QR factorization of ill-conditioned tall-and-skinny matrices on distributed-memory systems

0
🏅
Sign in to get full access
Overview
- Presents a novel algorithm for computing the QR factorization of extremely ill-conditioned tall-and-skinny matrices on distributed memory systems.
- The algorithm is based on the communication-avoiding CholeskyQR2 algorithm and its block Gram-Schmidt variant.
- Currently, there is no distributed GPU version of this algorithm available, which prevents its application to very large matrices.
- Provides a distributed implementation of the algorithm and introduces a modified version to improve performance for extremely ill-conditioned matrices.
Plain English Explanation
The paper describes a new way to efficiently calculate the QR factorization of large, poorly-conditioned matrices on computer systems with distributed memory. The QR factorization is a mathematical technique used in many fields, such as linear system solving and matrix regression.
The key innovation is a modification to an existing algorithm called CholeskyQR2, which makes it more numerically stable and able to handle extremely ill-conditioned matrices. This is important because many real-world matrices have condition numbers (a measure of how well-behaved the matrix is) as high as 10^15, which can cause issues for standard algorithms.
The new algorithm interleaves the steps of the CholeskyQR2 algorithm with an additional orthogonalization process. This ensures that the updates are performed using fully orthogonalized matrix panels, leading to better numerical stability and accuracy.
The researchers also provide a distributed implementation of the algorithm, which allows it to be used on large-scale, parallel computing systems. This is crucial for applications that require processing very large matrices, such as large language model training or accelerated matrix factorization.
Technical Explanation
The paper presents a novel algorithm for computing the QR factorization of extremely ill-conditioned tall-and-skinny matrices on distributed memory systems. The algorithm is based on the communication-avoiding CholeskyQR2 algorithm and its block Gram-Schmidt variant.
The CholeskyQR2 algorithm is a communication-avoiding method that reduces the amount of data movement required during the QR factorization process. The block Gram-Schmidt variant improves the numerical stability of CholeskyQR2 and significantly reduces the loss of orthogonality, even for matrices with condition numbers up to 10^15.
The key innovation of the proposed approach lies in the interleaving of the CholeskyQR steps with the Gram-Schmidt orthogonalization. This ensures that the update steps are performed with fully orthogonalized panels, leading to improved orthogonality and numerical stability compared to the original CholeskyQR2 algorithm.
The researchers provide a distributed implementation of the algorithm, which allows it to be used on large-scale, parallel computing systems. They also introduce a modified version of the algorithm that further improves the performance, especially for extremely ill-conditioned matrices.
Weak scaling tests with the researchers' test matrices show significant performance improvements compared to state-of-the-art Householder-based QR factorization algorithms available in ScaLAPACK. The new algorithm outperforms these algorithms by a factor of 6 on CPU-only systems and up to 80 times on GPU-based systems with distributed memory.
Critical Analysis
The paper addresses an important problem in numerical linear algebra, namely the efficient computation of the QR factorization of large, ill-conditioned matrices. The researchers' approach of modifying the CholeskyQR2 algorithm to improve numerical stability and parallelizing it for distributed memory systems is a significant contribution to the field.
One potential limitation of the research is that the performance improvements are demonstrated using a limited set of test matrices. It would be valuable to see the algorithm evaluated on a wider range of real-world datasets to better understand its practical applicability and limitations.
Additionally, the paper does not provide a detailed comparison to other state-of-the-art distributed QR factorization algorithms, such as those based on the Householder transformation. While the reported speedups are impressive, a more comprehensive benchmarking against alternative approaches would strengthen the claims.
Future research could also investigate the algorithm's behavior and performance on heterogeneous computing architectures, such as those combining CPUs and GPUs, to further expand its capabilities and potential applications.
Conclusion
The paper presents a novel algorithm for computing the QR factorization of extremely ill-conditioned, tall-and-skinny matrices on distributed memory systems. The key innovation is the interleaving of the CholeskyQR2 algorithm with Gram-Schmidt orthogonalization, which improves numerical stability and accuracy.
The distributed implementation of the algorithm enables its use on large-scale, parallel computing systems, making it a valuable tool for applications that require processing very large matrices, such as large language model training or accelerated matrix factorization.
The researchers' work demonstrates significant performance improvements over state-of-the-art QR factorization algorithms, particularly on GPU-based distributed memory systems. This advancement has the potential to drive further progress in numerical linear algebra and enable the handling of increasingly complex, ill-conditioned problems in various scientific and engineering domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
QR factorization of ill-conditioned tall-and-skinny matrices on distributed-memory systems
Nenad Miji'c, Abhiram Kaushik, Davor Davidovi'c
In this paper we present a novel algorithm developed for computing the QR factorisation of extremely ill-conditioned tall-and-skinny matrices on distributed memory systems. The algorithm is based on the communication-avoiding CholeskyQR2 algorithm and its block Gram-Schmidt variant. The latter improves the numerical stability of the CholeskyQR2 algorithm and significantly reduces the loss of orthogonality even for matrices with condition numbers up to $10^{15}$. Currently, there is no distributed GPU version of this algorithm available in the literature which prevents the application of this method to very large matrices. In our work we provide a distributed implementation of this algorithm and also introduce a modified version that improves the performance, especially in the case of extremely ill-conditioned matrices. The main innovation of our approach lies in the interleaving of the CholeskyQR steps with the Gram-Schmidt orthogonalisation, which ensures that update steps are performed with fully orthogonalised panels. The obtained orthogonality and numerical stability of our modified algorithm is equivalent to CholeskyQR2 with Gram-Schmidt and other state-of-the-art methods. Weak scaling tests performed with our test matrices show significant performance improvements. In particular, our algorithm outperforms state-of-the-art Householder-based QR factorisation algorithms available in ScaLAPACK by a factor of $6$ on CPU-only systems and up to $80times$ on GPU-based systems with distributed memory.
Read more5/8/2024

0
New!In-depth Analysis of Low-rank Matrix Factorisation in a Federated Setting
Constantin Philippenko, Kevin Scaman, Laurent Massouli'e
We analyze a distributed algorithm to compute a low-rank matrix factorization on $N$ clients, each holding a local dataset $mathbf{S}^i in mathbb{R}^{n_i times d}$, mathematically, we seek to solve $min_{mathbf{U}^i in mathbb{R}^{n_itimes r}, mathbf{V}in mathbb{R}^{d times r} } frac{1}{2} sum_{i=1}^N |mathbf{S}^i - mathbf{U}^i mathbf{V}^top|^2_{text{F}}$. Considering a power initialization of $mathbf{V}$, we rewrite the previous smooth non-convex problem into a smooth strongly-convex problem that we solve using a parallel Nesterov gradient descent potentially requiring a single step of communication at the initialization step. For any client $i$ in ${1, dots, N}$, we obtain a global $mathbf{V}$ in $mathbb{R}^{d times r}$ common to all clients and a local variable $mathbf{U}^i$ in $mathbb{R}^{n_i times r}$. We provide a linear rate of convergence of the excess loss which depends on $sigma_{max} / sigma_{r}$, where $sigma_{r}$ is the $r^{mathrm{th}}$ singular value of the concatenation $mathbf{S}$ of the matrices $(mathbf{S}^i)_{i=1}^N$. This result improves the rates of convergence given in the literature, which depend on $sigma_{max}^2 / sigma_{min}^2$. We provide an upper bound on the Frobenius-norm error of reconstruction under the power initialization strategy. We complete our analysis with experiments on both synthetic and real data.
Read more9/16/2024
📈
0
Banded Square Root Matrix Factorization for Differentially Private Model Training
Nikita Kalinin, Christoph Lampert
Current state-of-the-art methods for differentially private model training are based on matrix factorization techniques. However, these methods suffer from high computational overhead because they require numerically solving a demanding optimization problem to determine an approximately optimal factorization prior to the actual model training. In this work, we present a new matrix factorization approach, BSR, which overcomes this computational bottleneck. By exploiting properties of the standard matrix square root, BSR allows to efficiently handle also large-scale problems. For the key scenario of stochastic gradient descent with momentum and weight decay, we even derive analytical expressions for BSR that render the computational overhead negligible. We prove bounds on the approximation quality that hold both in the centralized and in the federated learning setting. Our numerical experiments demonstrate that models trained using BSR perform on par with the best existing methods, while completely avoiding their computational overhead.
Read more5/24/2024
0
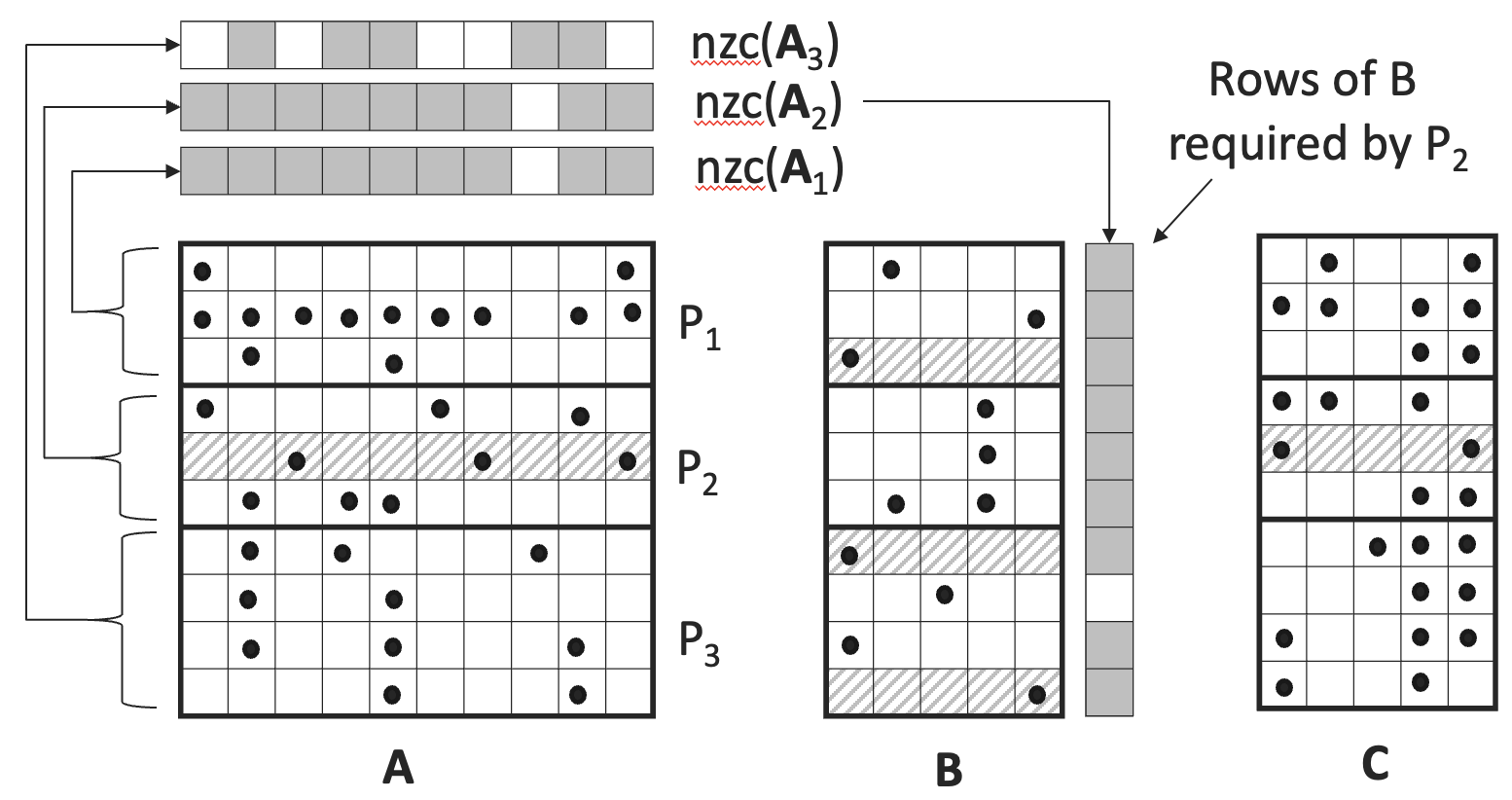
Distributed-Memory Parallel Algorithms for Sparse Matrix and Sparse Tall-and-Skinny Matrix Multiplication
Isuru Ranawaka, Md Taufique Hussain, Charles Block, Gerasimos Gerogiannis, Josep Torrellas, Ariful Azad
We consider a sparse matrix-matrix multiplication (SpGEMM) setting where one matrix is square and the other is tall and skinny. This special variant, called TS-SpGEMM, has important applications in multi-source breadth-first search, influence maximization, sparse graph embedding, and algebraic multigrid solvers. Unfortunately, popular distributed algorithms like sparse SUMMA deliver suboptimal performance for TS-SpGEMM. To address this limitation, we develop a novel distributed-memory algorithm tailored for TS-SpGEMM. Our approach employs customized 1D partitioning for all matrices involved and leverages sparsity-aware tiling for efficient data transfers. In addition, it minimizes communication overhead by incorporating both local and remote computations. On average, our TS-SpGEMM algorithm attains 5x performance gains over 2D and 3D SUMMA. Furthermore, we use our algorithm to implement multi-source breadth-first search and sparse graph embedding algorithms and demonstrate their scalability up to 512 Nodes (or 65,536 cores) on NERSC Perlmutter.
Read more8/23/2024