PVTransformer: Point-to-Voxel Transformer for Scalable 3D Object Detection
2405.02811
0
0
🔎
Abstract
3D object detectors for point clouds often rely on a pooling-based PointNet to encode sparse points into grid-like voxels or pillars. In this paper, we identify that the common PointNet design introduces an information bottleneck that limits 3D object detection accuracy and scalability. To address this limitation, we propose PVTransformer: a transformer-based point-to-voxel architecture for 3D detection. Our key idea is to replace the PointNet pooling operation with an attention module, leading to a better point-to-voxel aggregation function. Our design respects the permutation invariance of sparse 3D points while being more expressive than the pooling-based PointNet. Experimental results show our PVTransformer achieves much better performance compared to the latest 3D object detectors. On the widely used Waymo Open Dataset, our PVTransformer achieves state-of-the-art 76.5 mAPH L2, outperforming the prior art of SWFormer by +1.7 mAPH L2.
Create account to get full access
Overview
- 3D object detection in point clouds often relies on PointNet, a pooling-based architecture that encodes sparse points into grid-like voxels or pillars.
- The paper identifies that the PointNet design introduces an information bottleneck that limits the accuracy and scalability of 3D object detection.
- To address this limitation, the paper proposes PVTransformer, a transformer-based point-to-voxel architecture for 3D detection.
Plain English Explanation
The paper discusses a common approach to 3D object detection in point cloud data, which involves using a neural network called PointNet to encode the sparse 3D points into a more structured format like voxels or pillars. However, the authors find that this PointNet design creates an information bottleneck that prevents the 3D object detection from achieving the best possible accuracy and scalability.
To overcome this limitation, the researchers propose a new architecture called PVTransformer. The key idea is to replace the pooling operation in PointNet with an attention-based module, which allows the network to better aggregate the information from the sparse 3D points into the voxel or pillar representation. This new design respects the inherent permutation invariance of the 3D points while being more expressive than the original PointNet.
The paper demonstrates that PVTransformer achieves significantly better performance on standard 3D object detection benchmarks compared to the latest state-of-the-art methods. For example, on the Waymo Open Dataset, PVTransformer outperforms the previous best-performing model by 1.7 percentage points in terms of mean average precision.
Technical Explanation
The paper proposes PVTransformer, a transformer-based point-to-voxel architecture for 3D object detection. The key innovation is to replace the PointNet pooling operation with an attention-based module, which the authors argue is a more expressive and effective way to aggregate information from the sparse 3D points into the voxel or pillar representation.
Specifically, the PVTransformer architecture first encodes the 3D points into a set of point features using a shared multilayer perceptron (MLP). These point features are then passed through an attention-based aggregation module, which computes weighted sums of the point features to produce the final voxel or pillar features. This attention-based aggregation respects the permutation invariance of the 3D points and is more expressive than the pooling operation used in the standard PointNet design.
The paper evaluates PVTransformer on several 3D object detection benchmarks, including the Waymo Open Dataset. The results show that PVTransformer outperforms the latest state-of-the-art 3D object detectors by a significant margin, achieving a new state-of-the-art 76.5 mAPH L2 score on the Waymo dataset, which is 1.7 percentage points higher than the previous best-performing model.
Critical Analysis
The paper provides a compelling solution to the information bottleneck introduced by the PointNet design in 3D object detection. The proposed PVTransformer architecture effectively addresses this limitation by replacing the pooling operation with a more expressive attention-based aggregation module.
One potential limitation of the research is that it focuses solely on the point-to-voxel or point-to-pillar encoding step, and does not explore the impact of the transformer-based architecture on the overall 3D object detection pipeline. It would be interesting to see how PVTransformer performs when integrated with different 3D object detection algorithms and network backbones.
Additionally, the paper does not provide a detailed analysis of the computational complexity and inference time of PVTransformer compared to the PointNet-based baselines. This information would be helpful in understanding the practical implications and deployment feasibility of the proposed approach.
Overall, the research presents a valuable contribution to the field of 3D object detection, demonstrating the potential of transformer-based architectures to overcome the limitations of the commonly used PointNet design. Further exploration of the broader impact and practical considerations of PVTransformer would be a valuable direction for future work.
Conclusion
The paper introduces PVTransformer, a transformer-based point-to-voxel architecture that addresses the information bottleneck in 3D object detection caused by the pooling-based PointNet design. By replacing the pooling operation with an attention-based aggregation module, PVTransformer is able to achieve significantly better performance on standard 3D object detection benchmarks, setting a new state-of-the-art result on the Waymo Open Dataset.
This research highlights the potential of transformer-based approaches to improve the effectiveness and scalability of 3D object detection, which is a crucial task for applications like autonomous driving and robotics. The proposed PVTransformer architecture demonstrates the value of exploring alternative point cloud encoding methods beyond the widely used PointNet, opening up new avenues for innovation in this important field of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CT3D++: Improving 3D Object Detection with Keypoint-induced Channel-wise Transformer
Hualian Sheng, Sijia Cai, Na Zhao, Bing Deng, Qiao Liang, Min-Jian Zhao, Jieping Ye
0
0
The field of 3D object detection from point clouds is rapidly advancing in computer vision, aiming to accurately and efficiently detect and localize objects in three-dimensional space. Current 3D detectors commonly fall short in terms of flexibility and scalability, with ample room for advancements in performance. In this paper, our objective is to address these limitations by introducing two frameworks for 3D object detection with minimal hand-crafted design. Firstly, we propose CT3D, which sequentially performs raw-point-based embedding, a standard Transformer encoder, and a channel-wise decoder for point features within each proposal. Secondly, we present an enhanced network called CT3D++, which incorporates geometric and semantic fusion-based embedding to extract more valuable and comprehensive proposal-aware information. Additionally, CT3D ++ utilizes a point-to-key bidirectional encoder for more efficient feature encoding with reduced computational cost. By replacing the corresponding components of CT3D with these novel modules, CT3D++ achieves state-of-the-art performance on both the KITTI dataset and the large-scale Way-mo Open Dataset. The source code for our frameworks will be made accessible at https://github.com/hlsheng1/CT3D-plusplus.
6/13/2024
🔎
Hierarchical Point Attention for Indoor 3D Object Detection
Manli Shu, Le Xue, Ning Yu, Roberto Mart'in-Mart'in, Caiming Xiong, Tom Goldstein, Juan Carlos Niebles, Ran Xu
0
0
3D object detection is an essential vision technique for various robotic systems, such as augmented reality and domestic robots. Transformers as versatile network architectures have recently seen great success in 3D point cloud object detection. However, the lack of hierarchy in a plain transformer restrains its ability to learn features at different scales. Such limitation makes transformer detectors perform worse on smaller objects and affects their reliability in indoor environments where small objects are the majority. This work proposes two novel attention operations as generic hierarchical designs for point-based transformer detectors. First, we propose Aggregated Multi-Scale Attention (MS-A) that builds multi-scale tokens from a single-scale input feature to enable more fine-grained feature learning. Second, we propose Size-Adaptive Local Attention (Local-A) with adaptive attention regions for localized feature aggregation within bounding box proposals. Both attention operations are model-agnostic network modules that can be plugged into existing point cloud transformers for end-to-end training. We evaluate our method on two widely used indoor detection benchmarks. By plugging our proposed modules into the state-of-the-art transformer-based 3D detectors, we improve the previous best results on both benchmarks, with more significant improvements on smaller objects.
5/10/2024

PillarNeXt: Improving the 3D detector by introducing Voxel2Pillar feature encoding and extracting multi-scale features
Xusheng Li, Chengliang Wang, Shumao Wang, Zhuo Zeng, Ji Liu
0
0
The multi-line LiDAR is widely used in autonomous vehicles, so point cloud-based 3D detectors are essential for autonomous driving. Extracting rich multi-scale features is crucial for point cloud-based 3D detectors in autonomous driving due to significant differences in the size of different types of objects. However, because of the real-time requirements, large-size convolution kernels are rarely used to extract large-scale features in the backbone. Current 3D detectors commonly use feature pyramid networks to obtain large-scale features; however, some objects containing fewer point clouds are further lost during down-sampling, resulting in degraded performance. Since pillar-based schemes require much less computation than voxel-based schemes, they are more suitable for constructing real-time 3D detectors. Hence, we propose the PillarNeXt, a pillar-based scheme. We redesigned the feature encoding, the backbone, and the neck of the 3D detector. We propose the Voxel2Pillar feature encoding, which uses a sparse convolution constructor to construct pillars with richer point cloud features, especially height features. The Voxel2Pillar adds more learnable parameters to the feature encoding, enabling the initial pillars to have higher performance ability. We extract multi-scale and large-scale features in the proposed fully sparse backbone, which does not utilize large-size convolutional kernels; the backbone consists of the proposed multi-scale feature extraction module. The neck consists of the proposed sparse ConvNeXt, whose simple structure significantly improves the performance. We validate the effectiveness of the proposed PillarNeXt on the Waymo Open Dataset, and the object detection accuracy for vehicles, pedestrians, and cyclists is improved. We also verify the effectiveness of each proposed module in detail through ablation studies.
5/21/2024
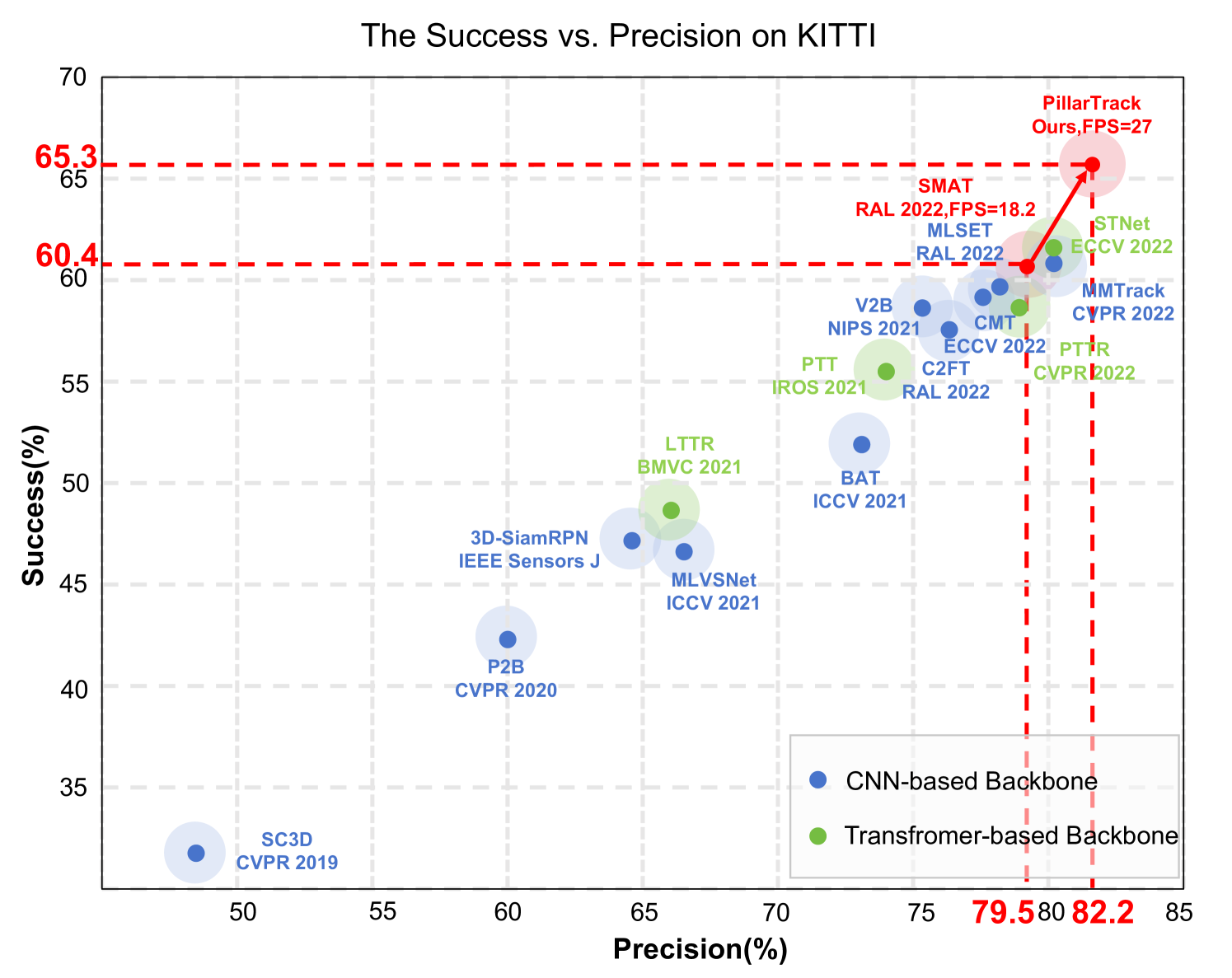
PillarTrack: Redesigning Pillar-based Transformer Network for Single Object Tracking on Point Clouds
Weisheng Xu, Sifan Zhou, Zhihang Yuan
0
0
LiDAR-based 3D single object tracking (3D SOT) is a critical issue in robotics and autonomous driving. It aims to obtain accurate 3D BBox from the search area based on similarity or motion. However, existing 3D SOT methods usually follow the point-based pipeline, where the sampling operation inevitably leads to redundant or lost information, resulting in unexpected performance. To address these issues, we propose PillarTrack, a pillar-based 3D single object tracking framework. Firstly, we transform sparse point clouds into dense pillars to preserve the local and global geometrics. Secondly, we introduce a Pyramid-type Encoding Pillar Feature Encoder (PE-PFE) design to help the feature representation of each pillar. Thirdly, we present an efficient Transformer-based backbone from the perspective of modality differences. Finally, we construct our PillarTrack tracker based above designs. Extensive experiments on the KITTI and nuScenes dataset demonstrate the superiority of our proposed method. Notably, our method achieves state-of-the-art performance on the KITTI and nuScenes dataset and enables real-time tracking speed. We hope our work could encourage the community to rethink existing 3D SOT tracker designs.We will open source our code to the research community in https://github.com/StiphyJay/PillarTrack.
4/12/2024