Q-learning as a monotone scheme

0
Sign in to get full access
Overview
- The paper explores the connection between Q-learning, a popular reinforcement learning algorithm, and monotone schemes, a mathematical concept in optimization theory.
- The researchers investigate the properties of Q-learning in a 1D deterministic linear quadratic control problem, showing that it can be interpreted as a monotone scheme.
- This analysis provides insights into the convergence and stability properties of Q-learning, which have important implications for its use in practical applications.
Plain English Explanation
The paper examines the relationship between the Q-learning algorithm, a widely used reinforcement learning technique, and the mathematical concept of "monotone schemes." Monotone schemes are a way of solving optimization problems that guarantees certain desirable properties, like convergence and stability.
The researchers focus on a specific problem called the "1D Deterministic Linear Quadratic" control problem. This is a simplified version of a real-world control problem, where the goal is to find the best way to control a system (like a robot or a vehicle) to achieve a desired outcome.
The key finding is that in this simplified problem, the Q-learning algorithm can be interpreted as a monotone scheme. This means that the Q-learning updates have the same mathematical properties as monotone schemes, which ensures that the algorithm will converge to the optimal solution and behave in a stable manner.
This result is significant because it provides a deeper understanding of how Q-learning works and why it is effective in certain situations. By connecting Q-learning to the well-studied concept of monotone schemes, the researchers can leverage the existing mathematical theory to analyze the algorithm's behavior and make predictions about its performance in more complex, real-world problems.
Technical Explanation
The paper explores the connection between the Q-learning algorithm and the mathematical concept of "monotone schemes" in the context of a 1D deterministic linear quadratic control problem.
In the 1D deterministic linear quadratic control problem, the goal is to find the optimal control policy for a simple, one-dimensional system with a linear dynamics and a quadratic cost function. The researchers show that in this simplified setting, the Q-learning updates can be interpreted as a monotone scheme.
Monotone schemes are a class of iterative methods used to solve optimization problems. They have the property that each update step improves the solution in a monotonic fashion, guaranteeing convergence to the optimal solution under certain conditions.
By establishing the connection between Q-learning and monotone schemes, the researchers are able to leverage the rich mathematical theory of monotone schemes to analyze the convergence and stability properties of Q-learning. Specifically, they show that Q-learning converges to the optimal Q-function and that the convergence rate is linear.
This analysis provides insights into the fundamental behavior of Q-learning and has important implications for its use in more complex, real-world reinforcement learning problems. The findings suggest that Q-learning may be a particularly suitable algorithm for problems with certain structural properties, such as convex optimization problems or problems with large, discrete action spaces.
Additionally, the connection to monotone schemes may help inform the design of multi-step temporal difference (TD) learning algorithms and the development of more advanced Q-learning architectures, by providing a principled mathematical framework for understanding their convergence and stability properties.
Critical Analysis
The paper makes a significant contribution by establishing a connection between Q-learning and the well-studied concept of monotone schemes. This analysis provides a solid mathematical foundation for understanding the properties of Q-learning and suggests ways in which it can be used effectively in practical applications.
However, it is important to note that the results are limited to a specific, simplified problem setting – the 1D deterministic linear quadratic control problem. While this problem is a useful testbed for studying the fundamental behavior of Q-learning, it may not fully capture the complexities of real-world reinforcement learning problems, which often involve nonlinear dynamics, stochastic environments, and high-dimensional state and action spaces.
Furthermore, the paper does not address the practical challenges of implementing Q-learning, such as the choice of hyperparameters, the design of exploration strategies, and the use of function approximation techniques. These factors can have a significant impact on the performance of Q-learning in practice and may require additional analysis and empirical validation.
It would be valuable for future research to explore the connections between Q-learning and monotone schemes in more general problem settings, as well as to investigate how the insights from this analysis can be leveraged to design more robust and efficient reinforcement learning algorithms. Additionally, further research is needed to understand the implications of the monotone scheme perspective for the design and analysis of other reinforcement learning algorithms, such as policy gradient methods and actor-critic architectures.
Conclusion
The paper presents an intriguing connection between the Q-learning algorithm and the mathematical concept of monotone schemes, which provides valuable insights into the convergence and stability properties of Q-learning. By interpreting Q-learning as a monotone scheme in the context of a 1D deterministic linear quadratic control problem, the researchers lay the groundwork for a deeper understanding of the fundamental behavior of this widely used reinforcement learning algorithm.
While the results are limited to a specific problem setting, the insights gained from this analysis have the potential to inform the design and analysis of more advanced reinforcement learning techniques, ultimately contributing to the development of more robust and effective algorithms for solving complex real-world problems. As the field of reinforcement learning continues to evolve, research that uncovers the mathematical foundations of key algorithms, like this paper on the connection between Q-learning and monotone schemes, will be crucial for advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Q-learning as a monotone scheme
Lingyi Yang
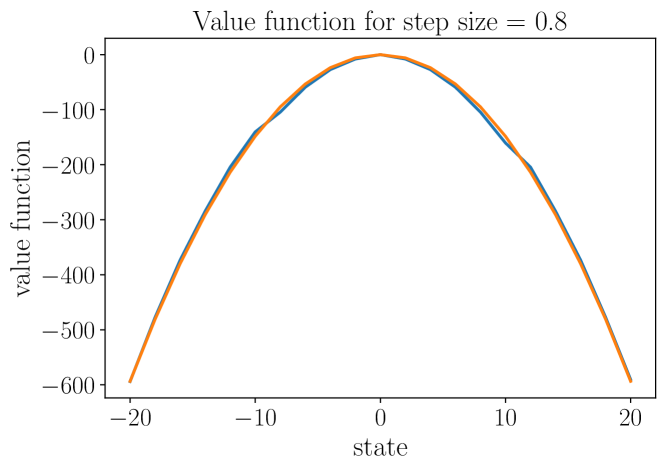
Stability issues with reinforcement learning methods persist. To better understand some of these stability and convergence issues involving deep reinforcement learning methods, we examine a simple linear quadratic example. We interpret the convergence criterion of exact Q-learning in the sense of a monotone scheme and discuss consequences of function approximation on monotonicity properties.
Read more6/3/2024
🧠
0
Unified ODE Analysis of Smooth Q-Learning Algorithms
Donghwan Lee
Convergence of Q-learning has been the focus of extensive research over the past several decades. Recently, an asymptotic convergence analysis for Q-learning was introduced using a switching system framework. This approach applies the so-called ordinary differential equation (ODE) approach to prove the convergence of the asynchronous Q-learning modeled as a continuous-time switching system, where notions from switching system theory are used to prove its asymptotic stability without using explicit Lyapunov arguments. However, to prove stability, restrictive conditions, such as quasi-monotonicity, must be satisfied for the underlying switching systems, which makes it hard to easily generalize the analysis method to other reinforcement learning algorithms, such as the smooth Q-learning variants. In this paper, we present a more general and unified convergence analysis that improves upon the switching system approach and can analyze Q-learning and its smooth variants. The proposed analysis is motivated by previous work on the convergence of synchronous Q-learning based on $p$-norm serving as a Lyapunov function. However, the proposed analysis addresses more general ODE models that can cover both asynchronous Q-learning and its smooth versions with simpler frameworks.
Read more4/24/2024
🌿
0
Does DQN Learn?
Aditya Gopalan, Gugan Thoppe
For a reinforcement learning method to be useful, the policy it estimates in the limit must be superior to the initial guess, at least on average. In this work, we show that the widely used Deep Q-Network (DQN) fails to meet even this basic criterion, even when it gets to see all possible states and actions infinitely often (a condition that ensures tabular Q-learning's convergence to the optimal Q-value). Our work's key highlights are as follows. First, we numerically show that DQN generally has a non-trivial probability of producing a policy worse than the initial one. Second, we give a theoretical explanation for this behavior in the context of linear DQN, wherein we replace the neural network with a linear function approximation but retain DQN's other key ideas, such as experience replay, target network, and $epsilon$-greedy exploration. Our main result is that the tail behaviors of linear DQN are governed by invariant sets of a deterministic differential inclusion, a set-valued generalization of a differential equation. Notably, we show that these invariant sets need not align with locally optimal policies, thus explaining DQN's pathological behaviors, such as convergence to sub-optimal policies and policy oscillation. We also provide a scenario where the limiting policy is always the worst. Our work addresses a longstanding gap in understanding the behaviors of Q-learning with function approximation and $epsilon$-greedy exploration.
Read more9/24/2024

0
Learning to Control Unknown Strongly Monotone Games
Siddharth Chandak, Ilai Bistritz, Nicholas Bambos
Consider $N$ players each with a $d$-dimensional action set. Each of the players' utility functions includes their reward function and a linear term for each dimension, with coefficients that are controlled by the manager. We assume that the game is strongly monotone, so if each player runs gradient descent, the dynamics converge to a unique Nash equilibrium (NE). The NE is typically inefficient in terms of global performance. The resulting global performance of the system can be improved by imposing $K$-dimensional linear constraints on the NE. We therefore want the manager to pick the controlled coefficients that impose the desired constraint on the NE. However, this requires knowing the players' reward functions and their action sets. Obtaining this game structure information is infeasible in a large-scale network and violates the users' privacy. To overcome this, we propose a simple algorithm that learns to shift the NE of the game to meet the linear constraints by adjusting the controlled coefficients online. Our algorithm only requires the linear constraints violation as feedback and does not need to know the reward functions or the action sets. We prove that our algorithm, which is based on two time-scale stochastic approximation, guarantees convergence with probability 1 to the set of NE that meet target linear constraints. We then provide a mean square convergence rate of $O(t^{-1/4})$ for our algorithm. This is the first such bound for two time-scale stochastic approximation where the slower time-scale is a fixed point iteration with a non-expansive mapping. We demonstrate how our scheme can be applied to optimizing a global quadratic cost at NE and load balancing in resource allocation games. We provide simulations of our algorithm for these scenarios.
Read more7/2/2024