PUMGPT: A Large Vision-Language Model for Product Understanding

0
📈
Sign in to get full access
Overview
- E-commerce platforms can benefit from accurate product understanding to improve user experience and operational efficiency.
- Traditional methods focus on isolated tasks like attribute extraction or categorization, leading to adaptability issues and challenges with noisy internet data.
- Current Large Vision Language Models (LVLMs) lack domain-specific fine-tuning, resulting in lower precision and instruction-following capabilities.
Plain English Explanation
E-commerce platforms, like online stores, can improve their customer experience and business operations by having a better understanding of the products they sell. Traditional methods for this often focus on individual tasks, like identifying product attributes or categorizing items. However, these approaches can have trouble adapting to changing needs and struggle with the messy data found on the internet.
The latest large language models that can process both text and images have not been specifically trained for the e-commerce domain. As a result, they may not be as accurate or good at following instructions related to product understanding tasks.
To address these issues, the researchers introduce PumGPT, the first e-commerce-specialized large language model designed for multi-modal (text and image) product understanding. They collected and cleaned up a large dataset of over 600,000 high-quality product listings, which they then used to train PumGPT on five key tasks that are important for e-commerce platforms and retailers.
Technical Explanation
The researchers collected and curated a dataset of over one million products from AliExpress, a major e-commerce platform. They then used a universal hallucination detection framework to filter out non-inferable attributes, resulting in a dataset of 663,000 high-quality product samples.
PumGPT, the model introduced in this paper, is designed to perform five essential product understanding tasks: attribute extraction, product categorization, product title generation, product image captioning, and product search ranking. These tasks are aimed at enhancing workflows for e-commerce businesses.
The researchers also introduce PumBench, a benchmark to evaluate the performance of different large language models on product understanding tasks. Their experiments show that PumGPT outperforms five other open-source large language models, as well as GPT-4V, in these product-focused tasks.
Critical Analysis
The paper provides a thorough evaluation of PumGPT's performance, including comparisons to other state-of-the-art models. However, it does not delve deeply into the limitations or potential biases of the approach. For example, the dataset curation process may have introduced biases, and the model's performance on more diverse or niche product categories is not addressed.
Additionally, the paper does not discuss potential privacy or ethical concerns related to the use of e-commerce data or the deployment of such a powerful product understanding model in real-world scenarios. Further research is needed to understand the broader implications and responsible development of such technologies.
Conclusion
This research introduces PumGPT, the first large language model specifically designed for multi-modal product understanding tasks in the e-commerce domain. By training on a large, high-quality dataset and focusing on key e-commerce-related challenges, PumGPT demonstrates superior performance compared to other general-purpose language models.
The development of domain-specific large language models, such as PumGPT, has the potential to significantly enhance the user experience and operational efficiency of e-commerce platforms. However, careful consideration of the model's limitations and potential societal impact is necessary to ensure responsible and ethical deployment of such technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
PUMGPT: A Large Vision-Language Model for Product Understanding
Wei Xue, Zongyi Guo, Baoliang Cui, Zheng Xing, Xiaoyi Zeng, Xiufei Wang, Shuhui Wu, Weiming Lu
E-commerce platforms benefit from accurate product understanding to enhance user experience and operational efficiency. Traditional methods often focus on isolated tasks such as attribute extraction or categorization, posing adaptability issues to evolving tasks and leading to usability challenges with noisy data from the internet. Current Large Vision Language Models (LVLMs) lack domain-specific fine-tuning, thus falling short in precision and instruction following. To address these issues, we introduce PumGPT, the first e-commerce specialized LVLM designed for multi-modal product understanding tasks. We collected and curated a dataset of over one million products from AliExpress, filtering out non-inferable attributes using a universal hallucination detection framework, resulting in 663k high-quality data samples. PumGPT focuses on five essential tasks aimed at enhancing workflows for e-commerce platforms and retailers. We also introduce PumBench, a benchmark to evaluate product understanding across LVLMs. Our experiments show that PumGPT outperforms five other open-source LVLMs and GPT-4V in product understanding tasks. We also conduct extensive analytical experiments to delve deeply into the superiority of PumGPT, demonstrating the necessity for a specialized model in the e-commerce domain.
Read more6/18/2024
💬
0
ExtractGPT: Exploring the Potential of Large Language Models for Product Attribute Value Extraction
Alexander Brinkmann, Roee Shraga, Christian Bizer
In order to facilitate features such as faceted product search and product comparison, e-commerce platforms require accurately structured product data, including precise attribute/value pairs. Vendors often times provide unstructured product descriptions consisting only of an offer title and a textual description. Consequently, extracting attribute values from titles and descriptions is vital for e-commerce platforms. State-of-the-art attribute value extraction methods based on pre-trained language models, such as BERT, face two drawbacks (i) the methods require significant amounts of task-specific training data and (ii) the fine-tuned models have problems with generalising to unseen attribute values that were not part of the training data. This paper explores the potential of using large language models as a more training data-efficient and more robust alternative to existing AVE methods. We propose prompt templates for describing the target attributes of the extraction to the LLM, covering both zero-shot and few-shot scenarios. In the zero-shot scenario, textual and JSON-based target schema representations of the attributes are compared. In the few-shot scenario, we investigate (i) the provision of example attribute values, (ii) the selection of in-context demonstrations, (iii) shuffled ensembling to prevent position bias, and (iv) fine-tuning the LLM. We evaluate the prompt templates in combination with hosted LLMs, such as GPT-3.5 and GPT-4, and open-source LLMs which can be run locally. We compare the performance of the LLMs to the PLM-based methods SU-OpenTag, AVEQA, and MAVEQA. The highest average F1-score of 86% was achieved by GPT-4. Llama-3-70B performs only 3% worse than GPT-4, making it a competitive open-source alternative. Given the same training data, this prompt/GPT-4 combination outperforms the best PLM baseline by an average of 6% F1-score.
Read more9/4/2024
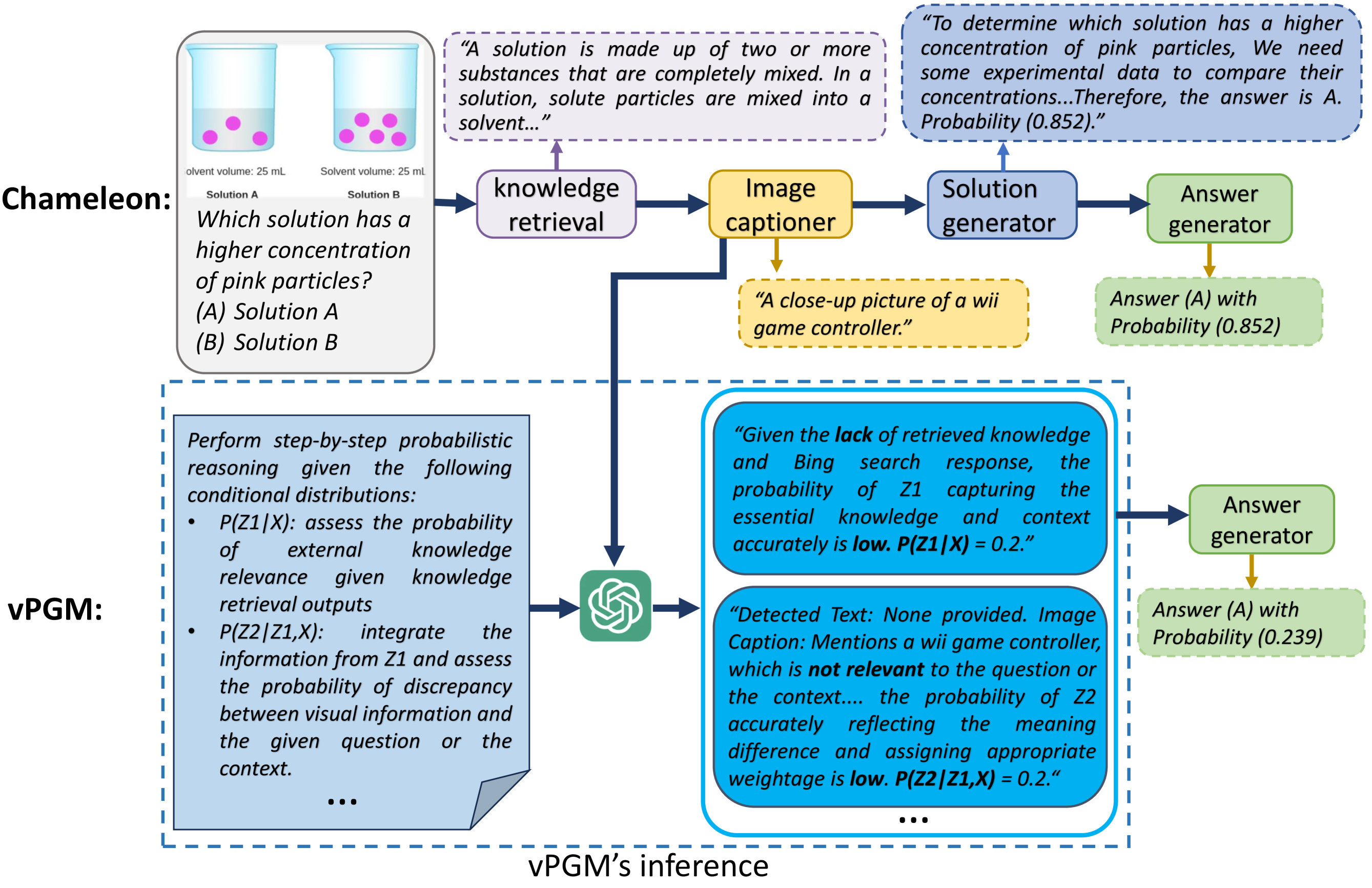
0
Verbalized Probabilistic Graphical Modeling with Large Language Models
Hengguan Huang, Xing Shen, Songtao Wang, Dianbo Liu, Hao Wang
Faced with complex problems, the human brain demonstrates a remarkable capacity to transcend sensory input and form latent understandings of perceived world patterns. However, this cognitive capacity is not explicitly considered or encoded in current large language models (LLMs). As a result, LLMs often struggle to capture latent structures and model uncertainty in complex compositional reasoning tasks. This work introduces a novel Bayesian prompting approach that facilitates training-free Bayesian inference with LLMs by using a verbalized Probabilistic Graphical Model (PGM). While traditional Bayesian approaches typically depend on extensive data and predetermined mathematical structures for learning latent factors and dependencies, our approach efficiently reasons latent variables and their probabilistic dependencies by prompting LLMs to adhere to Bayesian principles. We evaluated our model on several compositional reasoning tasks, both close-ended and open-ended. Our results indicate that the model effectively enhances confidence elicitation and text generation quality, demonstrating its potential to improve AI language understanding systems, especially in modeling uncertainty.
Read more6/11/2024

0
Using LLMs for the Extraction and Normalization of Product Attribute Values
Alexander Brinkmann, Nick Baumann, Christian Bizer
Product offers on e-commerce websites often consist of a product title and a textual product description. In order to enable features such as faceted product search or to generate product comparison tables, it is necessary to extract structured attribute-value pairs from the unstructured product titles and descriptions and to normalize the extracted values to a single, unified scale for each attribute. This paper explores the potential of using large language models (LLMs), such as GPT-3.5 and GPT-4, to extract and normalize attribute values from product titles and descriptions. We experiment with different zero-shot and few-shot prompt templates for instructing LLMs to extract and normalize attribute-value pairs. We introduce the Web Data Commons - Product Attribute Value Extraction (WDC-PAVE) benchmark dataset for our experiments. WDC-PAVE consists of product offers from 59 different websites which provide schema.org annotations. The offers belong to five different product categories, each with a specific set of attributes. The dataset provides manually verified attribute-value pairs in two forms: (i) directly extracted values and (ii) normalized attribute values. The normalization of the attribute values requires systems to perform the following types of operations: name expansion, generalization, unit of measurement conversion, and string wrangling. Our experiments demonstrate that GPT-4 outperforms the PLM-based extraction methods SU-OpenTag, AVEQA, and MAVEQA by 10%, achieving an F1-score of 91%. For the extraction and normalization of product attribute values, GPT-4 achieves a similar performance to the extraction scenario, while being particularly strong at string wrangling and name expansion.
Read more7/16/2024