Improving Speech Recognition Error Prediction for Modern and Off-the-shelf Speech Recognizers

0

Sign in to get full access
Overview
- This research paper focuses on improving the prediction of speech recognition errors
- The authors propose new models and techniques to better identify potential errors in speech recognition systems
- The goal is to enhance the performance and reliability of modern and off-the-shelf speech recognizers
Plain English Explanation
The paper addresses an important challenge in speech recognition technology - accurately predicting when a speech recognizer is likely to make a mistake. Accurate error prediction can help speech recognition systems correct or avoid errors, improving overall performance.
The authors develop new models and techniques to enhance the ability to forecast speech recognition errors. This includes phonetic-enhanced language modeling and a post-editing approach to identify and correct errors. The goal is to make speech recognition more reliable and useful, especially for modern and off-the-shelf systems that may not have advanced error-handling capabilities.
Technical Explanation
The paper introduces several novel models and techniques for improving speech recognition error prediction:
-
Phonetic-Enhanced Language Model: This model incorporates phonetic information to better capture pronunciation patterns and improve the ability to detect potential recognition errors.
-
Post-Editing Approach: The authors propose a high-precision post-editing approach that identifies and corrects errors after the initial speech recognition step. This helps recover from errors that the initial recognition system may have missed.
-
Multi-Task Learning: The model is trained using a multi-task learning approach that jointly optimizes for accurate speech recognition and error prediction. This allows the model to learn representations that are useful for both tasks.
-
Attention-Based Architectures: The paper explores the use of attention-based neural network architectures, which can better capture the contextual information relevant to error prediction.
The authors evaluate these techniques on both modern and off-the-shelf speech recognition systems, demonstrating significant improvements in error prediction accuracy compared to baseline approaches.
Critical Analysis
The research presented in this paper is well-designed and makes a valuable contribution to the field of speech recognition. However, the authors acknowledge some limitations:
- The evaluation is primarily conducted on English language data, so the generalization to other languages may require further investigation.
- The performance of the error prediction models may be influenced by the specific characteristics of the speech recognition systems used, and their applicability to other systems is not fully explored.
- The paper does not provide a detailed analysis of the computational efficiency and real-time performance of the proposed techniques, which could be important for practical deployment in production systems.
Additionally, it would be interesting to see how these error prediction models could be further integrated into the speech recognition pipeline to enable more robust and adaptive systems that can proactively handle and correct errors.
Conclusion
This research paper presents a significant advancement in the field of speech recognition error prediction. The authors have developed novel models and techniques that demonstrate substantial improvements in the ability to forecast and mitigate speech recognition errors. These findings have the potential to enhance the reliability and performance of modern and off-the-shelf speech recognition systems, ultimately leading to more accurate and user-friendly voice interfaces.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Speech Recognition Error Prediction for Modern and Off-the-shelf Speech Recognizers
Prashant Serai, Peidong Wang, Eric Fosler-Lussier
Modeling the errors of a speech recognizer can help simulate errorful recognized speech data from plain text, which has proven useful for tasks like discriminative language modeling, improving robustness of NLP systems, where limited or even no audio data is available at train time. Previous work typically considered replicating behavior of GMM-HMM based systems, but the behavior of more modern posterior-based neural network acoustic models is not the same and requires adjustments to the error prediction model. In this work, we extend a prior phonetic confusion based model for predicting speech recognition errors in two ways: first, we introduce a sampling-based paradigm that better simulates the behavior of a posterior-based acoustic model. Second, we investigate replacing the confusion matrix with a sequence-to-sequence model in order to introduce context dependency into the prediction. We evaluate the error predictors in two ways: first by predicting the errors made by a Switchboard ASR system on unseen data (Fisher), and then using that same predictor to estimate the behavior of an unrelated cloud-based ASR system on a novel task. Sampling greatly improves predictive accuracy within a 100-guess paradigm, while the sequence model performs similarly to the confusion matrix.
Read more8/22/2024
🗣️
0
Tag and correct: high precision post-editing approach to correction of speech recognition errors
Tomasz Zik{e}tkiewicz
This paper presents a new approach to the problem of correcting speech recognition errors by means of post-editing. It consists of using a neural sequence tagger that learns how to correct an ASR (Automatic Speech Recognition) hypothesis word by word and a corrector module that applies corrections returned by the tagger. The proposed solution is applicable to any ASR system, regardless of its architecture, and provides high-precision control over errors being corrected. This is especially crucial in production environments, where avoiding the introduction of new mistakes by the error correction model may be more important than the net gain in overall results. The results show that the performance of the proposed error correction models is comparable with previous approaches while requiring much smaller resources to train, which makes it suitable for industrial applications, where both inference latency and training times are critical factors that limit the use of other techniques.
Read more6/13/2024
0
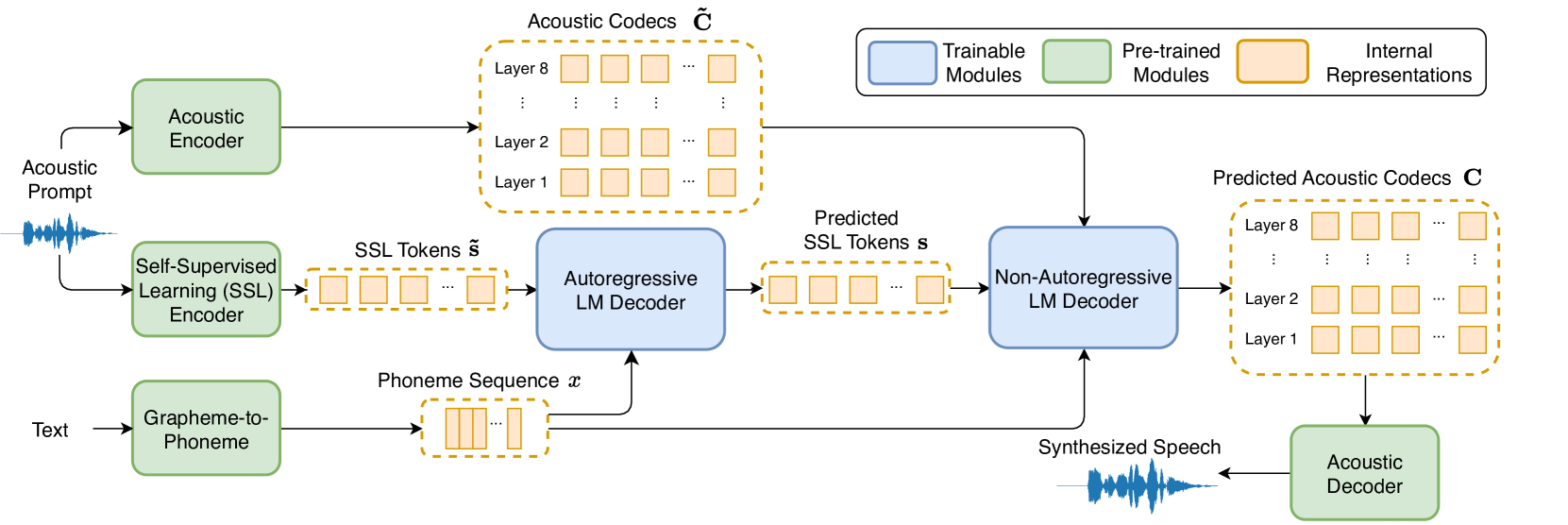
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Read more6/13/2024
0
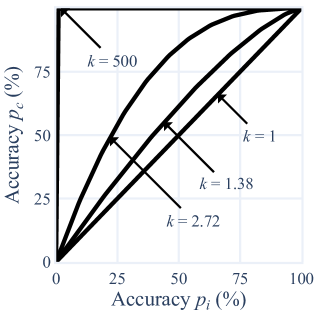
Quantifying the Role of Textual Predictability in Automatic Speech Recognition
Sean Robertson, Gerald Penn, Ewan Dunbar
A long-standing question in automatic speech recognition research is how to attribute errors to the ability of a model to model the acoustics, versus its ability to leverage higher-order context (lexicon, morphology, syntax, semantics). We validate a novel approach which models error rates as a function of relative textual predictability, and yields a single number, $k$, which measures the effect of textual predictability on the recognizer. We use this method to demonstrate that a Wav2Vec 2.0-based model makes greater stronger use of textual context than a hybrid ASR model, in spite of not using an explicit language model, and also use it to shed light on recent results demonstrating poor performance of standard ASR systems on African-American English. We demonstrate that these mostly represent failures of acoustic--phonetic modelling. We show how this approach can be used straightforwardly in diagnosing and improving ASR.
Read more7/24/2024