Training-Free Activation Sparsity in Large Language Models

0

Sign in to get full access
Overview
- This paper explores a novel technique for inducing sparsity in the activations of large language models without the need for training.
- The proposed approach, called Training-Free Activation Sparsity (TFAS), can significantly reduce the computational and memory footprint of these models while maintaining their performance.
- The paper presents experiments demonstrating the effectiveness of TFAS on several popular large language models, including GPT-2, BERT, and T5.
Plain English Explanation
Imagine you have a very powerful computer that can understand and generate human language, known as a large language model. These models are incredibly complex and take up a lot of space and computing power, making them costly to run. The researchers in this paper have developed a new technique called Training-Free Activation Sparsity (TFAS) that can make these models more efficient without sacrificing their capabilities.
The key idea behind TFAS is to identify and remove the parts of the model that are not being used very much during the language tasks it performs. This process, called "inducing sparsity," reduces the model's size and computational requirements without significantly affecting its overall performance. What's special about TFAS is that it can do this without having to go through a lengthy and expensive training process, which is typically required for other sparsity techniques.
The researchers tested TFAS on several popular large language models, including GPT-2, BERT, and T5. The results showed that TFAS could significantly reduce the size and computational requirements of these models without compromising their performance on a variety of language tasks.
Technical Explanation
The paper introduces a novel technique called Training-Free Activation Sparsity (TFAS) that can induce sparsity in the activations of large language models without the need for additional training. Sparsity refers to the property of having many zero-valued elements in the model's internal representations, which can lead to significant reductions in computational and memory requirements.
The key steps of the TFAS approach are:
- Activation Analysis: The researchers analyze the distribution of activations in the pre-trained language model to identify the most important and least important activations.
- Activation Pruning: Based on the analysis, the researchers selectively prune the least important activations, effectively inducing sparsity in the model's internal representations.
- Finetuning: The researchers finetune the pruned model on a small dataset to recover any potential performance degradation caused by the pruning process.
The paper presents extensive experiments on several popular large language models, including GPT-2, BERT, and T5. The results show that TFAS can achieve significant reductions in model size and computational requirements (up to 90% in some cases) while maintaining the original model's performance on a variety of language tasks.
The authors also discuss the potential limitations of TFAS, such as the difficulty of generalizing the pruning strategy across different model architectures and tasks. They suggest that further research is needed to develop more robust and adaptable sparsity-inducing techniques for large language models.
Critical Analysis
The paper presents a compelling and well-executed approach for inducing sparsity in large language models without the need for extensive training. The key strength of TFAS is its ability to achieve substantial reductions in model size and computational requirements while preserving the original model's performance, which is a significant practical advantage.
One potential limitation of the TFAS approach is its reliance on a finetuning step to recover any performance degradation caused by the pruning process. While the authors demonstrate that this finetuning step is effective, it still adds an extra step to the model optimization workflow, which could be a drawback in some real-world applications.
Additionally, the paper does not provide a thorough analysis of the generalization capabilities of TFAS across different model architectures and tasks. The authors acknowledge this limitation and suggest that further research is needed to develop more robust and adaptable sparsity-inducing techniques.
It would also be valuable for the authors to explore the implications of TFAS for the interpretability and transparency of large language models. By selectively pruning activations, TFAS may introduce changes in the model's internal representations, which could have implications for understanding and explaining the model's decision-making process.
Overall, the TFAS approach represents an important contribution to the field of efficient large language models. The paper's findings have the potential to significantly impact the practical deployment of these powerful models in resource-constrained environments.
Conclusion
This paper introduces a novel technique called Training-Free Activation Sparsity (TFAS) that can induce sparsity in the activations of large language models without the need for additional training. The authors demonstrate the effectiveness of TFAS on several popular models, including GPT-2, BERT, and T5, achieving significant reductions in model size and computational requirements while maintaining the original model's performance.
The TFAS approach represents an important advancement in the field of efficient large language models, as it provides a way to optimize these powerful models for practical deployment in resource-constrained environments. The paper's findings have the potential to enable a wider adoption of large language models and facilitate their use in a variety of real-world applications.
While the paper highlights the strengths of TFAS, it also acknowledges the need for further research to address the limitations, such as the generalization of the pruning strategy across different model architectures and tasks. Exploring the implications of TFAS for model interpretability and transparency could also be a fruitful avenue for future work.
Overall, this paper makes a significant contribution to the ongoing efforts to develop efficient and practical large language models, and the TFAS technique represents an exciting step forward in this important research area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training-Free Activation Sparsity in Large Language Models
James Liu, Pragaash Ponnusamy, Tianle Cai, Han Guo, Yoon Kim, Ben Athiwaratkun
Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$times$ and 1.8$times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.
Read more8/28/2024
0
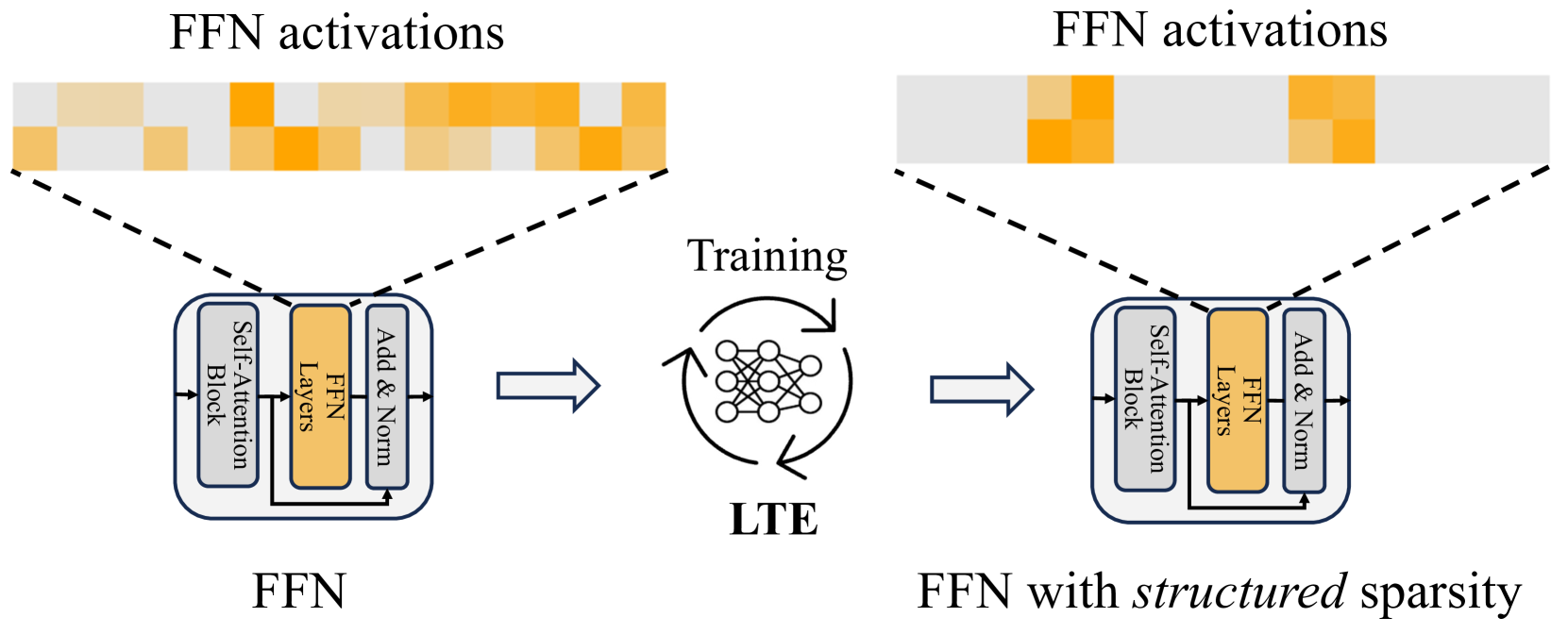
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Haizhong Zheng, Xiaoyan Bai, Xueshen Liu, Z. Morley Mao, Beidi Chen, Fan Lai, Atul Prakash
Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. However, existing methods only focus on utilizing this naturally formed activation sparsity in a post-training setting, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel training algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like LLaMA using non-ReLU activations. Extensive evaluation on language understanding, language generation, and instruction tuning tasks show that LTE consistently outperforms SOTA baselines. Along with our hardware-aware custom kernel implementation, LTE reduces LLaMA2-7B inference latency by 25% at 50% sparsity.
Read more6/5/2024
7
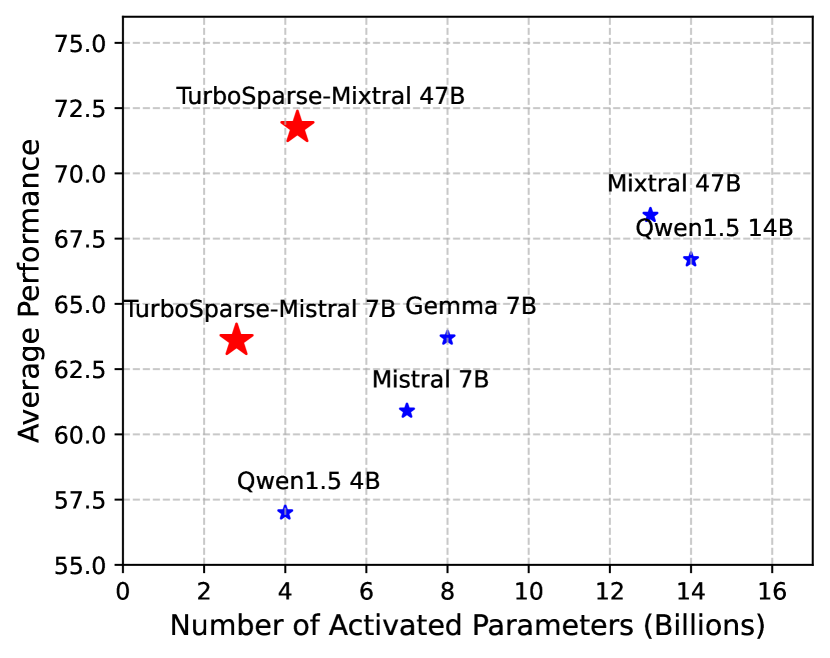
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
Yixin Song, Haotong Xie, Zhengyan Zhang, Bo Wen, Li Ma, Zeyu Mi, Haibo Chen
Exploiting activation sparsity is a promising approach to significantly accelerating the inference process of large language models (LLMs) without compromising performance. However, activation sparsity is determined by activation functions, and commonly used ones like SwiGLU and GeGLU exhibit limited sparsity. Simply replacing these functions with ReLU fails to achieve sufficient sparsity. Moreover, inadequate training data can further increase the risk of performance degradation. To address these challenges, we propose a novel dReLU function, which is designed to improve LLM activation sparsity, along with a high-quality training data mixture ratio to facilitate effective sparsification. Additionally, we leverage sparse activation patterns within the Feed-Forward Network (FFN) experts of Mixture-of-Experts (MoE) models to further boost efficiency. By applying our neuron sparsification method to the Mistral and Mixtral models, only 2.5 billion and 4.3 billion parameters are activated per inference iteration, respectively, while achieving even more powerful model performance. Evaluation results demonstrate that this sparsity achieves a 2-5x decoding speedup. Remarkably, on mobile phones, our TurboSparse-Mixtral-47B achieves an inference speed of 11 tokens per second. Our models are available at url{https://huggingface.co/PowerInfer}
Read more6/12/2024
0
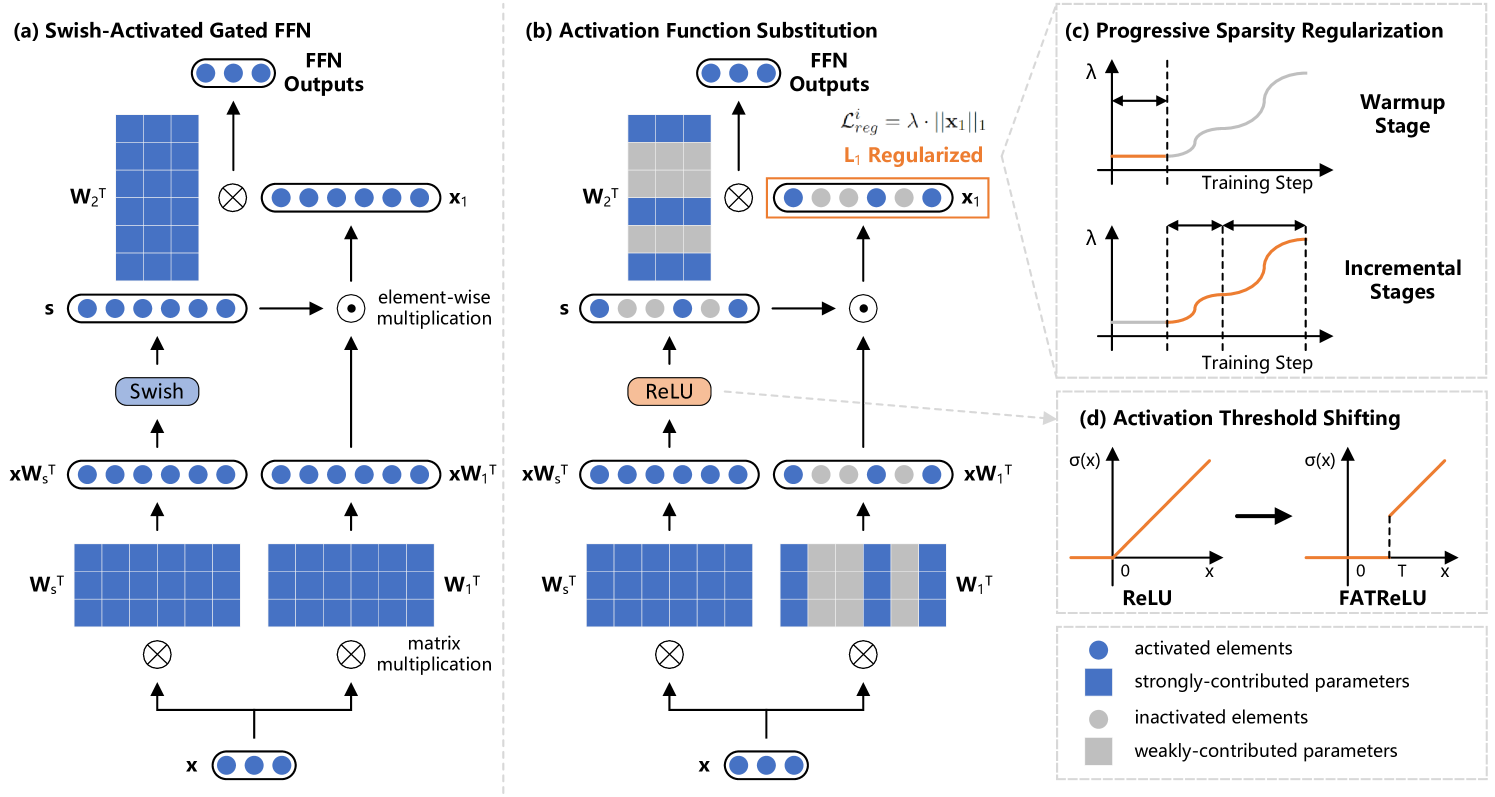
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Chenyang Song, Xu Han, Zhengyan Zhang, Shengding Hu, Xiyu Shi, Kuai Li, Chen Chen, Zhiyuan Liu, Guangli Li, Tao Yang, Maosong Sun
Activation sparsity refers to the existence of considerable weakly-contributed elements among activation outputs. As a prevalent property of the models using the ReLU activation function, activation sparsity has been proven a promising paradigm to boost model inference efficiency. Nevertheless, most large language models (LLMs) adopt activation functions without intrinsic activation sparsity (e.g., GELU and Swish). Some recent efforts have explored introducing ReLU or its variants as the substitutive activation function to help LLMs achieve activation sparsity and inference acceleration, but few can simultaneously obtain high sparsity and comparable model performance. This paper introduces a simple and effective sparsification method named ProSparse to push LLMs for higher activation sparsity while maintaining comparable performance. Specifically, after substituting the activation function of LLMs with ReLU, ProSparse adopts progressive sparsity regularization with a factor smoothly increasing along the multi-stage sine curves. This can enhance activation sparsity and mitigate performance degradation by avoiding radical shifts in activation distributions. With ProSparse, we obtain high sparsity of 89.32% for LLaMA2-7B, 88.80% for LLaMA2-13B, and 87.89% for end-size MiniCPM-1B, respectively, achieving comparable performance to their original Swish-activated versions. These present the most sparsely activated models among open-source LLaMA versions and competitive end-size models, considerably surpassing ReluLLaMA-7B (66.98%) and ReluLLaMA-13B (71.56%). Our inference acceleration experiments further demonstrate the significant practical acceleration potential of LLMs with higher activation sparsity, obtaining up to 4.52$times$ inference speedup.
Read more7/4/2024