Q-Sparse: All Large Language Models can be Fully Sparsely-Activated

550

Sign in to get full access
Overview
- The paper "Q-Sparse: All Large Language Models can be Fully Sparsely-Activated" presents a novel approach called Q-Sparse that enables large language models (LLMs) to be fully sparsely-activated.
- This means that only a small fraction of the model's parameters are active at any given time, leading to significant reductions in computational cost and memory usage.
- The authors demonstrate that Q-Sparse can be applied to a wide range of LLM architectures, including transformers and recurrent neural networks, without compromising performance.
Plain English Explanation
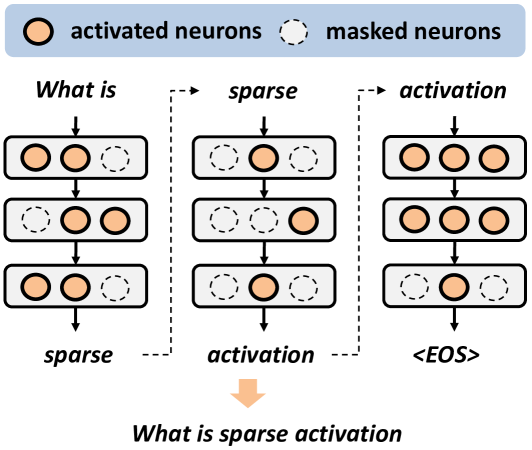
The paper introduces a technique called Q-Sparse that allows large language models to operate in a highly efficient way. Large language models are powerful AI systems that can understand and generate human-like text, but they typically require a lot of computational resources to run.
Q-Sparse solves this problem by only activating a small fraction of the model's parameters at any given time. This means that the model can achieve the same level of performance as a traditional large language model, but with much lower computational costs and memory requirements.
The key idea behind Q-Sparse is to reorganize the model's architecture in a way that enables this selective activation. The authors show that this approach can be applied to a wide variety of large language model architectures, including transformers and recurrent neural networks, without compromising the model's performance.
This is an important advancement because it could make large language models more accessible and practical for a wider range of applications, including on resource-constrained devices like smartphones or edge computing systems.
Technical Explanation
The paper introduces a new technique called Q-Sparse that enables large language models (LLMs) to be fully sparsely-activated. This means that only a small fraction of the model's parameters are active at any given time, leading to significant reductions in computational cost and memory usage.
The authors demonstrate that Q-Sparse can be applied to a wide range of LLM architectures, including transformers and recurrent neural networks, without compromising performance. The key idea behind Q-Sparse is to reorganize the model's architecture in a way that allows for selective activation of parameters.
Specifically, the authors propose a novel parameter sharing scheme and a sparsity-inducing training objective that encourages the model to learn an efficient sparse activation pattern. This is achieved by introducing a set of learnable "query" vectors that determine which parameters should be activated for a given input.
Through extensive experiments, the authors show that Q-Sparse can achieve up to 99% sparsity in the model's activations while maintaining competitive performance on a range of language modeling benchmarks. They also demonstrate the versatility of Q-Sparse by applying it to different LLM architectures, including Transformers, LAMDA, and ProSparse.
Critical Analysis
The Q-Sparse approach presented in this paper is a significant contribution to the field of efficient large language model design. By enabling full sparsity in the model's activations, the authors have addressed a key challenge in making LLMs more practical and accessible.
However, the paper does not fully address the potential limitations of the Q-Sparse approach. For example, the authors do not discuss how the sparsity pattern learned by the model might affect the interpretability or robustness of the LLM's outputs. Additionally, the paper does not explore the potential trade-offs between the level of sparsity achieved and the model's performance on more complex language tasks.
Furthermore, the paper could have benefited from a more thorough comparison to other sparsity-inducing techniques, such as One-Shot Sensitivity-Aware Mixed Sparsity Pruning or Learn to be Efficient: Build Structured Sparsity. This would help readers understand the unique advantages and limitations of the Q-Sparse approach.
Overall, the Q-Sparse technique represents an important step forward in making large language models more efficient and practical, but further research is needed to fully understand its implications and potential drawbacks.
Conclusion
The paper "Q-Sparse: All Large Language Models can be Fully Sparsely-Activated" presents a novel approach that enables large language models to operate in a highly efficient manner by selectively activating only a small fraction of their parameters. This has the potential to significantly reduce the computational and memory requirements of LLMs, making them more accessible and practical for a wider range of applications.
The key contribution of the Q-Sparse technique is its ability to achieve up to 99% sparsity in the model's activations while maintaining competitive performance on a range of language modeling benchmarks. The authors demonstrate the versatility of their approach by applying it to different LLM architectures, including transformers and recurrent neural networks.
While the paper represents an important advancement in the field of efficient LLM design, further research is needed to fully understand the implications and potential limitations of the Q-Sparse approach. Nonetheless, this work lays the foundation for developing more resource-efficient large language models that can be deployed in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
550
Q-Sparse: All Large Language Models can be Fully Sparsely-Activated
Hongyu Wang, Shuming Ma, Ruiping Wang, Furu Wei
We introduce, Q-Sparse, a simple yet effective approach to training sparsely-activated large language models (LLMs). Q-Sparse enables full sparsity of activations in LLMs which can bring significant efficiency gains in inference. This is achieved by applying top-K sparsification to the activations and the straight-through-estimator to the training. We also introduce Block Q-Sparse for batch training and inference. The key results from this work are, (1) Q-Sparse can achieve results comparable to those of baseline LLMs while being much more efficient at inference time; (2) We present an inference-optimal scaling law for sparsely-activated LLMs; (3) Q-Sparse is effective in different settings, including training-from-scratch, continue-training of off-the-shelf LLMs, and finetuning; (4) Q-Sparse works for both full-precision and 1-bit LLMs (e.g., BitNet b1.58). Particularly, the synergy of BitNet b1.58 and Q-Sparse (can be equipped with MoE) provides the cornerstone and a clear path to revolutionize the efficiency, including cost and energy consumption, of future LLMs.
Read more7/25/2024

0
Training-Free Activation Sparsity in Large Language Models
James Liu, Pragaash Ponnusamy, Tianle Cai, Han Guo, Yoon Kim, Ben Athiwaratkun
Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$times$ and 1.8$times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.
Read more8/28/2024
0
Achieving Sparse Activation in Small Language Models
Jifeng Song, Kai Huang, Xiangyu Yin, Boyuan Yang, Wei Gao
Sparse activation, which selectively activates only an input-dependent set of neurons in inference, is a useful technique to reduce the computing cost of Large Language Models (LLMs) without retraining or adaptation efforts. However, whether it can be applied to the recently emerging Small Language Models (SLMs) remains questionable, because SLMs are generally less over-parameterized than LLMs. In this paper, we aim to achieve sparse activation in SLMs. We first show that the existing sparse activation schemes in LLMs that build on neurons' output magnitudes cannot be applied to SLMs, and activating neurons based on their attribution scores is a better alternative. Further, we demonstrated and quantified the large errors of existing attribution metrics when being used for sparse activation, due to the interdependency among attribution scores of neurons across different layers. Based on these observations, we proposed a new attribution metric that can provably correct such errors and achieve precise sparse activation. Experiments over multiple popular SLMs and datasets show that our approach can achieve 80% sparsification ratio with <5% model accuracy loss, comparable to the sparse activation achieved in LLMs. The source code is available at: https://github.com/pittisl/Sparse-Activation.
Read more6/12/2024
❗
0
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
Abhinav Agarwalla, Abhay Gupta, Alexandre Marques, Shubhra Pandit, Michael Goin, Eldar Kurtic, Kevin Leong, Tuan Nguyen, Mahmoud Salem, Dan Alistarh, Sean Lie, Mark Kurtz
Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
Read more5/7/2024