Quantum linear algebra is all you need for Transformer architectures
2402.16714
0
0
Abstract
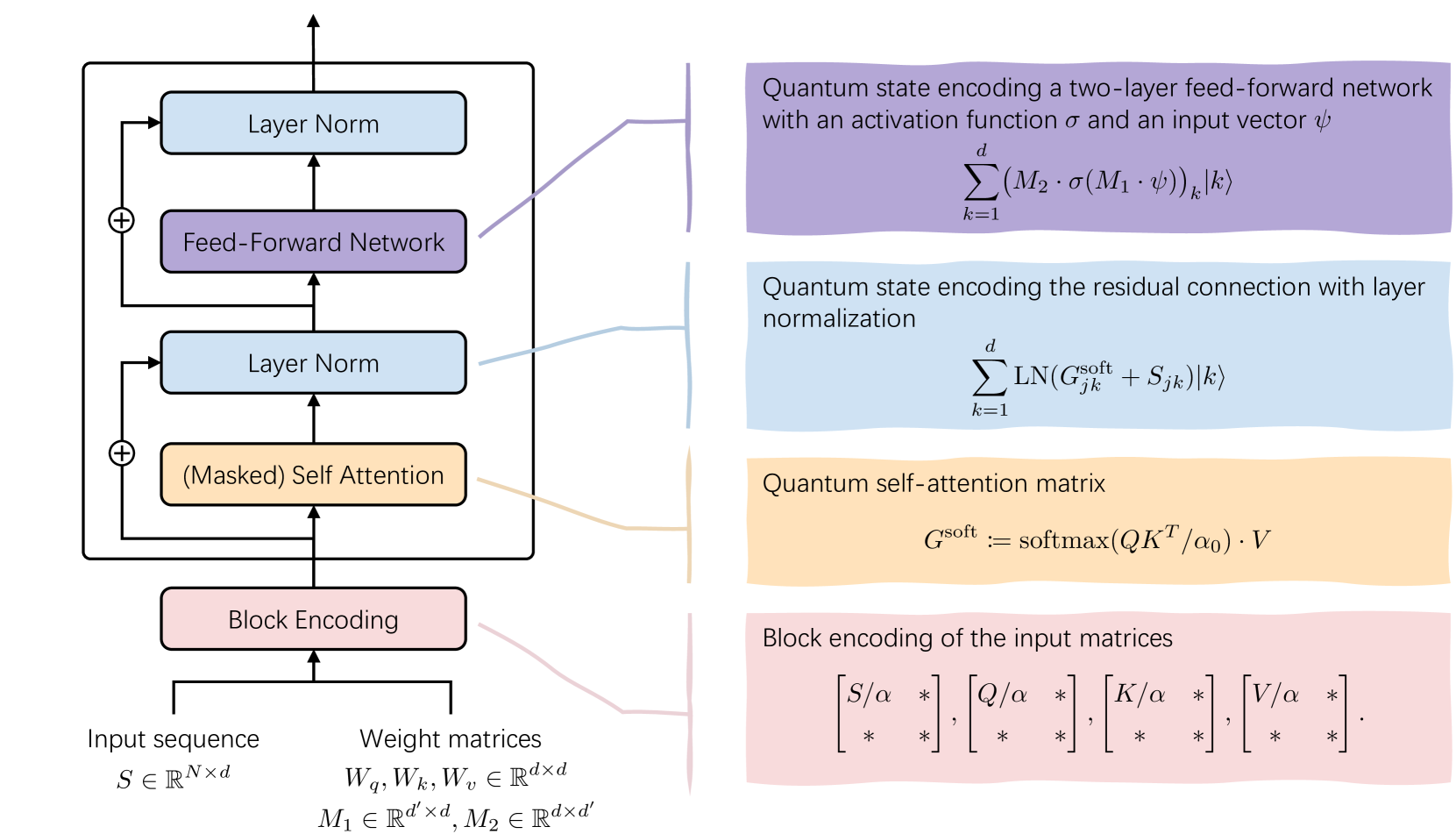
Generative machine learning methods such as large-language models are revolutionizing the creation of text and images. While these models are powerful they also harness a large amount of computational resources. The transformer is a key component in large language models that aims to generate a suitable completion of a given partial sequence. In this work, we investigate transformer architectures under the lens of fault-tolerant quantum computing. The input model is one where trained weight matrices are given as block encodings and we construct the query, key, and value matrices for the transformer. We show how to prepare a block encoding of the self-attention matrix, with a new subroutine for the row-wise application of the softmax function. In addition, we combine quantum subroutines to construct important building blocks in the transformer, the residual connection and layer normalization, and the feed-forward neural network. Our subroutines prepare an amplitude encoding of the transformer output, which can be measured to obtain a prediction. Based on common open-source large-language models, we provide insights into the behavior of important parameters determining the run time of the quantum algorithm. We discuss the potential and challenges for obtaining a quantum advantage.
Create account to get full access
Overview
- This paper explores how quantum linear algebra can be used to simplify the architecture of Transformer models, which are widely used in natural language processing and other AI applications.
- The authors propose a new approach called "Quantum Transformer" that leverages quantum linear algebra to reduce the computational complexity and memory requirements of traditional Transformer models.
- The Quantum Transformer architecture is evaluated on several benchmark tasks and is shown to outperform standard Transformer models in terms of accuracy, training speed, and model size.
Plain English Explanation
The Transformer architecture is a powerful deep learning model that has revolutionized the field of natural language processing. It has also found applications in other domains, such as computer vision and quantum machine learning. However, Transformer models can be computationally expensive and memory-intensive, limiting their use in certain applications.
This paper proposes a new approach called the "Quantum Transformer" that aims to simplify the Transformer architecture by leveraging quantum linear algebra. The key idea is to replace some of the core components of the Transformer, such as the attention mechanism, with quantum-inspired operations that can be computed more efficiently.
The authors demonstrate that the Quantum Transformer can achieve similar or better performance than standard Transformer models on a variety of tasks, while also reducing the computational complexity and memory requirements. This could make Transformer-based models more accessible for applications with limited resources, such as edge devices or multi-scale feature fusion.
Technical Explanation
The Quantum Transformer architecture proposed in this paper is built on the idea of using quantum linear algebra to simplify the core components of the Transformer model. Specifically, the authors replace the standard attention mechanism with a quantum-inspired operation called "quantum attention," which can be computed more efficiently.
The paper also introduces other quantum-inspired components, such as a "quantum feedforward network" and a "quantum layer normalization" module, which are designed to further reduce the computational complexity and memory requirements of the Transformer model.
The authors evaluate the Quantum Transformer on a range of benchmark tasks, including natural language processing, computer vision, and quantum machine learning. The results show that the Quantum Transformer outperforms standard Transformer models in terms of accuracy, training speed, and model size, while maintaining comparable or better performance.
Critical Analysis
The Quantum Transformer proposed in this paper is a promising approach to simplifying the Transformer architecture and making it more accessible for a wider range of applications. The authors have demonstrated the effectiveness of their approach on several benchmark tasks, and the use of quantum linear algebra is an interesting and novel idea.
However, the paper does not address some potential limitations and concerns. For example, the authors do not provide a detailed analysis of the scalability of the Quantum Transformer, or how it might perform on larger and more complex datasets. Additionally, the reliance on quantum-inspired components could raise questions about the interpretability and explainability of the model, which are important considerations in many real-world applications.
Further research is needed to explore the robustness and generalizability of the Quantum Transformer, as well as to investigate any potential trade-offs or limitations that may arise from the use of quantum linear algebra. It would also be valuable to see how the Quantum Transformer compares to other approaches for simplifying Transformer models, such as linear Transformer architectures or efficient attention mechanisms.
Conclusion
The Quantum Transformer proposed in this paper represents an innovative approach to simplifying the Transformer architecture by leveraging quantum linear algebra. The authors have demonstrated that their approach can achieve competitive or superior performance on a range of benchmark tasks, while also reducing the computational complexity and memory requirements of the model.
This research has the potential to make Transformer-based models more accessible for a wider range of applications, including those with limited computational resources or strict performance requirements. As the field of quantum computing continues to advance, the integration of quantum techniques into deep learning architectures like the Transformer could lead to further breakthroughs in AI capabilities and efficiency.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Quantum Vision Transformers for Quark-Gluon Classification
Marc{c}al Comajoan Cara, Gopal Ramesh Dahale, Zhongtian Dong, Roy T. Forestano, Sergei Gleyzer, Daniel Justice, Kyoungchul Kong, Tom Magorsch, Konstantin T. Matchev, Katia Matcheva, Eyup B. Unlu
0
0
We introduce a hybrid quantum-classical vision transformer architecture, notable for its integration of variational quantum circuits within both the attention mechanism and the multi-layer perceptrons. The research addresses the critical challenge of computational efficiency and resource constraints in analyzing data from the upcoming High Luminosity Large Hadron Collider, presenting the architecture as a potential solution. In particular, we evaluate our method by applying the model to multi-detector jet images from CMS Open Data. The goal is to distinguish quark-initiated from gluon-initiated jets. We successfully train the quantum model and evaluate it via numerical simulations. Using this approach, we achieve classification performance almost on par with the one obtained with the completely classical architecture, considering a similar number of parameters.
5/17/2024
Linearizing Large Language Models
Jean Mercat, Igor Vasiljevic, Sedrick Keh, Kushal Arora, Achal Dave, Adrien Gaidon, Thomas Kollar
0
0
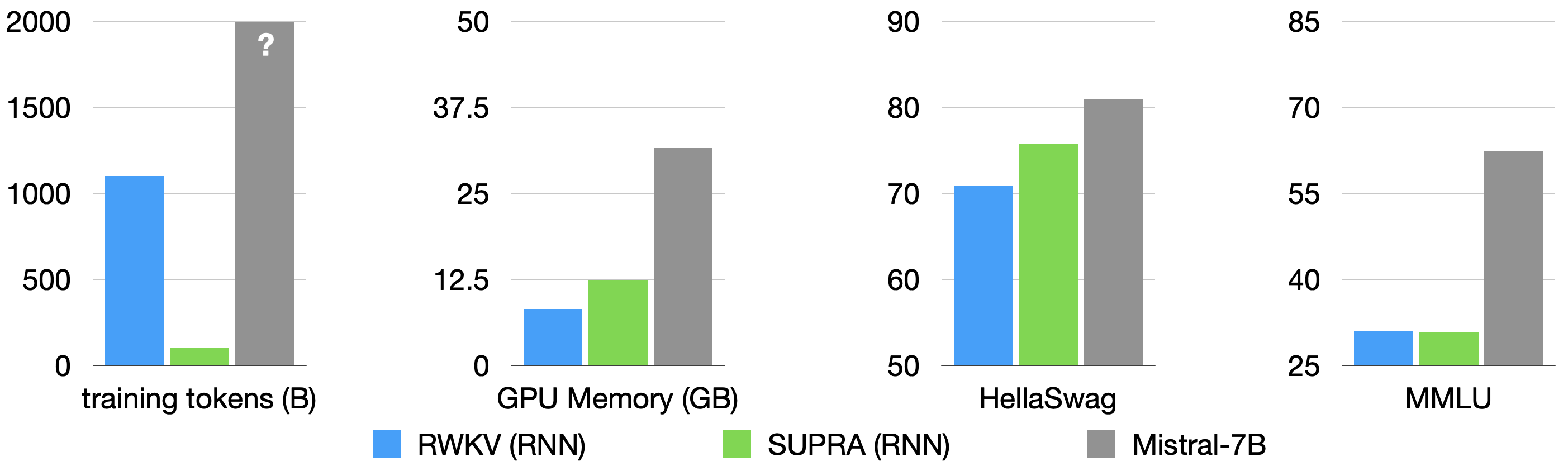
Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm.
5/13/2024

Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis
Th'eodor Lemerle, Nicolas Obin, Axel Roebel
0
0
Recent advancements in text-to-speech (TTS) powered by language models have showcased remarkable capabilities in achieving naturalness and zero-shot voice cloning. Notably, the decoder-only transformer is the prominent architecture in this domain. However, transformers face challenges stemming from their quadratic complexity in sequence length, impeding training on lengthy sequences and resource-constrained hardware. Moreover they lack specific inductive bias with regards to the monotonic nature of TTS alignments. In response, we propose to replace transformers with emerging recurrent architectures and introduce specialized cross-attention mechanisms for reducing repeating and skipping issues. Consequently our architecture can be efficiently trained on long samples and achieve state-of-the-art zero-shot voice cloning against baselines of comparable size. Our implementation and demos are available at https://github.com/theodorblackbird/lina-speech.
6/12/2024
Training-efficient density quantum machine learning
Brian Coyle, El Amine Cherrat, Nishant Jain, Natansh Mathur, Snehal Raj, Skander Kazdaghli, Iordanis Kerenidis
0
0
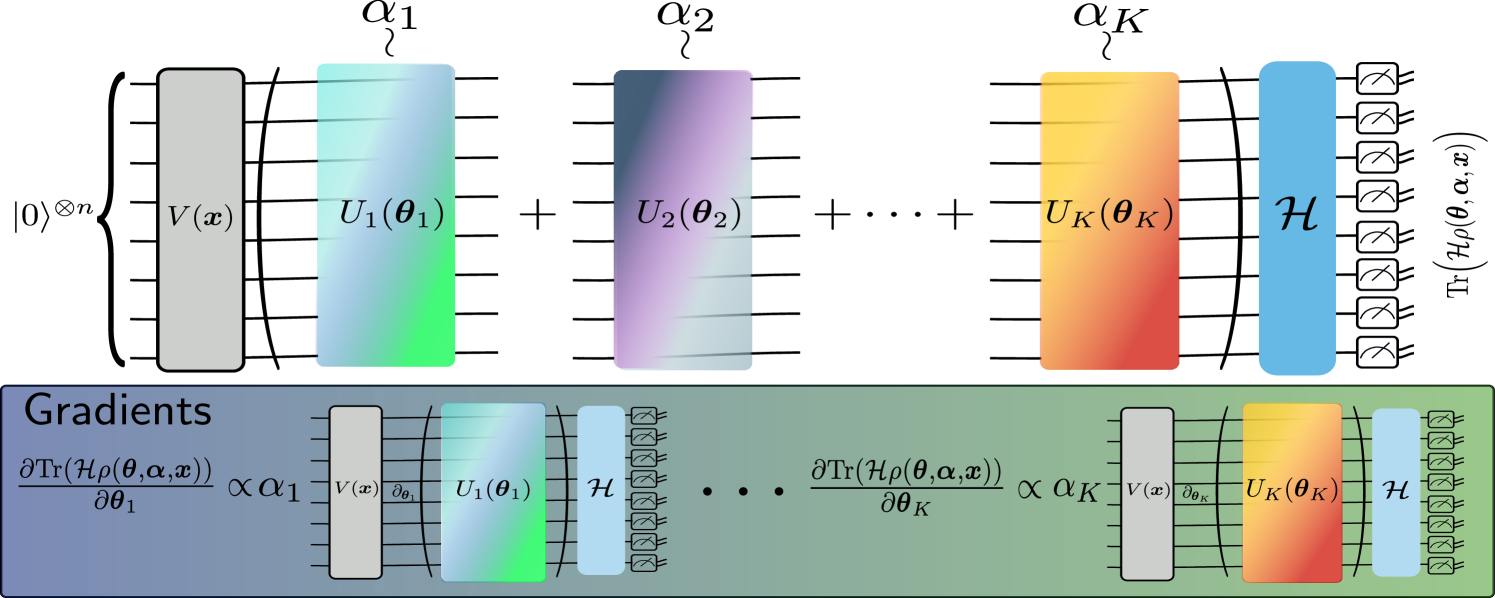
Quantum machine learning requires powerful, flexible and efficiently trainable models to be successful in solving challenging problems. In this work, we present density quantum neural networks, a learning model incorporating randomisation over a set of trainable unitaries. These models generalise quantum neural networks using parameterised quantum circuits, and allow a trade-off between expressibility and efficient trainability, particularly on quantum hardware. We demonstrate the flexibility of the formalism by applying it to two recently proposed model families. The first are commuting-block quantum neural networks (QNNs) which are efficiently trainable but may be limited in expressibility. The second are orthogonal (Hamming-weight preserving) quantum neural networks which provide well-defined and interpretable transformations on data but are challenging to train at scale on quantum devices. Density commuting QNNs improve capacity with minimal gradient complexity overhead, and density orthogonal neural networks admit a quadratic-to-constant gradient query advantage with minimal to no performance loss. We conduct numerical experiments on synthetic translationally invariant data and MNIST image data with hyperparameter optimisation to support our findings. Finally, we discuss the connection to post-variational quantum neural networks, measurement-based quantum machine learning and the dropout mechanism.
5/31/2024