundscape analysis, which traditionally relies on labour-intensive subjective ratings and surveys, we propose the soundscape captioning (SoundSCap) task. SoundSCap generates context-aware soundscape descriptions by capturing the acoustic scene, event information, and the corresponding human affective qualities. To this end, we propose an automatic soundscape captioner (SoundSCaper) composed of an acoustic model, SoundAQnet, and a general large language model (LLM). SoundAQnet simultaneously models multi-scale information about acoustic scenes, events, and perceived affective qualities, while LLM generates soundscape captions by parsing the information captured by SoundAQnet to a common language. The soundscape caption's quality is assessed by a jury of 16 audio/soundscape experts. The average score (out of 5) of SoundSCaper-generated captions is lower than the score of captions generated by two soundscape experts by 0.21 and 0.25, respectively, on the evaluation set and the model-unknown mixed external dataset with varying lengths and acoustic properties, but the differences are not statistically significant. Overall, SoundSCaper-generated captions show promising performance compared to captions annotated by soundscape experts. The models' code, LLM scripts, human assessment data and instructions, and expert evaluation statistics are all publicly available.
Read more6/11/2024

0
Multi-scale Multi-instance Visual Sound Localization and Segmentation
Shentong Mo, Haofan Wang
Visual sound localization is a typical and challenging problem that predicts the location of objects corresponding to the sound source in a video. Previous methods mainly used the audio-visual association between global audio and one-scale visual features to localize sounding objects in each image. Despite their promising performance, they omitted multi-scale visual features of the corresponding image, and they cannot learn discriminative regions compared to ground truths. To address this issue, we propose a novel multi-scale multi-instance visual sound localization framework, namely M2VSL, that can directly learn multi-scale semantic features associated with sound sources from the input image to localize sounding objects. Specifically, our M2VSL leverages learnable multi-scale visual features to align audio-visual representations at multi-level locations of the corresponding image. We also introduce a novel multi-scale multi-instance transformer to dynamically aggregate multi-scale cross-modal representations for visual sound localization. We conduct extensive experiments on VGGSound-Instruments, VGG-Sound Sources, and AVSBench benchmarks. The results demonstrate that the proposed M2VSL can achieve state-of-the-art performance on sounding object localization and segmentation.
Read more9/4/2024
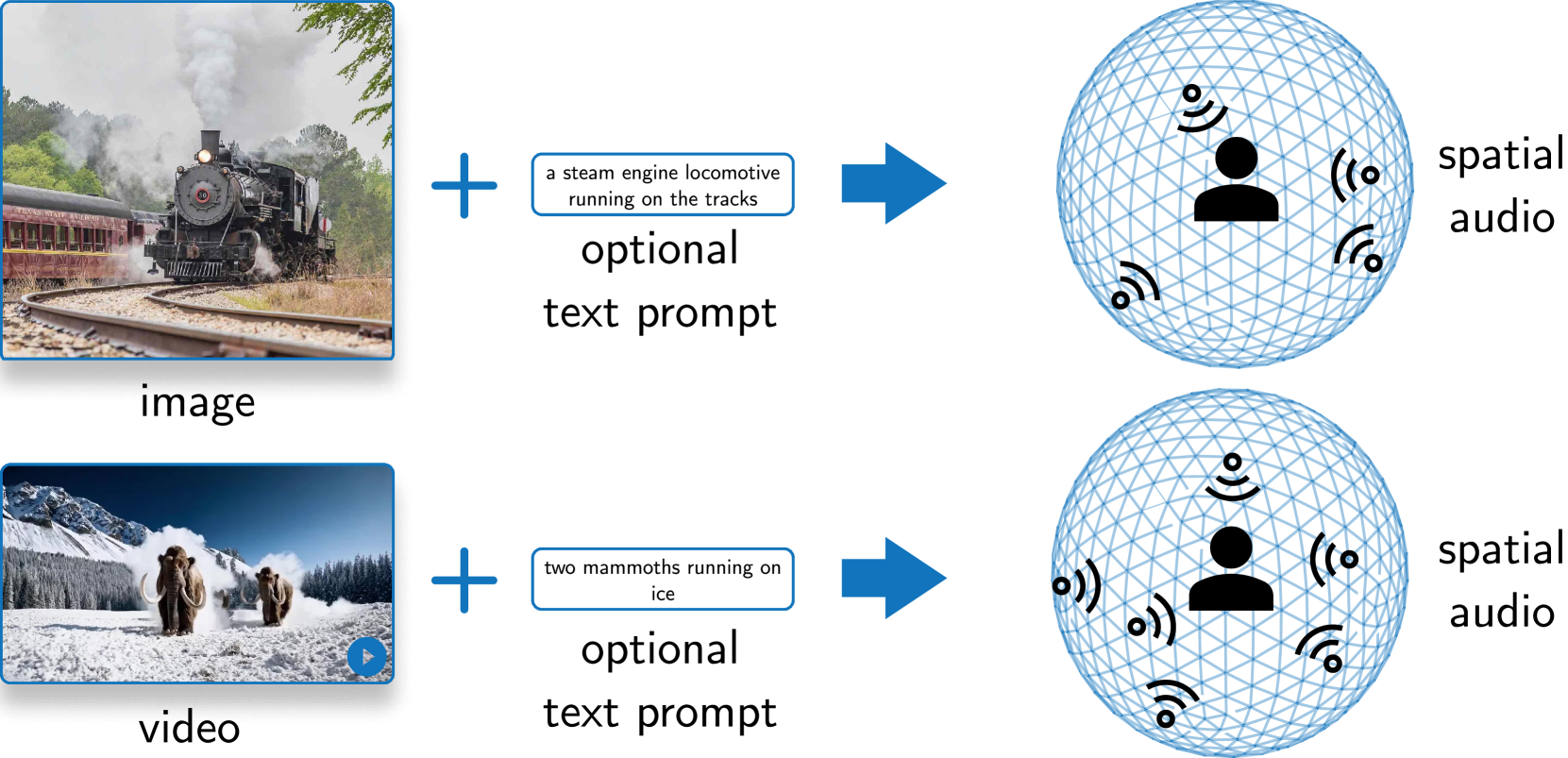
0
SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Rishit Dagli, Shivesh Prakash, Robert Wu, Houman Khosravani
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.
Read more6/12/2024