PillarTrack: Redesigning Pillar-based Transformer Network for Single Object Tracking on Point Clouds

0
Sign in to get full access
Overview
- This paper presents a novel deep learning model called PillarTrack for single object tracking on 3D point cloud data.
- PillarTrack is built upon the Pillar-based Transformer Network (PTN) architecture and introduces several key improvements to enhance tracking performance.
- The proposed model aims to address the challenges of object tracking in 3D point clouds, which is an important task for applications like autonomous driving and robotics.
Plain English Explanation
Tracking objects in 3D point clouds: 3D point clouds are digital representations of the physical world, created using technologies like LiDAR. Tracking objects, like vehicles or pedestrians, in these 3D point clouds is crucial for tasks like self-driving cars and robot navigation. However, this is a challenging problem due to the complex and dynamic nature of 3D data.
PillarTrack: An improved 3D object tracker: The researchers developed a new deep learning model called PillarTrack to address the challenges of 3D object tracking. PillarTrack builds upon an existing architecture called the Pillar-based Transformer Network (PTN), but introduces several key improvements to enhance the tracking performance.
Innovations in PillarTrack: Some of the key innovations in PillarTrack include:
- Redesigned transformer modules to better capture spatial and temporal information
- Novel techniques to fuse information across multiple point cloud frames
- Efficient architecture design to enable real-time processing
Significance and applications: Accurate and efficient 3D object tracking is crucial for various applications, such as autonomous driving, robot navigation, and 3D perception. The improvements made in PillarTrack can contribute to the advancement of these technologies and enable more robust and reliable 3D perception systems.
Technical Explanation
The PillarTrack model is designed to address the challenges of single object tracking in 3D point cloud data. It builds upon the Pillar-based Transformer Network (PTN) architecture, which uses a pillar-based representation to efficiently process point cloud data.
The key innovations in PillarTrack include:
-
Redesigned Transformer Modules: The researchers have redesigned the transformer modules in the PTN architecture to better capture both spatial and temporal information from the 3D point cloud data. This helps the model understand the dynamic movement of objects over time.
-
Multi-Frame Fusion: PillarTrack introduces a novel technique to fuse information across multiple point cloud frames. This allows the model to leverage the temporal context and improve the tracking performance.
-
Efficient Architecture: The PillarTrack architecture is designed to be computationally efficient, enabling real-time processing of 3D point cloud data. This is crucial for applications like autonomous driving, where low latency is essential.
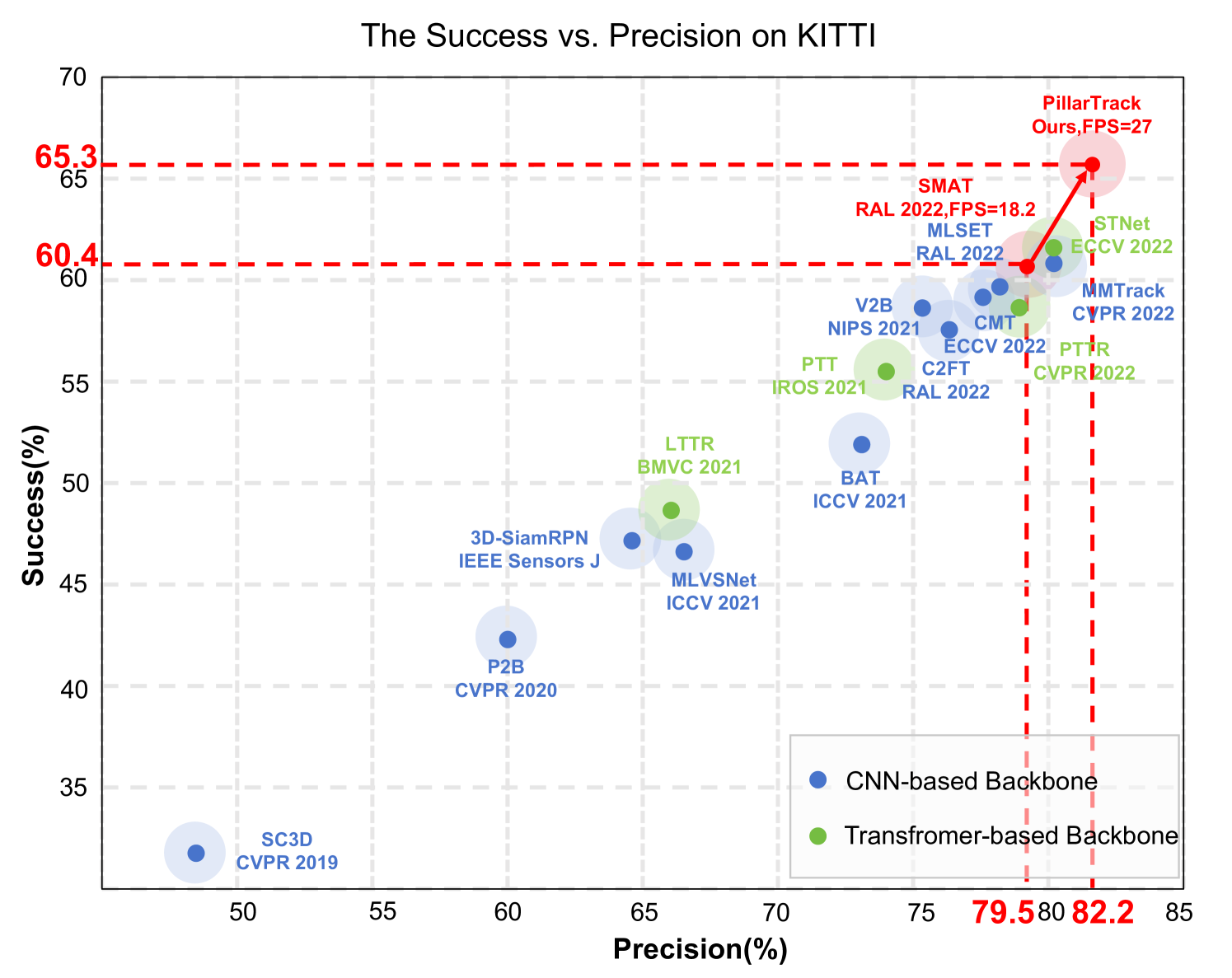
The researchers evaluate the performance of PillarTrack on standard 3D object tracking benchmarks, such as the KITTI dataset. The results demonstrate that PillarTrack outperforms state-of-the-art 3D object tracking methods, while maintaining a high processing speed.
Critical Analysis
The paper provides a thorough evaluation of the PillarTrack model and highlights its advantages over existing approaches. However, the researchers also acknowledge some limitations of the study:
-
Sensitivity to Occlusion: Like many 3D object tracking methods, PillarTrack may struggle with heavily occluded objects, which can lead to tracking failures. Further research is needed to improve the model's robustness in such scenarios.
-
Generalization to Other Datasets: The evaluation is primarily focused on the KITTI dataset, which may not capture the full diversity of real-world 3D point cloud data. It would be valuable to assess the model's performance on a broader range of datasets to ensure its generalizability.
-
Integration with Downstream Applications: While the paper showcases the technical advancements of PillarTrack, it does not explicitly discuss how the model could be integrated and deployed in practical applications, such as autonomous driving or robotics. Addressing these integration challenges could further enhance the impact of the research.
Overall, the PillarTrack model represents a promising step forward in 3D object tracking, and the innovations presented in the paper could inspire future research in this important field.
Conclusion
The PillarTrack model proposed in this paper demonstrates significant improvements in single object tracking on 3D point cloud data. By redesigning the transformer modules, introducing multi-frame fusion techniques, and optimizing the architecture for efficiency, the researchers have developed a more robust and accurate 3D object tracker.
The advancements made in PillarTrack have the potential to contribute to the development of more advanced 3D perception systems, benefiting applications like autonomous driving, robot navigation, and 3D scene understanding. As the research in this field continues to evolve, addressing the identified limitations and exploring further integration with real-world systems will be crucial next steps.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PillarTrack: Redesigning Pillar-based Transformer Network for Single Object Tracking on Point Clouds
Weisheng Xu, Sifan Zhou, Zhihang Yuan
LiDAR-based 3D single object tracking (3D SOT) is a critical issue in robotics and autonomous driving. It aims to obtain accurate 3D BBox from the search area based on similarity or motion. However, existing 3D SOT methods usually follow the point-based pipeline, where the sampling operation inevitably leads to redundant or lost information, resulting in unexpected performance. To address these issues, we propose PillarTrack, a pillar-based 3D single object tracking framework. Firstly, we transform sparse point clouds into dense pillars to preserve the local and global geometrics. Secondly, we introduce a Pyramid-type Encoding Pillar Feature Encoder (PE-PFE) design to help the feature representation of each pillar. Thirdly, we present an efficient Transformer-based backbone from the perspective of modality differences. Finally, we construct our PillarTrack tracker based above designs. Extensive experiments on the KITTI and nuScenes dataset demonstrate the superiority of our proposed method. Notably, our method achieves state-of-the-art performance on the KITTI and nuScenes dataset and enables real-time tracking speed. We hope our work could encourage the community to rethink existing 3D SOT tracker designs.We will open source our code to the research community in https://github.com/StiphyJay/PillarTrack.
Read more4/12/2024
0
EasyTrack: Efficient and Compact One-stream 3D Point Clouds Tracker
Baojie Fan, Wuyang Zhou, Kai Wang, Shijun Zhou, Fengyu Xu, Jiandong Tian
Most of 3D single object trackers (SOT) in point clouds follow the two-stream multi-stage 3D Siamese or motion tracking paradigms, which process the template and search area point clouds with two parallel branches, built on supervised point cloud backbones. In this work, beyond typical 3D Siamese or motion tracking, we propose a neat and compact one-stream transformer 3D SOT paradigm from the novel perspective, termed as textbf{EasyTrack}, which consists of three special designs: 1) A 3D point clouds tracking feature pre-training module is developed to exploit the masked autoencoding for learning 3D point clouds tracking representations. 2) A unified 3D tracking feature learning and fusion network is proposed to simultaneously learns target-aware 3D features, and extensively captures mutual correlation through the flexible self-attention mechanism. 3) A target location network in the dense bird's eye view (BEV) feature space is constructed for target classification and regression. Moreover, we develop an enhanced version named EasyTrack++, which designs the center points interaction (CPI) strategy to reduce the ambiguous targets caused by the noise point cloud background information. The proposed EasyTrack and EasyTrack++ set a new state-of-the-art performance ($textbf{18%}$, $textbf{40%}$ and $textbf{3%}$ success gains) in KITTI, NuScenes, and Waymo while runing at textbf{52.6fps} with few parameters (textbf{1.3M}). The code will be available at https://github.com/KnightApple427/Easytrack.
Read more4/15/2024

0
PillarNeXt: Improving the 3D detector by introducing Voxel2Pillar feature encoding and extracting multi-scale features
Xusheng Li, Chengliang Wang, Shumao Wang, Zhuo Zeng, Ji Liu
The multi-line LiDAR is widely used in autonomous vehicles, so point cloud-based 3D detectors are essential for autonomous driving. Extracting rich multi-scale features is crucial for point cloud-based 3D detectors in autonomous driving due to significant differences in the size of different types of objects. However, because of the real-time requirements, large-size convolution kernels are rarely used to extract large-scale features in the backbone. Current 3D detectors commonly use feature pyramid networks to obtain large-scale features; however, some objects containing fewer point clouds are further lost during down-sampling, resulting in degraded performance. Since pillar-based schemes require much less computation than voxel-based schemes, they are more suitable for constructing real-time 3D detectors. Hence, we propose the PillarNeXt, a pillar-based scheme. We redesigned the feature encoding, the backbone, and the neck of the 3D detector. We propose the Voxel2Pillar feature encoding, which uses a sparse convolution constructor to construct pillars with richer point cloud features, especially height features. The Voxel2Pillar adds more learnable parameters to the feature encoding, enabling the initial pillars to have higher performance ability. We extract multi-scale and large-scale features in the proposed fully sparse backbone, which does not utilize large-size convolutional kernels; the backbone consists of the proposed multi-scale feature extraction module. The neck consists of the proposed sparse ConvNeXt, whose simple structure significantly improves the performance. We validate the effectiveness of the proposed PillarNeXt on the Waymo Open Dataset, and the object detection accuracy for vehicles, pedestrians, and cyclists is improved. We also verify the effectiveness of each proposed module in detail through ablation studies.
Read more5/21/2024
🌐
0
OST: Efficient One-stream Network for 3D Single Object Tracking in Point Clouds
Xiantong Zhao, Yinan Han, Shengjing Tian, Jian Liu, Xiuping Liu
Although recent Siamese network-based trackers have achieved impressive perceptual accuracy for single object tracking in LiDAR point clouds, they usually utilized heavy correlation operations to capture category-level characteristics only, and overlook the inherent merit of arbitrariness in contrast to multiple object tracking. In this work, we propose a radically novel one-stream network with the strength of the instance-level encoding, which avoids the correlation operations occurring in previous Siamese network, thus considerably reducing the computational effort. In particular, the proposed method mainly consists of a Template-aware Transformer Module (TTM) and a Multi-scale Feature Aggregation (MFA) module capable of fusing spatial and semantic information. The TTM stitches the specified template and the search region together and leverages an attention mechanism to establish the information flow, breaking the previous pattern of independent textit{extraction-and-correlation}. As a result, this module makes it possible to directly generate template-aware features that are suitable for the arbitrary and continuously changing nature of the target, enabling the model to deal with unseen categories. In addition, the MFA is proposed to make spatial and semantic information complementary to each other, which is characterized by reverse directional feature propagation that aggregates information from shallow to deep layers. Extensive experiments on KITTI and nuScenes demonstrate that our method has achieved considerable performance not only for class-specific tracking but also for class-agnostic tracking with less computation and higher efficiency.
Read more6/10/2024