Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
2404.08197
0
10
Abstract
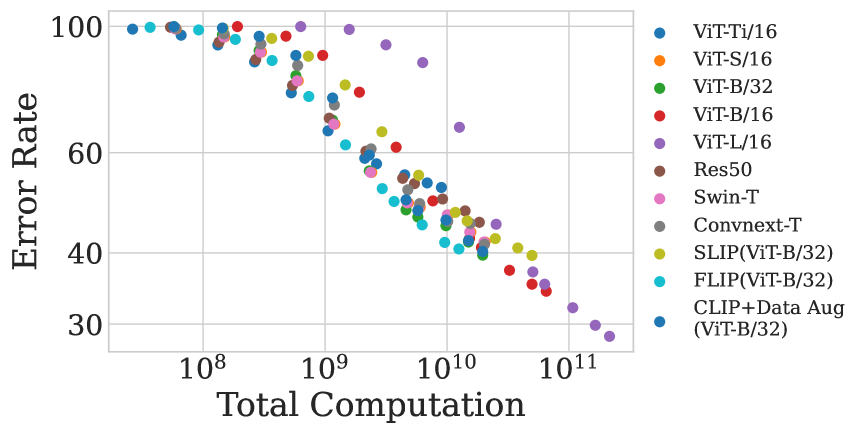
This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute. Additionally, we provide guidance on when to choose a CNN-based architecture or a ViT-based architecture for CLIP training. We compare four CLIP training strategies - SLIP, FLIP, CLIP, and CLIP+Data Augmentation - and show that the choice of training strategy depends on the available compute resource. Our analysis reveals that CLIP+Data Augmentation can achieve comparable performance to CLIP using only half of the training data. This work provides practical insights into how to effectively train and deploy CLIP models, making them more accessible and affordable for practical use in various applications.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a comprehensive analysis of the scaling and performance of the CLIP (Contrastive Language-Image Pre-training) model.
- The researchers investigate the impact of various data, architectural, and training strategies on the performance of downsized versions of CLIP.
- The goal is to understand how to effectively scale down CLIP to smaller models while maintaining strong performance across a range of tasks.
Plain English Explanation
The paper looks at the CLIP model, which is a powerful AI system that can understand and analyze images and text together. CLIP was originally developed as a large, complex model, but the researchers in this paper wanted to see if they could make it smaller and more efficient while still keeping its impressive capabilities.
They tried out different approaches, like using less training data, changing the model architecture, and adjusting the training process. The goal was to find the best way to scale down CLIP so that it could be used in a wider range of applications, even on devices with limited computing power.
The researchers ran a lot of experiments to test how these changes affected CLIP's performance on various tasks, like recognizing objects in images or understanding the meaning of text. They analyzed the results to figure out the sweet spot - the smallest version of CLIP that could still deliver strong, reliable performance.
Technical Explanation
The paper explores techniques for scaling down CLIP, a popular contrastive language-image pre-training model. The authors investigate the impact of data, architecture, and training strategies on the performance of downsized CLIP models.
Through extensive experiments, the researchers analyze how reducing the model size, training data, and other factors affects CLIP's performance across a range of tasks, including image classification, zero-shot transfer, and continuous sign language recognition. They also explore architectural modifications to the CLIP model, such as changing the vision and text encoder sizes.
The paper provides insights into the trade-offs between model size, training data, and performance. The researchers identify strategies that allow for significant reductions in model size with minimal impact on performance, paving the way for more efficient and widely deployable CLIP-based systems.
Critical Analysis
The paper presents a thorough and well-designed study on scaling down CLIP, exploring a range of factors that impact model performance. The researchers have done a commendable job in systematically analyzing the trade-offs and providing actionable insights.
However, the paper does not delve into the broader implications of these findings, such as how the scaled-down CLIP models might perform in real-world applications or the potential societal impacts of more widely deployable CLIP-based systems. Additionally, the paper does not address potential ethical concerns or biases that may arise from the use of these models.
Further research could explore the performance and robustness of the scaled-down CLIP models in more diverse and challenging scenarios, as well as investigate the potential ethical considerations and mitigation strategies.
Conclusion
This paper provides a comprehensive analysis of strategies for scaling down the CLIP model, a powerful contrastive language-image pre-training system. The researchers explore the impact of data, architecture, and training approaches on the performance of downsized CLIP models.
The key takeaway is that significant reductions in model size can be achieved with minimal impact on performance, paving the way for more efficient and widely deployable CLIP-based applications. These findings have important implications for the development of scalable and accessible AI models, which can benefit a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer
0
0
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
4/9/2024

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Among the ever-evolving development of vision-language models, contrastive language-image pretraining (CLIP) has set new benchmarks in many downstream tasks such as zero-shot classifications by leveraging self-supervised contrastive learning on large amounts of text-image pairs. However, its dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RankCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By leveraging both in-modal and cross-modal ranking consistency, RankCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the enhanced capability of RankCLIP to effectively improve performance across various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the potential of RankCLIP in further advancing vision-language pretraining.
4/16/2024
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024

New!CLIP with Quality Captions: A Strong Pretraining for Vision Tasks
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Oncel Tuzel
0
0
CLIP models perform remarkably well on zero-shot classification and retrieval tasks. But recent studies have shown that learnt representations in CLIP are not well suited for dense prediction tasks like object detection, semantic segmentation or depth estimation. More recently, multi-stage training methods for CLIP models was introduced to mitigate the weak performance of CLIP on downstream tasks. In this work, we find that simply improving the quality of captions in image-text datasets improves the quality of CLIP's visual representations, resulting in significant improvement on downstream dense prediction vision tasks. In fact, we find that CLIP pretraining with good quality captions can surpass recent supervised, self-supervised and weakly supervised pretraining methods. We show that when CLIP model with ViT-B/16 as image encoder is trained on well aligned image-text pairs it obtains 12.1% higher mIoU and 11.5% lower RMSE on semantic segmentation and depth estimation tasks over recent state-of-the-art Masked Image Modeling (MIM) pretraining methods like Masked Autoencoder (MAE). We find that mobile architectures also benefit significantly from CLIP pretraining. A recent mobile vision architecture, MCi2, with CLIP pretraining obtains similar performance as Swin-L, pretrained on ImageNet-22k for semantic segmentation task while being 6.1$times$ smaller. Moreover, we show that improving caption quality results in $10times$ data efficiency when finetuning for dense prediction tasks.
5/16/2024