Quantifying the Role of Textual Predictability in Automatic Speech Recognition

0
Sign in to get full access
Overview
- The paper investigates the role of textual predictability in automatic speech recognition (ASR) systems.
- It explores how language models can be used to improve ASR performance by leveraging the predictability of text.
- The researchers conducted experiments to quantify the impact of textual predictability on ASR accuracy.
Plain English Explanation
The paper looks at how the <a href="https://aimodels.fyi/papers/arxiv/improving-neural-biasing-contextual-speech-recognition-by">predictability of text</a> can be used to improve the accuracy of <a href="https://aimodels.fyi/papers/arxiv/phonetic-enhanced-language-modeling-text-to-speech">automatic speech recognition (ASR)</a> systems. ASR systems convert spoken audio into text, but they can make mistakes, especially when the audio is noisy or the speaker is unclear.
The researchers hypothesized that by using <a href="https://aimodels.fyi/papers/arxiv/efficient-text-augmentation-approach-contextualized-mandarin-speech">language models</a> to predict what words are likely to come next in a sentence, the ASR system could make more accurate guesses about the spoken text. They conducted experiments to <a href="https://aimodels.fyi/papers/arxiv/keyword-guided-adaptation-automatic-speech-recognition">quantify how much this textual predictability improves ASR performance</a>.
The key idea is that if an ASR system knows that certain words are more likely to appear in a given context, it can use that information to choose the right words when transcribing the audio. For example, if the system hears "the _____" it can guess that a noun is likely to come next, and use that to improve its transcription accuracy.
Technical Explanation
The paper examines how <a href="https://aimodels.fyi/papers/arxiv/conversational-speech-recognition-by-learning-audio-textual">language models can be integrated with ASR systems</a> to leverage the predictability of text. The researchers conducted experiments on several benchmark ASR datasets, including Switchboard and LibriSpeech.
They used language models to compute the <em>perplexity</em> of each word in the reference transcripts, which measures how predictable that word is given the preceding context. They then analyzed the relationship between word perplexity and the ASR system's word error rate (WER) - a metric of transcription accuracy.
The results showed a strong correlation between lower word perplexity (higher predictability) and lower WER. This demonstrates that ASR systems can indeed benefit from modeling the predictability of text, and that language models can play a valuable role in improving ASR performance.
Critical Analysis
The paper provides a thorough and rigorous analysis of the role of textual predictability in ASR. The experimental design is sound, and the findings are well-supported by the data.
However, the paper does not explore the limitations of this approach. For example, it's unclear how the benefits of leveraging textual predictability would scale to more diverse or spontaneous speech, where the language may be less predictable. Additionally, the paper does not discuss potential biases that could arise from over-relying on language model predictions.
Further research could examine these edge cases and investigate ways to robustly integrate language models into ASR while mitigating potential drawbacks. Exploring the tradeoffs between textual predictability and other factors like acoustic reliability would also be a valuable direction for future work.
Conclusion
This paper makes a compelling case for the importance of textual predictability in improving the accuracy of automatic speech recognition systems. By using language models to leverage the inherent structure and patterns in language, ASR systems can make more informed decisions when transcribing audio, leading to significant gains in performance.
The findings have important implications for the development of more robust and reliable ASR technologies, which are crucial for a wide range of applications, from voice assistants to medical transcription. As the field of speech recognition continues to advance, the insights provided by this research will help guide future innovations in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Quantifying the Role of Textual Predictability in Automatic Speech Recognition
Sean Robertson, Gerald Penn, Ewan Dunbar
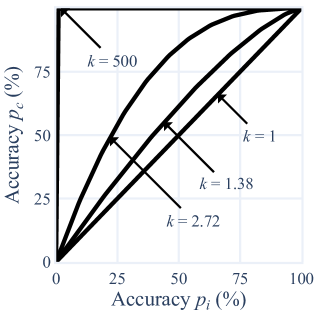
A long-standing question in automatic speech recognition research is how to attribute errors to the ability of a model to model the acoustics, versus its ability to leverage higher-order context (lexicon, morphology, syntax, semantics). We validate a novel approach which models error rates as a function of relative textual predictability, and yields a single number, $k$, which measures the effect of textual predictability on the recognizer. We use this method to demonstrate that a Wav2Vec 2.0-based model makes greater stronger use of textual context than a hybrid ASR model, in spite of not using an explicit language model, and also use it to shed light on recent results demonstrating poor performance of standard ASR systems on African-American English. We demonstrate that these mostly represent failures of acoustic--phonetic modelling. We show how this approach can be used straightforwardly in diagnosing and improving ASR.
Read more7/24/2024

0
Improving Speech Recognition Error Prediction for Modern and Off-the-shelf Speech Recognizers
Prashant Serai, Peidong Wang, Eric Fosler-Lussier
Modeling the errors of a speech recognizer can help simulate errorful recognized speech data from plain text, which has proven useful for tasks like discriminative language modeling, improving robustness of NLP systems, where limited or even no audio data is available at train time. Previous work typically considered replicating behavior of GMM-HMM based systems, but the behavior of more modern posterior-based neural network acoustic models is not the same and requires adjustments to the error prediction model. In this work, we extend a prior phonetic confusion based model for predicting speech recognition errors in two ways: first, we introduce a sampling-based paradigm that better simulates the behavior of a posterior-based acoustic model. Second, we investigate replacing the confusion matrix with a sequence-to-sequence model in order to introduce context dependency into the prediction. We evaluate the error predictors in two ways: first by predicting the errors made by a Switchboard ASR system on unseen data (Fisher), and then using that same predictor to estimate the behavior of an unrelated cloud-based ASR system on a novel task. Sampling greatly improves predictive accuracy within a 100-guess paradigm, while the sequence model performs similarly to the confusion matrix.
Read more8/22/2024

0
Improving Neural Biasing for Contextual Speech Recognition by Early Context Injection and Text Perturbation
Ruizhe Huang, Mahsa Yarmohammadi, Sanjeev Khudanpur, Daniel Povey
Existing research suggests that automatic speech recognition (ASR) models can benefit from additional contexts (e.g., contact lists, user specified vocabulary). Rare words and named entities can be better recognized with contexts. In this work, we propose two simple yet effective techniques to improve context-aware ASR models. First, we inject contexts into the encoders at an early stage instead of merely at their last layers. Second, to enforce the model to leverage the contexts during training, we perturb the reference transcription with alternative spellings so that the model learns to rely on the contexts to make correct predictions. On LibriSpeech, our techniques together reduce the rare word error rate by 60% and 25% relatively compared to no biasing and shallow fusion, making the new state-of-the-art performance. On SPGISpeech and a real-world dataset ConEC, our techniques also yield good improvements over the baselines.
Read more7/16/2024
0
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Read more6/13/2024