PULL: PU-Learning-based Accurate Link Prediction

0

Sign in to get full access
Overview
- This paper presents a new link prediction method called PULL (PU-Learning-based Accurate Link Prediction) that uses Positive-Unlabeled (PU) learning to improve the accuracy of link prediction in networks.
- Link prediction is the task of predicting whether two nodes in a network are connected or not, and has many applications in fields like social network analysis, recommendation systems, and knowledge graph completion.
- The key idea behind PULL is to treat the "negative" class (i.e., non-existent links) as "unlabeled" data, and then use PU learning techniques to train a more accurate link prediction model.
Plain English Explanation
In a network or graph, link prediction is the task of figuring out if two nodes (e.g., people, entities) are connected or not. This is useful for all kinds of applications, like recommending new friends on a social network or completing missing links in a knowledge graph.
The key challenge is that in a real-world network, we only have information about the existing connections (the "positive" links) - we don't have clear data on all the non-existent connections (the "negative" links). The PULL method tackles this by treating the non-existent links as "unlabeled" data, instead of treating them as definitive negatives.
PULL uses a Positive-Unlabeled (PU) learning approach to train a more accurate link prediction model. PU learning is a special type of machine learning that can work well even when you don't have clear negative examples. The idea is to find patterns in the positive examples and the unlabeled data to make better predictions.
By taking this PU learning approach, PULL is able to outperform traditional link prediction methods that require fully labeled data. It's a clever way to work with the messy, incomplete data we often have in real-world networks.
Technical Explanation
The PULL method builds on recent advances in Positive-Unlabeled (PU) learning and graph neural networks (GNNs) for link prediction.
Rather than treating all non-existent links as definitive negatives, PULL treats the non-existent links as "unlabeled" data. It then uses PU learning techniques to train a more accurate link prediction model. Specifically, PULL uses a Markov network to model the network structure, and learns node and edge representations using a GNN-based encoder.
The key innovation is in the PU learning objective, which encourages the model to learn representations that can effectively distinguish positive links from the unlabeled data. This allows PULL to outperform traditional supervised link prediction methods that require fully labeled data.
PULL is evaluated on several real-world network datasets, and shows significant improvements in link prediction accuracy compared to state-of-the-art baselines. The results demonstrate the power of the PU learning approach for tackling the inherent challenges in link prediction tasks.
Critical Analysis
The PULL method offers a compelling approach to link prediction that addresses the common challenge of incomplete label information. By treating non-existent links as unlabeled data rather than definitive negatives, PULL is able to learn more effective representations for distinguishing positive and negative links.
That said, the paper does not deeply explore the limitations of the PU learning approach. For example, the performance of PU learning can be sensitive to class imbalance and the underlying distribution of the unlabeled data. The authors could have probed these issues more in their analysis.
Additionally, the experiments are limited to static network datasets. It would be valuable to see how PULL performs on dynamic networks where the link structure evolves over time - this is an important real-world scenario that was not addressed.
Overall, the PULL method represents an interesting and potentially impactful advancement in link prediction. However, further research is needed to fully understand its strengths, weaknesses, and applicability across a wider range of network modeling tasks.
Conclusion
The PULL method introduces a novel PU learning-based approach to the problem of link prediction in networks. By treating non-existent links as unlabeled data rather than definitive negatives, PULL is able to learn more accurate link prediction models compared to traditional supervised methods.
The key innovation and strength of PULL is in its ability to work effectively with the incomplete label information that is common in real-world network data. This makes PULL a promising tool for a wide range of applications, from social network analysis to knowledge graph completion.
While the paper demonstrates strong empirical performance, further research is needed to fully understand the limitations and broader applicability of the PU learning approach used in PULL. Nonetheless, this work represents an important step forward in advancing the state-of-the-art in network link prediction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PULL: PU-Learning-based Accurate Link Prediction
Junghun Kim, Ka Hyun Park, Hoyoung Yoon, U Kang
Given an edge-incomplete graph, how can we accurately find the missing links? The link prediction in edge-incomplete graphs aims to discover the missing relations between entities when their relationships are represented as a graph. Edge-incomplete graphs are prevalent in real-world due to practical limitations, such as not checking all users when adding friends in a social network. Addressing the problem is crucial for various tasks, including recommending friends in social networks and finding references in citation networks. However, previous approaches rely heavily on the given edge-incomplete (observed) graph, making it challenging to consider the missing (unobserved) links during training. In this paper, we propose PULL (PU-Learning-based Link predictor), an accurate link prediction method based on the positive-unlabeled (PU) learning. PULL treats the observed edges in the training graph as positive examples, and the unconnected node pairs as unlabeled ones. PULL effectively prevents the link predictor from overfitting to the observed graph by proposing latent variables for every edge, and leveraging the expected graph structure with respect to the variables. Extensive experiments on five real-world datasets show that PULL consistently outperforms the baselines for predicting links in edge-incomplete graphs.
Read more5/21/2024
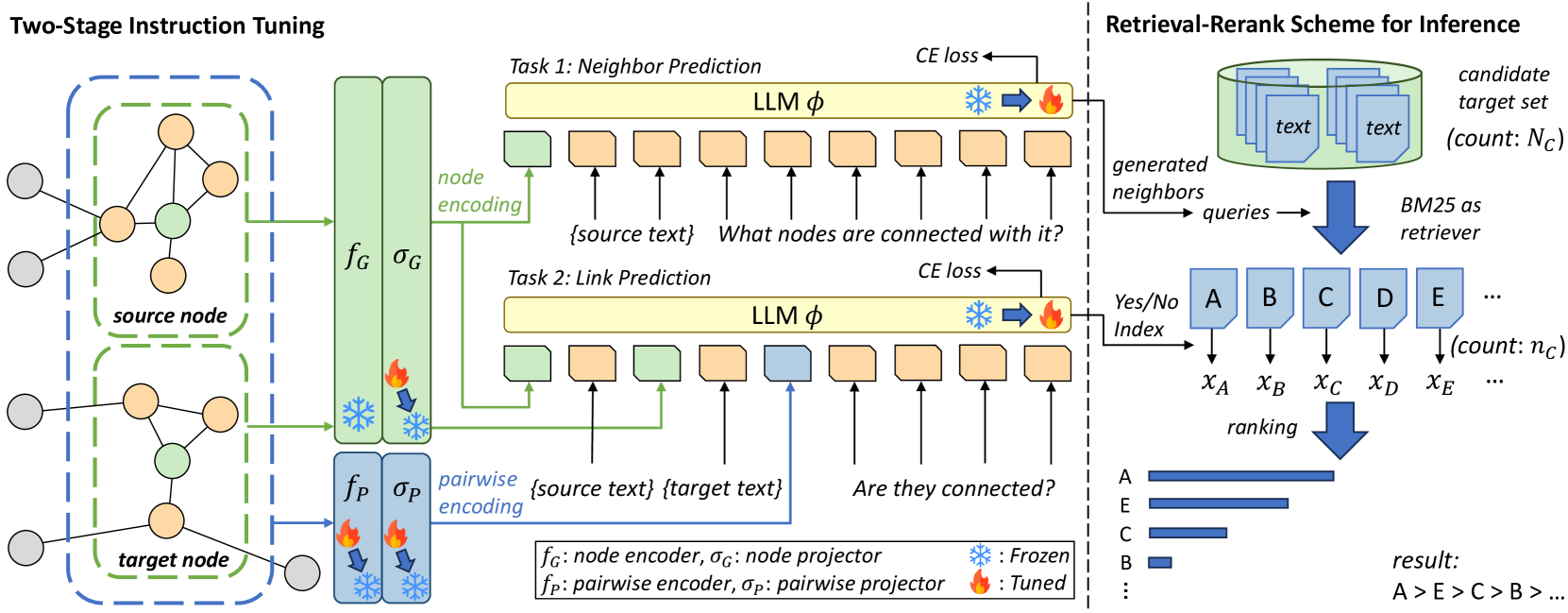
0
LinkGPT: Teaching Large Language Models To Predict Missing Links
Zhongmou He, Jing Zhu, Shengyi Qian, Joyce Chai, Danai Koutra
Large Language Models (LLMs) have shown promising results on various language and vision tasks. Recently, there has been growing interest in applying LLMs to graph-based tasks, particularly on Text-Attributed Graphs (TAGs). However, most studies have focused on node classification, while the use of LLMs for link prediction (LP) remains understudied. In this work, we propose a new task on LLMs, where the objective is to leverage LLMs to predict missing links between nodes in a graph. This task evaluates an LLM's ability to reason over structured data and infer new facts based on learned patterns. This new task poses two key challenges: (1) How to effectively integrate pairwise structural information into the LLMs, which is known to be crucial for LP performance, and (2) how to solve the computational bottleneck when teaching LLMs to perform LP. To address these challenges, we propose LinkGPT, the first end-to-end trained LLM for LP tasks. To effectively enhance the LLM's ability to understand the underlying structure, we design a two-stage instruction tuning approach where the first stage fine-tunes the pairwise encoder, projector, and node projector, and the second stage further fine-tunes the LLMs to predict links. To address the efficiency challenges at inference time, we introduce a retrieval-reranking scheme. Experiments show that LinkGPT can achieve state-of-the-art performance on real-world graphs as well as superior generalization in zero-shot and few-shot learning, surpassing existing benchmarks. At inference time, it can achieve $10times$ speedup while maintaining high LP accuracy.
Read more6/10/2024
🔮
0
Link Prediction in Bipartite Networks
c{S}ukru Demir .Inan Ozer (GSU), Gunce Keziban Orman (GSU), Vincent Labatut (LIA)
Bipartite networks serve as highly suitable models to represent systems involving interactions between two distinct types of entities, such as online dating platforms, job search services, or ecommerce websites. These models can be leveraged to tackle a number of tasks, including link prediction among the most useful ones, especially to design recommendation systems. However, if this task has garnered much interest when conducted on unipartite (i.e. standard) networks, it is far from being the case for bipartite ones. In this study, we address this gap by performing an experimental comparison of 19 link prediction methods able to handle bipartite graphs. Some come directly from the literature, and some are adapted by us from techniques originally designed for unipartite networks. We also propose to repurpose recommendation systems based on graph convolutional networks (GCN) as a novel link prediction solution for bipartite networks. To conduct our experiments, we constitute a benchmark of 3 real-world bipartite network datasets with various topologies. Our results indicate that GCN-based personalized recommendation systems, which have received significant attention in recent years, can produce successful results for link prediction in bipartite networks. Furthermore, purely heuristic metrics that do not rely on any learning process, like the Structural Perturbation Method (SPM), can also achieve success.
Read more6/12/2024

0
Inductive Link Prediction in Knowledge Graphs using Path-based Neural Networks
Canlin Zhang, Xiuwen Liu
Link prediction is a crucial research area in knowledge graphs, with many downstream applications. In many real-world scenarios, inductive link prediction is required, where predictions have to be made among unseen entities. Embedding-based models usually need fine-tuning on new entity embeddings, and hence are difficult to be directly applied to inductive link prediction tasks. Logical rules captured by rule-based models can be directly applied to new entities with the same graph typologies, but the captured rules are discrete and usually lack generosity. Graph neural networks (GNNs) can generalize topological information to new graphs taking advantage of deep neural networks, which however may still need fine-tuning on new entity embeddings. In this paper, we propose SiaILP, a path-based model for inductive link prediction using siamese neural networks. Our model only depends on relation and path embeddings, which can be generalized to new entities without fine-tuning. Experiments show that our model achieves several new state-of-the-art performances in link prediction tasks using inductive versions of WN18RR, FB15k-237, and Nell995. Our code is available at url{https://github.com/canlinzhang/SiaILP}.
Read more7/10/2024