The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability

0
Sign in to get full access
Overview
- Provides a historical perspective on the quest for causal interpretability in machine learning
- Surveys various methods and approaches to achieving causal interpretability
- Offers a theoretical grounding for causal interpretability, connecting it to fundamental concepts in causality and interpretability
Plain English Explanation
The paper explores the challenge of making machine learning models more interpretable by uncovering the causal relationships that underlie the models' predictions. This is an important goal, as it can help us better understand how these models arrive at their outputs and ensure they are behaving as intended.
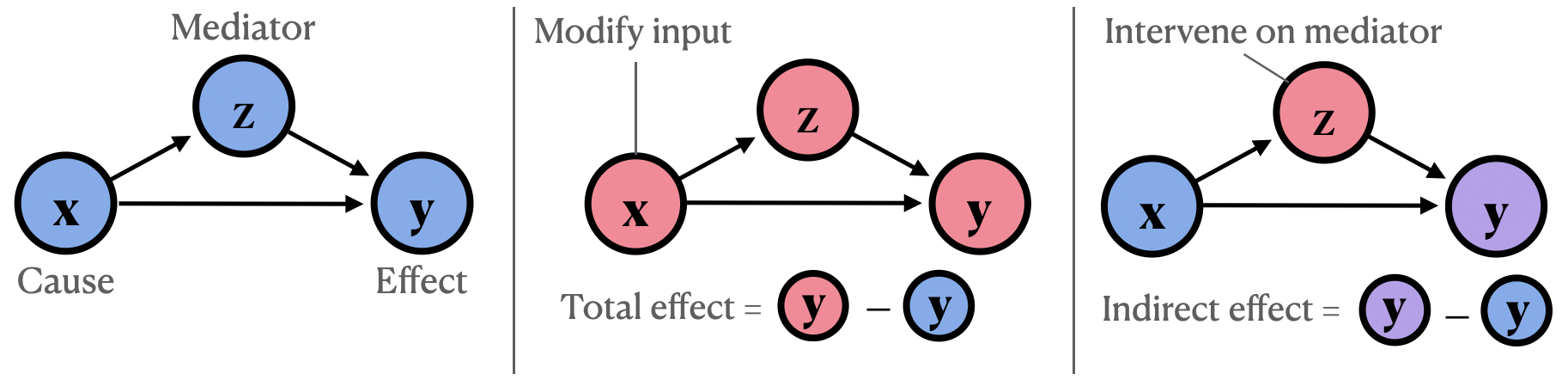
The authors trace the historical development of causal interpretability, examining how researchers have sought to identify the key factors or "mediators" that drive a model's predictions. They survey a range of techniques, from graphical causal models to counterfactual reasoning, that aim to uncover these causal mechanisms.
Importantly, the paper also provides a theoretical foundation for causal interpretability, connecting it to fundamental ideas in causality and interpretability. This helps solidify the conceptual basis for this line of research and offers a framework for evaluating and comparing different approaches.
Technical Explanation
The paper begins by outlining the historical context for the quest to achieve causal interpretability in machine learning. It discusses how earlier work on interpretability and causal modeling has laid the groundwork for this line of inquiry.
The authors then survey a range of techniques that have been proposed for uncovering causal relationships in machine learning models. These include graphical causal models, counterfactual reasoning, and other approaches that aim to identify the key "mediating" factors that drive a model's predictions.
Importantly, the paper also provides a theoretical grounding for causal interpretability, connecting it to fundamental concepts in causality and interpretability. This includes a discussion of the underlying principles that define what it means for a machine learning model to be "causally interpretable."
Critical Analysis
The paper presents a comprehensive overview of the quest for causal interpretability in machine learning, covering both historical and theoretical perspectives. However, it also acknowledges some of the key challenges and limitations of this line of research.
For example, the authors note that the identification of causal mediators can be a complex and context-dependent task, with no single "right" solution. They also highlight the potential for causal interpretability techniques to be vulnerable to biases or confounding factors, which could undermine their reliability.
Additionally, the paper suggests that further research is needed to better understand the relationship between causal interpretability and other desirable properties of machine learning models, such as robustness and fairness.
Conclusion
This paper offers a valuable contribution to the ongoing effort to make machine learning more interpretable and transparent. By tracing the historical development of causal interpretability and providing a theoretical grounding for this concept, the authors have laid the foundation for continued progress in this important area of research.
As machine learning models become increasingly influential in critical domains, the ability to understand and trust their decision-making processes will only become more crucial. The insights and frameworks presented in this paper can help guide researchers and practitioners as they work to unlock the causal mechanisms underlying these models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability
Aaron Mueller, Jannik Brinkmann, Millicent Li, Samuel Marks, Koyena Pal, Nikhil Prakash, Can Rager, Aruna Sankaranarayanan, Arnab Sen Sharma, Jiuding Sun, Eric Todd, David Bau, Yonatan Belinkov
Interpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not share theoretical foundations, making it difficult to measure progress and compare the pros and cons of different techniques. Furthermore, while mechanistic understanding is frequently discussed, the basic causal units underlying these mechanisms are often not explicitly defined. In this paper, we propose a perspective on interpretability research grounded in causal mediation analysis. Specifically, we describe the history and current state of interpretability taxonomized according to the types of causal units (mediators) employed, as well as methods used to search over mediators. We discuss the pros and cons of each mediator, providing insights as to when particular kinds of mediators and search methods are most appropriate depending on the goals of a given study. We argue that this framing yields a more cohesive narrative of the field, as well as actionable insights for future work. Specifically, we recommend a focus on discovering new mediators with better trade-offs between human-interpretability and compute-efficiency, and which can uncover more sophisticated abstractions from neural networks than the primarily linear mediators employed in current work. We also argue for more standardized evaluations that enable principled comparisons across mediator types, such that we can better understand when particular causal units are better suited to particular use cases.
Read more8/6/2024
🧪
0
Towards a Unified Framework for Evaluating Explanations
Juan D. Pinto, Luc Paquette
The challenge of creating interpretable models has been taken up by two main research communities: ML researchers primarily focused on lower-level explainability methods that suit the needs of engineers, and HCI researchers who have more heavily emphasized user-centered approaches often based on participatory design methods. This paper reviews how these communities have evaluated interpretability, identifying overlaps and semantic misalignments. We propose moving towards a unified framework of evaluation criteria and lay the groundwork for such a framework by articulating the relationships between existing criteria. We argue that explanations serve as mediators between models and stakeholders, whether for intrinsically interpretable models or opaque black-box models analyzed via post-hoc techniques. We further argue that useful explanations require both faithfulness and intelligibility. Explanation plausibility is a prerequisite for intelligibility, while stability is a prerequisite for explanation faithfulness. We illustrate these criteria, as well as specific evaluation methods, using examples from an ongoing study of an interpretable neural network for predicting a particular learner behavior.
Read more7/16/2024
💬
0
Causal Abstraction: A Theoretical Foundation for Mechanistic Interpretability
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, Thomas Icard
Causal abstraction provides a theoretical foundation for mechanistic interpretability, the field concerned with providing intelligible algorithms that are faithful simplifications of the known, but opaque low-level details of black box AI models. Our contributions are (1) generalizing the theory of causal abstraction from mechanism replacement (i.e., hard and soft interventions) to arbitrary mechanism transformation (i.e., functionals from old mechanisms to new mechanisms), (2) providing a flexible, yet precise formalization for the core concepts of modular features, polysemantic neurons, and graded faithfulness, and (3) unifying a variety of mechanistic interpretability methodologies in the common language of causal abstraction, namely activation and path patching, causal mediation analysis, causal scrubbing, causal tracing, circuit analysis, concept erasure, sparse autoencoders, differential binary masking, distributed alignment search, and activation steering.
Read more7/9/2024

0
From Neurons to Neutrons: A Case Study in Interpretability
Ouail Kitouni, Niklas Nolte, V'ictor Samuel P'erez-D'iaz, Sokratis Trifinopoulos, Mike Williams
Mechanistic Interpretability (MI) promises a path toward fully understanding how neural networks make their predictions. Prior work demonstrates that even when trained to perform simple arithmetic, models can implement a variety of algorithms (sometimes concurrently) depending on initialization and hyperparameters. Does this mean neuron-level interpretability techniques have limited applicability? We argue that high-dimensional neural networks can learn low-dimensional representations of their training data that are useful beyond simply making good predictions. Such representations can be understood through the mechanistic interpretability lens and provide insights that are surprisingly faithful to human-derived domain knowledge. This indicates that such approaches to interpretability can be useful for deriving a new understanding of a problem from models trained to solve it. As a case study, we extract nuclear physics concepts by studying models trained to reproduce nuclear data.
Read more5/28/2024