Towards Reducing Data Acquisition and Labeling for Defect Detection using Simulated Data
2406.19175
0
0
Abstract
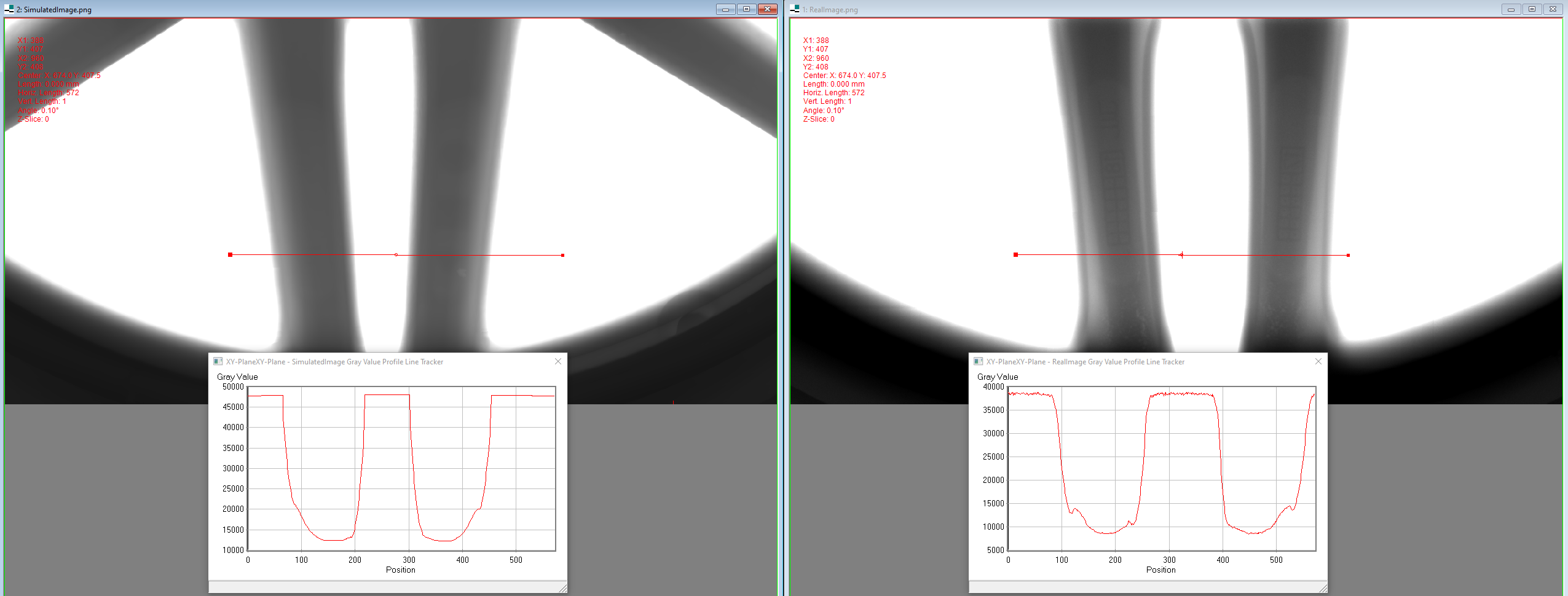
In many manufacturing settings, annotating data for machine learning and computer vision is costly, but synthetic data can be generated at significantly lower cost. Substituting the real-world data with synthetic data is therefore appealing for many machine learning applications that require large amounts of training data. However, relying solely on synthetic data is frequently inadequate for effectively training models that perform well on real-world data, primarily due to domain shifts between the synthetic and real-world data. We discuss approaches for dealing with such a domain shift when detecting defects in X-ray scans of aluminium wheels. Using both simulated and real-world X-ray images, we train an object detection model with different strategies to identify the training approach that generates the best detection results while minimising the demand for annotated real-world training samples. Our preliminary findings suggest that the sim-2-real domain adaptation approach is more cost-efficient than a fully supervised oracle - if the total number of available annotated samples is fixed. Given a certain number of labeled real-world samples, training on a mix of synthetic and unlabeled real-world data achieved comparable or even better detection results at significantly lower cost. We argue that future research into the cost-efficiency of different training strategies is important for a better understanding of how to allocate budget in applied machine learning projects.
Create account to get full access
Overview
- The paper explores the use of synthetic data generation techniques to bridge the gap between simulated and real-world data for object detection and defect detection tasks.
- It investigates the impact of incorporating synthetic data into training object detectors and the cost-efficiency of this approach compared to traditional data collection methods.
- The research covers semi-supervised and unsupervised learning techniques to leverage unlabeled real-world data and further improve the performance of the object detectors.
Plain English Explanation
The paper focuses on a common problem in machine learning called the "sim-to-real gap." This refers to the challenge of training models using simulated or synthetic data, and then trying to apply them to the real world, where the data may look quite different.
The researchers explored ways to bridge this gap by using synthetic data generation techniques to create training data that is more similar to the real-world data the model will encounter. This can help improve object detector training and enable better classification of industrial parts.
They also looked at ways to leverage unlabeled real-world data through semi-supervised and unsupervised learning techniques. This can help further boost the performance of the object detectors without needing to collect and label lots of additional real-world data, which can be time-consuming and expensive.
Overall, the goal is to find cost-efficient ways to train highly accurate object detectors that can be deployed in real-world industrial and manufacturing settings.
Technical Explanation
The paper proposes a framework that combines synthetic data generation, semi-supervised learning, and unsupervised domain adaptation techniques to address the sim-to-real gap in object detection and defect detection tasks.
The researchers first generate synthetic training data using techniques like those explored in previous work. This synthetic data is then used alongside a small amount of labeled real-world data to train an initial object detector model.
To further improve the model's performance, the researchers leverage unlabeled real-world data through semi-supervised and unsupervised learning approaches. Semi-supervised learning techniques are used to refine the model's representations, while unsupervised domain adaptation methods are employed to bridge the domain gap between the synthetic and real-world data distributions.
Experiments on various object detection and defect detection benchmarks demonstrate the effectiveness of this approach, showing significant performance improvements over models trained on real-world data alone. The researchers also highlight the cost-efficiency of their framework compared to traditional data collection and annotation methods.
Critical Analysis
The paper presents a well-designed and thorough investigation of the potential for synthetic data generation and semi-supervised/unsupervised learning techniques to address the sim-to-real gap in object detection tasks. The researchers have carefully considered the limitations of their approach and acknowledge areas for future work.
One potential concern is the scalability of the semi-supervised and unsupervised learning components, as they may require significant computational resources and careful hyperparameter tuning to achieve optimal performance. Additionally, the researchers note that the effectiveness of their approach may be dependent on the specific characteristics of the target domain and the availability of suitable unlabeled real-world data.
It would be interesting to see further exploration of the impact of synthetic data on aerial view human detection or the use of generative AI techniques for sim-to-real data synthesis in future work. Broader evaluation across a wider range of object detection and defect detection tasks would also help to validate the generalizability of the proposed framework.
Conclusion
This paper presents a promising approach to bridging the sim-to-real gap in object detection and defect detection tasks. By combining synthetic data generation, semi-supervised learning, and unsupervised domain adaptation techniques, the researchers have demonstrated significant performance gains and cost-efficiency improvements over traditional data collection and annotation methods.
The work highlights the potential of leveraging both simulated and unlabeled real-world data to train highly accurate object detectors that can be deployed in industrial and manufacturing settings. As the need for cost-effective and scalable machine learning solutions continues to grow, this research offers valuable insights and a framework for addressing these challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Synthetic Data Generation for Bridging Sim2Real Gap in a Production Environment
Parth Rawal, Mrunal Sompura, Wolfgang Hintze
0
0
Synthetic data is being used lately for training deep neural networks in computer vision applications such as object detection, object segmentation and 6D object pose estimation. Domain randomization hereby plays an important role in reducing the simulation to reality gap. However, this generalization might not be effective in specialized domains like a production environment involving complex assemblies. Either the individual parts, trained with synthetic images, are integrated in much larger assemblies making them indistinguishable from their counterparts and result in false positives or are partially occluded just enough to give rise to false negatives. Domain knowledge is vital in these cases and if conceived effectively while generating synthetic data, can show a considerable improvement in bridging the simulation to reality gap. This paper focuses on synthetic data generation procedures for parts and assemblies used in a production environment. The basic procedures for synthetic data generation and their various combinations are evaluated and compared on images captured in a production environment, where results show up to 15% improvement using combinations of basic procedures. Reducing the simulation to reality gap in this way can aid to utilize the true potential of robot assisted production using artificial intelligence.
5/13/2024

Improving Object Detector Training on Synthetic Data by Starting With a Strong Baseline Methodology
Frank A. Ruis, Alma M. Liezenga, Friso G. Heslinga, Luca Ballan, Thijs A. Eker, Richard J. M. den Hollander, Martin C. van Leeuwen, Judith Dijk, Wyke Huizinga
0
0
Collecting and annotating real-world data for the development of object detection models is a time-consuming and expensive process. In the military domain in particular, data collection can also be dangerous or infeasible. Training models on synthetic data may provide a solution for cases where access to real-world training data is restricted. However, bridging the reality gap between synthetic and real data remains a challenge. Existing methods usually build on top of baseline Convolutional Neural Network (CNN) models that have been shown to perform well when trained on real data, but have limited ability to perform well when trained on synthetic data. For example, some architectures allow for fine-tuning with the expectation of large quantities of training data and are prone to overfitting on synthetic data. Related work usually ignores various best practices from object detection on real data, e.g. by training on synthetic data from a single environment with relatively little variation. In this paper we propose a methodology for improving the performance of a pre-trained object detector when training on synthetic data. Our approach focuses on extracting the salient information from synthetic data without forgetting useful features learned from pre-training on real images. Based on the state of the art, we incorporate data augmentation methods and a Transformer backbone. Besides reaching relatively strong performance without any specialized synthetic data transfer methods, we show that our methods improve the state of the art on synthetic data trained object detection for the RarePlanes and DGTA-VisDrone datasets, and reach near-perfect performance on an in-house vehicle detection dataset.
5/31/2024

Towards Sim-to-Real Industrial Parts Classification with Synthetic Dataset
Xiaomeng Zhu, Talha Bilal, Par M{aa}rtensson, Lars Hanson, M{aa}rten Bjorkman, Atsuto Maki
0
0
This paper is about effectively utilizing synthetic data for training deep neural networks for industrial parts classification, in particular, by taking into account the domain gap against real-world images. To this end, we introduce a synthetic dataset that may serve as a preliminary testbed for the Sim-to-Real challenge; it contains 17 objects of six industrial use cases, including isolated and assembled parts. A few subsets of objects exhibit large similarities in shape and albedo for reflecting challenging cases of industrial parts. All the sample images come with and without random backgrounds and post-processing for evaluating the importance of domain randomization. We call it Synthetic Industrial Parts dataset (SIP-17). We study the usefulness of SIP-17 through benchmarking the performance of five state-of-the-art deep network models, supervised and self-supervised, trained only on the synthetic data while testing them on real data. By analyzing the results, we deduce some insights on the feasibility and challenges of using synthetic data for industrial parts classification and for further developing larger-scale synthetic datasets. Our dataset and code are publicly available.
4/16/2024

Exploring the Impact of Synthetic Data for Aerial-view Human Detection
Hyungtae Lee, Yan Zhang, Yi-Ting Shen, Heesung Kwon, Shuvra S. Bhattacharyya
0
0
Aerial-view human detection has a large demand for large-scale data to capture more diverse human appearances compared to ground-view human detection. Therefore, synthetic data can be a good resource to expand data, but the domain gap with real-world data is the biggest obstacle to its use in training. As a common solution to deal with the domain gap, the sim2real transformation is used, and its quality is affected by three factors: i) the real data serving as a reference when calculating the domain gap, ii) the synthetic data chosen to avoid the transformation quality degradation, and iii) the synthetic data pool from which the synthetic data is selected. In this paper, we investigate the impact of these factors on maximizing the effectiveness of synthetic data in training in terms of improving learning performance and acquiring domain generalization ability--two main benefits expected of using synthetic data. As an evaluation metric for the second benefit, we introduce a method for measuring the distribution gap between two datasets, which is derived as the normalized sum of the Mahalanobis distances of all test data. As a result, we have discovered several important findings that have never been investigated or have been used previously without accurate understanding. We expect that these findings can break the current trend of either naively using or being hesitant to use synthetic data in machine learning due to the lack of understanding, leading to more appropriate use in future research.
5/28/2024