Relations Prediction for Knowledge Graph Completion using Large Language Models
2405.02738
0
0
🔮
Abstract
Knowledge Graphs have been widely used to represent facts in a structured format. Due to their large scale applications, knowledge graphs suffer from being incomplete. The relation prediction task obtains knowledge graph completion by assigning one or more possible relations to each pair of nodes. In this work, we make use of the knowledge graph node names to fine-tune a large language model for the relation prediction task. By utilizing the node names only we enable our model to operate sufficiently in the inductive settings. Our experiments show that we accomplish new scores on a widely used knowledge graph benchmark.
Create account to get full access
Overview
- Knowledge graphs are used to represent facts in a structured format
- Knowledge graphs are often incomplete due to their large-scale applications
- Relation prediction is a task that aims to complete knowledge graphs by assigning possible relations between pairs of nodes
- This work explores using the names of knowledge graph nodes to fine-tune a large language model for the relation prediction task
- The proposed approach can work in inductive settings where new nodes are introduced
Plain English Explanation
Knowledge graphs are like digital maps that store information about the world in a structured way. They contain "nodes" that represent things like people, places, or concepts, and "edges" that show the relationships between them. For example, a knowledge graph might have a node for "Paris" and an edge connecting it to "France" to show that Paris is a city in France.
However, knowledge graphs are often incomplete - they may be missing some connections or relationships. To address this, researchers have developed "relation prediction" techniques that try to guess what additional connections could be added to fill in the gaps.
In this work, the researchers propose a new approach to relation prediction that uses the names of the nodes in the knowledge graph. By looking at the actual words used to describe the nodes, their model can learn patterns and make informed guesses about what relationships might be missing. This is especially useful in situations where new nodes are introduced, as the model can still make predictions without needing to see the full graph structure.
The researchers tested their approach on standard benchmarks for knowledge graph completion and found that it achieved state-of-the-art performance, meaning it outperformed other leading methods. This suggests that using node names can be a powerful way to improve the completeness of large-scale knowledge graphs.
Technical Explanation
The researchers in this work leverage the textual information contained in knowledge graph node names to fine-tune a large language model for the relation prediction task. By utilizing only the node names, their approach can operate sufficiently in inductive settings where new nodes are introduced, without requiring access to the full graph structure.
The proposed method involves pre-training a language model on a large corpus of text, and then fine-tuning it on the task of predicting relations between pairs of nodes given their names. This allows the model to learn patterns and associations from the natural language descriptions of the nodes, which can then be applied to make informed guesses about missing connections in the knowledge graph.
The researchers evaluated their approach on popular knowledge graph benchmarks, such as FB15k-237 and NELL-995, and reported new state-of-the-art results. This demonstrates the effectiveness of their node name-based method for knowledge graph completion and progressive knowledge graph construction.
Critical Analysis
The researchers acknowledge that their approach relies solely on the textual information in node names, which may not capture all the nuances and context present in the full graph structure. There may be cases where the node names alone are insufficient to accurately predict certain relations, and incorporating additional graph-based features could further improve performance.
Additionally, the researchers note that their method may be sensitive to the quality and informativeness of the node names, as well as the coverage and representativeness of the training data used to fine-tune the language model. In real-world scenarios, node names may not always be descriptive or consistent, which could limit the effectiveness of the proposed approach.
Further research could explore ways to combine the node name-based approach with other knowledge graph completion techniques, such as embedding-based or rule-based methods, to leverage the strengths of multiple approaches and address their individual limitations. Investigating the robustness of the method to noisy or incomplete node names would also be a valuable area of study.
Conclusion
This work demonstrates the potential of leveraging the textual information contained in knowledge graph node names to improve the task of relation prediction and knowledge graph completion. By fine-tuning a large language model on the node names, the researchers were able to achieve state-of-the-art results on standard benchmarks, highlighting the value of incorporating natural language understanding into knowledge graph-related tasks.
The proposed approach can be particularly useful in inductive settings where new nodes are introduced, as it does not require access to the full graph structure. This makes it a promising technique for building and expanding large-scale knowledge graphs in a more efficient and scalable manner.
While the method has its limitations, this research opens up interesting avenues for further exploration and integration with other knowledge graph completion techniques. As the importance of comprehensive and accurate knowledge graphs continues to grow, innovative approaches like this one can play a crucial role in advancing the field and enabling more effective knowledge representation and reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Knowledge Graph Completion using Structural and Textual Embeddings
Sakher Khalil Alqaaidi, Krzysztof Kochut
0
0
Knowledge Graphs (KGs) are widely employed in artificial intelligence applications, such as question-answering and recommendation systems. However, KGs are frequently found to be incomplete. While much of the existing literature focuses on predicting missing nodes for given incomplete KG triples, there remains an opportunity to complete KGs by exploring relations between existing nodes, a task known as relation prediction. In this study, we propose a relations prediction model that harnesses both textual and structural information within KGs. Our approach integrates walks-based embeddings with language model embeddings to effectively represent nodes. We demonstrate that our model achieves competitive results in the relation prediction task when evaluated on a widely used dataset.
4/26/2024

Evaluating Class Membership Relations in Knowledge Graphs using Large Language Models
Bradley P. Allen, Paul T. Groth
0
0
A backbone of knowledge graphs are their class membership relations, which assign entities to a given class. As part of the knowledge engineering process, we propose a new method for evaluating the quality of these relations by processing descriptions of a given entity and class using a zero-shot chain-of-thought classifier that uses a natural language intensional definition of a class. We evaluate the method using two publicly available knowledge graphs, Wikidata and CaLiGraph, and 7 large language models. Using the gpt-4-0125-preview large language model, the method's classification performance achieves a macro-averaged F1-score of 0.830 on data from Wikidata and 0.893 on data from CaLiGraph. Moreover, a manual analysis of the classification errors shows that 40.9% of errors were due to the knowledge graphs, with 16.0% due to missing relations and 24.9% due to incorrectly asserted relations. These results show how large language models can assist knowledge engineers in the process of knowledge graph refinement. The code and data are available on Github.
4/29/2024
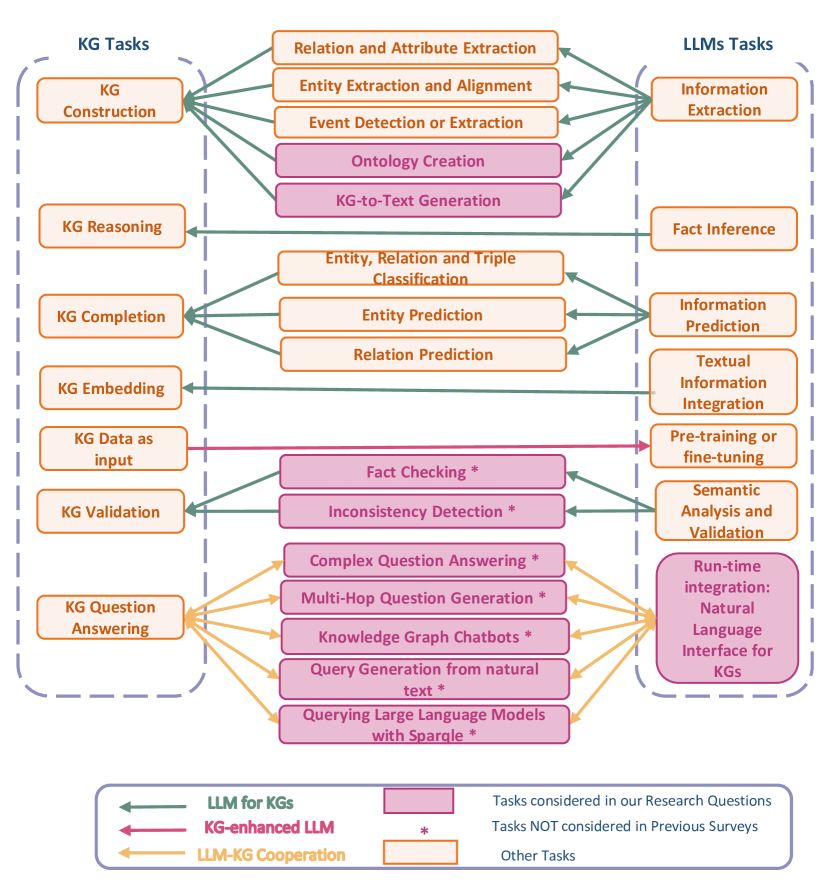
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Hanieh Khorashadizadeh, Fatima Zahra Amara, Morteza Ezzabady, Fr'ed'eric Ieng, Sanju Tiwari, Nandana Mihindukulasooriya, Jinghua Groppe, Soror Sahri, Farah Benamara, Sven Groppe
0
0
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
6/13/2024
💬
Retrieval-Augmented Language Model for Extreme Multi-Label Knowledge Graph Link Prediction
Yu-Hsiang Lin, Huang-Ting Shieh, Chih-Yu Liu, Kuang-Ting Lee, Hsiao-Cheng Chang, Jing-Lun Yang, Yu-Sheng Lin
0
0
Extrapolation in Large language models (LLMs) for open-ended inquiry encounters two pivotal issues: (1) hallucination and (2) expensive training costs. These issues present challenges for LLMs in specialized domains and personalized data, requiring truthful responses and low fine-tuning costs. Existing works attempt to tackle the problem by augmenting the input of a smaller language model with information from a knowledge graph (KG). However, they have two limitations: (1) failing to extract relevant information from a large one-hop neighborhood in KG and (2) applying the same augmentation strategy for KGs with different characteristics that may result in low performance. Moreover, open-ended inquiry typically yields multiple responses, further complicating extrapolation. We propose a new task, the extreme multi-label KG link prediction task, to enable a model to perform extrapolation with multiple responses using structured real-world knowledge. Our retriever identifies relevant one-hop neighbors by considering entity, relation, and textual data together. Our experiments demonstrate that (1) KGs with different characteristics require different augmenting strategies, and (2) augmenting the language model's input with textual data improves task performance significantly. By incorporating the retrieval-augmented framework with KG, our framework, with a small parameter size, is able to extrapolate based on a given KG. The code can be obtained on GitHub: https://github.com/exiled1143/Retrieval-Augmented-Language-Model-for-Multi-Label-Knowledge-Graph-Link-Prediction.git
5/22/2024