Quantifying and Enabling the Interpretability of CLIP-like Models

0

Sign in to get full access
Overview
- The paper "Quantifying and Enabling the Interpretability of CLIP-like Models" investigates ways to make CLIP-like language-image models more interpretable.
- CLIP is a powerful model that can perform a variety of vision-language tasks, but its inner workings are often opaque.
- The researchers propose methods to quantify and improve the interpretability of CLIP-like models.
Plain English Explanation
The paper focuses on CLIP-like models, which are artificial intelligence systems that can understand the relationship between images and the words that describe them. These models have shown impressive abilities, but it's often unclear how they arrive at their conclusions.
The researchers wanted to find ways to "open up the black box" and make these models more transparent. They developed techniques to measure how interpretable the models are, looking at factors like how well the model's internal features align with human-understandable concepts. The team also experimented with ways to redesign the models to increase their interpretability, such as by explicitly training them to learn more human-like representations.
The goal is to create AI systems that are not only powerful, but also easier for people to understand and trust. By making CLIP-like models more interpretable, the researchers hope to unlock new applications and facilitate the responsible development of this technology.
Technical Explanation
The paper introduces two main contributions:
-
Quantifying Interpretability: The researchers developed a suite of metrics to measure different aspects of a CLIP-like model's interpretability. This includes evaluating how well the model's internal features correspond to human-understandable concepts, and assessing how faithful the model's explanations are to its actual decision-making process.
-
Enabling Interpretability: Building on their interpretability measures, the team experimented with architectural modifications and training techniques to improve the inherent interpretability of CLIP-like models. For example, they explored explicitly encouraging the model to learn more human-aligned representations during training.
Through a series of experiments on the CLIP model and similar architectures, the paper demonstrates that these interpretability-focused techniques can provide meaningful insights into model behavior while also enhancing the model's transparency and interpretability.
Critical Analysis
The paper makes a valuable contribution by providing concrete methods to quantify and enhance the interpretability of powerful vision-language models like CLIP. However, the researchers acknowledge some limitations:
- The proposed interpretability metrics, while useful, may not capture all relevant aspects of model transparency. Additional work is needed to develop a more comprehensive evaluation framework.
- The architectural changes and training techniques explored in the paper, while effective, may not be the only or optimal ways to improve interpretability. Further research is needed to explore alternative approaches.
- The experiments in the paper were conducted on a limited set of datasets and model configurations. Broader testing is required to validate the generalizability of the findings.
Overall, this paper represents an important step forward in making complex AI systems more understandable and trustworthy. Continued research in this direction will be crucial as these models become more widely deployed in real-world applications.
Conclusion
The "Quantifying and Enabling the Interpretability of CLIP-like Models" paper introduces novel techniques to measure and enhance the interpretability of powerful vision-language models. By providing ways to "open the black box" and make these systems more transparent, the researchers aim to unlock new applications and support the responsible development of this influential AI technology. While further work is needed, this paper lays a solid foundation for improving the interpretability of CLIP-like models and advancing the field of explainable AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Quantifying and Enabling the Interpretability of CLIP-like Models
Avinash Madasu, Yossi Gandelsman, Vasudev Lal, Phillip Howard
CLIP is one of the most popular foundational models and is heavily used for many vision-language tasks. However, little is known about the inner workings of CLIP. To bridge this gap we propose a study to quantify the interpretability in CLIP like models. We conduct this study on six different CLIP models from OpenAI and OpenCLIP which vary by size, type of pre-training data and patch size. Our approach begins with using the TEXTSPAN algorithm and in-context learning to break down individual attention heads into specific properties. We then evaluate how easily these heads can be interpreted using new metrics which measure property consistency within heads and property disentanglement across heads. Our findings reveal that larger CLIP models are generally more interpretable than their smaller counterparts. To further assist users in understanding the inner workings of CLIP models, we introduce CLIP-InterpreT, a tool designed for interpretability analysis. CLIP-InterpreT offers five types of analyses: property-based nearest neighbor search, per-head topic segmentation, contrastive segmentation, per-head nearest neighbors of an image, and per-head nearest neighbors of text.
Read more9/11/2024
🔮
0
A Closer Look at the Explainability of Contrastive Language-Image Pre-training
Yi Li, Hualiang Wang, Yiqun Duan, Jiheng Zhang, Xiaomeng Li
Contrastive language-image pre-training (CLIP) is a powerful vision-language model that has shown great benefits for various tasks. However, we have identified some issues with its explainability, which undermine its credibility and limit the capacity for related tasks. Specifically, we find that CLIP tends to focus on background regions rather than foregrounds, with noisy activations at irrelevant positions on the visualization results. These phenomena conflict with conventional explainability methods based on the class attention map (CAM), where the raw model can highlight the local foreground regions using global supervision without alignment. To address these problems, we take a closer look at its architecture and features. Based on thorough analyses, we find the raw self-attentions link to inconsistent semantic regions, resulting in the opposite visualization. Besides, the noisy activations are owing to redundant features among categories. Building on these insights, we propose the CLIP Surgery for reliable CAM, a method that allows surgery-like modifications to the inference architecture and features, without further fine-tuning as classical CAM methods. This approach significantly improves the explainability of CLIP, surpassing existing methods by large margins. Besides, it enables multimodal visualization and extends the capacity of raw CLIP on open-vocabulary tasks without extra alignment. The code is available at https://github.com/xmed-lab/CLIP_Surgery.
Read more9/17/2024
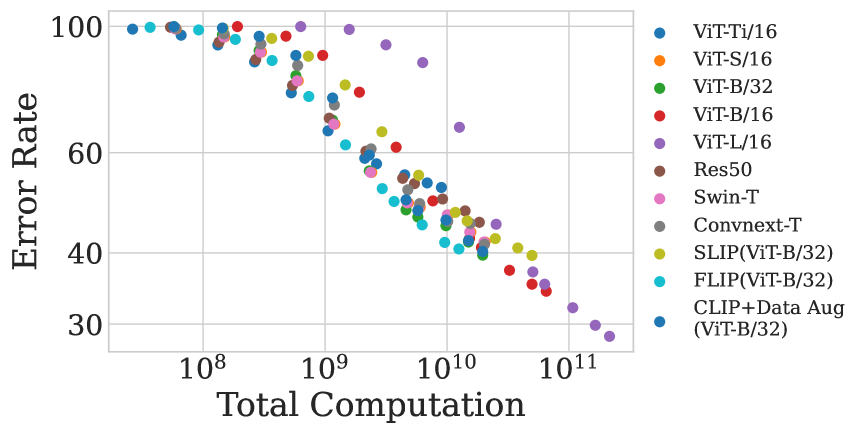
3
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
Zichao Li, Cihang Xie, Ekin Dogus Cubuk
This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute. Additionally, we provide guidance on when to choose a CNN-based architecture or a ViT-based architecture for CLIP training. We compare four CLIP training strategies - SLIP, FLIP, CLIP, and CLIP+Data Augmentation - and show that the choice of training strategy depends on the available compute resource. Our analysis reveals that CLIP+Data Augmentation can achieve comparable performance to CLIP using only half of the training data. This work provides practical insights into how to effectively train and deploy CLIP models, making them more accessible and affordable for practical use in various applications.
Read more4/17/2024
📊
3
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
Read more4/9/2024