Quantifying the effect of X-ray scattering for data generation in real-time defect detection

0
📊
Sign in to get full access
Overview
- X-ray imaging is widely used to detect defects in industrial products on a conveyor belt
- In-line detection requires highly accurate, robust, and fast algorithms
- Deep Convolutional Neural Networks (DCNNs) can satisfy these requirements with enough labeled data
- Collecting large labeled datasets is challenging, so methods of X-ray image generation are considered
- X-ray scattering is computationally expensive to simulate but can greatly affect the accuracy of generated images
- The goal is to quantitatively evaluate the effect of scattering on defect detection
Plain English Explanation
Manufacturers often use X-ray imaging to check their products for defects as they move along an assembly line. To do this quickly and reliably, they need very accurate and fast computer algorithms. Deep learning models like Convolutional Neural Networks (CNNs) can meet these requirements, but they need a lot of labeled training data, which is hard to collect.
Instead, the researchers tried generating artificial X-ray images. They found that accounting for X-ray scattering - when the rays bounce around inside the object - is important for making the generated images realistic. Simulating scattering is computationally expensive, so the researchers wanted to understand how much it really matters for detecting defects.
Technical Explanation
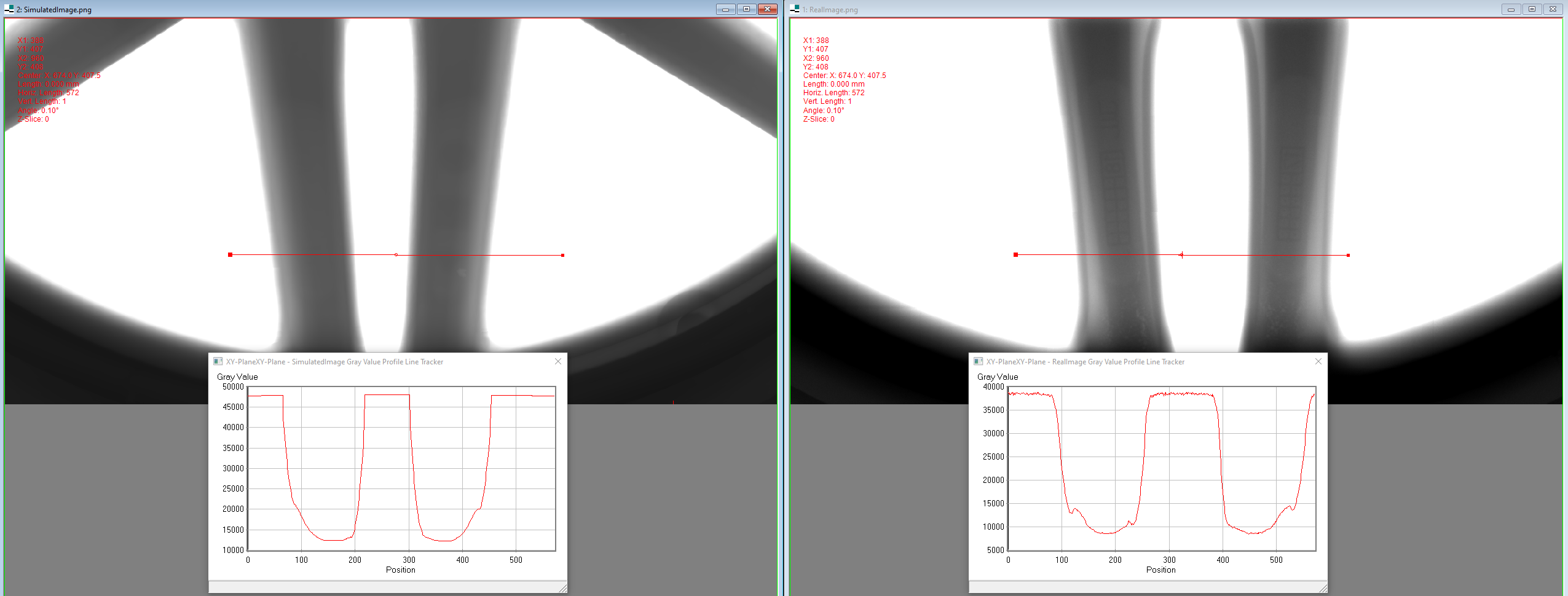
The researchers used Monte-Carlo simulation to generate X-ray scattering distributions, then trained CNN models on data with and without scattering. They applied the trained models to the same test datasets and compared their probability of detection performance, focusing on the size of the smallest detectable defect.
For a model problem of detecting defects in cylinders, they found that when trained on data without scattering, the CNNs could reliably detect defects larger than 1.3 mm. Including scattering in the training data improved performance by less than 5%. However, for cases with a large scattering-to-primary ratio (1 < SPR < 5), the difference in performance could reach 15%, affecting the ability to detect defects around 0.4 mm smaller.
Critical Analysis
The researchers acknowledged that excluding scattering has the biggest impact on detecting the smallest defects, and the difference decreases as defect size increases. They also noted that the scattering-to-primary ratio significantly affects detection performance, highlighting the need for accurate simulation of this effect.
One potential limitation is that the study focused on a single model problem of defect detection in cylinders. The generalizability of these findings to other industrial products and defect types could be explored further. Additionally, the researchers did not investigate the computational cost tradeoffs of including scattering simulation in the training data generation process.
Conclusion
This research quantifies the importance of accurately modeling X-ray scattering when generating synthetic training data for defect detection algorithms. While excluding scattering has the largest impact on the smallest detectable defects, it becomes less critical for larger defects. The scattering-to-primary ratio is a key factor in determining the required accuracy of the data generation process. These insights can help manufacturers optimize their X-ray inspection systems and deep learning models for industrial quality control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Quantifying the effect of X-ray scattering for data generation in real-time defect detection
Vladyslav Andriiashen, Robert van Liere, Tristan van Leeuwen, K. Joost Batenburg
Background: X-ray imaging is widely used for the non-destructive detection of defects in industrial products on a conveyor belt. In-line detection requires highly accurate, robust, and fast algorithms. Deep Convolutional Neural Networks (DCNNs) satisfy these requirements when a large amount of labeled data is available. To overcome the challenge of collecting these data, different methods of X-ray image generation are considered. Objective: Depending on the desired degree of similarity to real data, different physical effects should either be simulated or can be ignored. X-ray scattering is known to be computationally expensive to simulate, and this effect can greatly affect the accuracy of a generated X-ray image. We aim to quantitatively evaluate the effect of scattering on defect detection. Methods: Monte-Carlo simulation is used to generate X-ray scattering distribution. DCNNs are trained on the data with and without scattering and applied to the same test datasets. Probability of Detection (POD) curves are computed to compare their performance, characterized by the size of the smallest detectable defect. Results: We apply the methodology to a model problem of defect detection in cylinders. When trained on data without scattering, DCNNs reliably detect defects larger than 1.3 mm, and using data with scattering improves performance by less than 5%. If the analysis is performed on the cases with large scattering-to-primary ratio ($1 < SPR < 5$), the difference in performance could reach 15% (approx. 0.4 mm). Conclusion: Excluding the scattering signal from the training data has the largest effect on the smallest detectable defects, and the difference decreases for larger defects. The scattering-to-primary ratio has a significant effect on detection performance and the required accuracy of data generation.
Read more8/22/2024
0
Towards Reducing Data Acquisition and Labeling for Defect Detection using Simulated Data
Lukas Malte Kemeter, Rasmus Hvingelby, Paulina Sierak, Tobias Schon, Bishwajit Gosswam
In many manufacturing settings, annotating data for machine learning and computer vision is costly, but synthetic data can be generated at significantly lower cost. Substituting the real-world data with synthetic data is therefore appealing for many machine learning applications that require large amounts of training data. However, relying solely on synthetic data is frequently inadequate for effectively training models that perform well on real-world data, primarily due to domain shifts between the synthetic and real-world data. We discuss approaches for dealing with such a domain shift when detecting defects in X-ray scans of aluminium wheels. Using both simulated and real-world X-ray images, we train an object detection model with different strategies to identify the training approach that generates the best detection results while minimising the demand for annotated real-world training samples. Our preliminary findings suggest that the sim-2-real domain adaptation approach is more cost-efficient than a fully supervised oracle - if the total number of available annotated samples is fixed. Given a certain number of labeled real-world samples, training on a mix of synthetic and unlabeled real-world data achieved comparable or even better detection results at significantly lower cost. We argue that future research into the cost-efficiency of different training strategies is important for a better understanding of how to allocate budget in applied machine learning projects.
Read more6/28/2024

0
Attenuation-adjusted deep learning of pore defects in 2D radiographs of additive manufacturing powders
Andreas Bjerregaard, David Schumacher, Jon Sporring
The presence of gas pores in metal feedstock powder for additive manufacturing greatly affects the final AM product. Since current porosity analysis often involves lengthy X-ray computed tomography (XCT) scans with a full rotation around the sample, motivation exists to explore methods that allow for high throughput -- possibly enabling in-line porosity analysis during manufacturing. Through labelling pore pixels on single 2D radiographs of powders, this work seeks to simulate such future efficient setups. High segmentation accuracy is achieved by combining a model of X-ray attenuation through particles with a variant of the widely applied UNet architecture; notably, F1-score increases by $11.4%$ compared to the baseline UNet. The proposed pore segmentation is enabled by: 1) pretraining on synthetic data, 2) making tight particle cutouts, and 3) subtracting an ideal particle without pores generated from a distance map inspired by Lambert-Beers law. This paper explores four image processing methods, where the fastest (yet still unoptimized) segments a particle in mean $0.014s$ time with F1-score $0.78$, and the most accurate in $0.291s$ with F1-score $0.87$. Due to their scalable nature, these strategies can be involved in making high throughput porosity analysis of metal feedstock powder for additive manufacturing.
Read more8/6/2024

0
Generating Realistic X-ray Scattering Images Using Stable Diffusion and Human-in-the-loop Annotations
Zhuowen Zhao, Xiaoya Chong, Tanny Chavez, Alexander Hexemer
We fine-tuned a foundational stable diffusion model using X-ray scattering images and their corresponding descriptions to generate new scientific images from given prompts. However, some of the generated images exhibit significant unrealistic artifacts, commonly known as hallucinations. To address this issue, we trained various computer vision models on a dataset composed of 60% human-approved generated images and 40% experimental images to detect unrealistic images. The classified images were then reviewed and corrected by human experts, and subsequently used to further refine the classifiers in next rounds of training and inference. Our evaluations demonstrate the feasibility of generating high-fidelity, domain-specific images using a fine-tuned diffusion model. We anticipate that generative AI will play a crucial role in enhancing data augmentation and driving the development of digital twins in scientific research facilities.
Read more8/26/2024