Question Difficulty Ranking for Multiple-Choice Reading Comprehension

0

Sign in to get full access
Overview
- This paper proposes a method for ranking the difficulty of multiple-choice questions in reading comprehension tasks.
- The researchers developed a model that can automatically assess the difficulty level of reading comprehension questions, which can help improve the creation and evaluation of such tests.
- The paper explores various factors that contribute to question difficulty, such as linguistic complexity, reasoning required, and the relative similarity of answer choices.
Plain English Explanation
Creating good multiple-choice reading comprehension questions is a challenging task. The questions need to be well-designed to accurately assess a reader's understanding, with the right balance of difficulty. This paper introduces a model that can automatically evaluate the difficulty level of reading comprehension questions.
The researchers looked at different factors that influence how hard a question is, such as:
- The complexity of the language used in the question and answer choices
- The level of reasoning or inference the reader needs to make to answer correctly
- How similar the incorrect answer choices are to the right answer
By considering these elements, the model can assess the overall difficulty of a multiple-choice reading comprehension question. This could help test creators develop more effective and well-calibrated assessments. It could also support the use of adaptive testing approaches, where the difficulty of questions is tailored to the individual test-taker.
Technical Explanation
The paper proposes a model for ranking the difficulty of multiple-choice reading comprehension questions. The approach considers various linguistic and cognitive features that contribute to question difficulty, including:
- Linguistic complexity: Factors like the length and complexity of the question stem, as well as the answer choices.
- Reasoning complexity: The level of inference and analysis required to identify the correct answer.
- Answer choice similarity: The degree of similarity between the correct answer and the incorrect distractors.
The researchers trained a regression model to predict the difficulty level of questions based on these features. They evaluated the model on multiple public reading comprehension datasets, demonstrating its ability to accurately rank questions by difficulty.
The findings suggest this type of difficulty ranking model could be useful for the automatic generation and evaluation of reading comprehension test items. It could also support the development of adaptive testing systems that personalize the question difficulty based on the user's performance.
Critical Analysis
The paper provides a valuable contribution to the challenge of designing effective reading comprehension assessments. By modeling the factors that influence question difficulty, the proposed approach can help create more consistent and well-calibrated tests.
However, the paper acknowledges that the difficulty ranking model does not capture all the nuances of human judgment. There may be additional contextual or cognitive factors that influence how people perceive the difficulty of a question. Further research could explore incorporating more sophisticated natural language processing or instruction-tuned language models to better capture these subtleties.
Additionally, the model was trained and evaluated on existing reading comprehension datasets. Its performance on newly generated questions or in real-world testing scenarios remains an open question. Exploring techniques for automated distractor generation could also be a promising avenue to further improve the quality and difficulty calibration of multiple-choice questions.
Conclusion
This paper presents a novel approach for automatically ranking the difficulty of multiple-choice reading comprehension questions. By considering linguistic, reasoning, and answer choice factors, the proposed model can provide valuable insights to help create more effective and well-calibrated assessments.
The findings have implications for the development of adaptive testing systems that personalize the question difficulty to the individual user's abilities. Furthermore, the difficulty ranking model could be integrated with approaches for the automated generation and evaluation of reading comprehension test items.
Overall, this research represents an important step towards improving the quality and utility of reading comprehension assessments, with potential benefits for education, cognitive science, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Question Difficulty Ranking for Multiple-Choice Reading Comprehension
Vatsal Raina, Mark Gales
Multiple-choice (MC) tests are an efficient method to assess English learners. It is useful for test creators to rank candidate MC questions by difficulty during exam curation. Typically, the difficulty is determined by having human test takers trial the questions in a pretesting stage. However, this is expensive and not scalable. Therefore, we explore automated approaches to rank MC questions by difficulty. However, there is limited data for explicit training of a system for difficulty scores. Hence, we compare task transfer and zero-shot approaches: task transfer adapts level classification and reading comprehension systems for difficulty ranking while zero-shot prompting of instruction finetuned language models contrasts absolute assessment against comparative. It is found that level classification transfers better than reading comprehension. Additionally, zero-shot comparative assessment is more effective at difficulty ranking than the absolute assessment and even the task transfer approaches at question difficulty ranking with a Spearman's correlation of 40.4%. Combining the systems is observed to further boost the correlation.
Read more4/17/2024
0
Automatic Generation and Evaluation of Reading Comprehension Test Items with Large Language Models
Andreas Sauberli, Simon Clematide
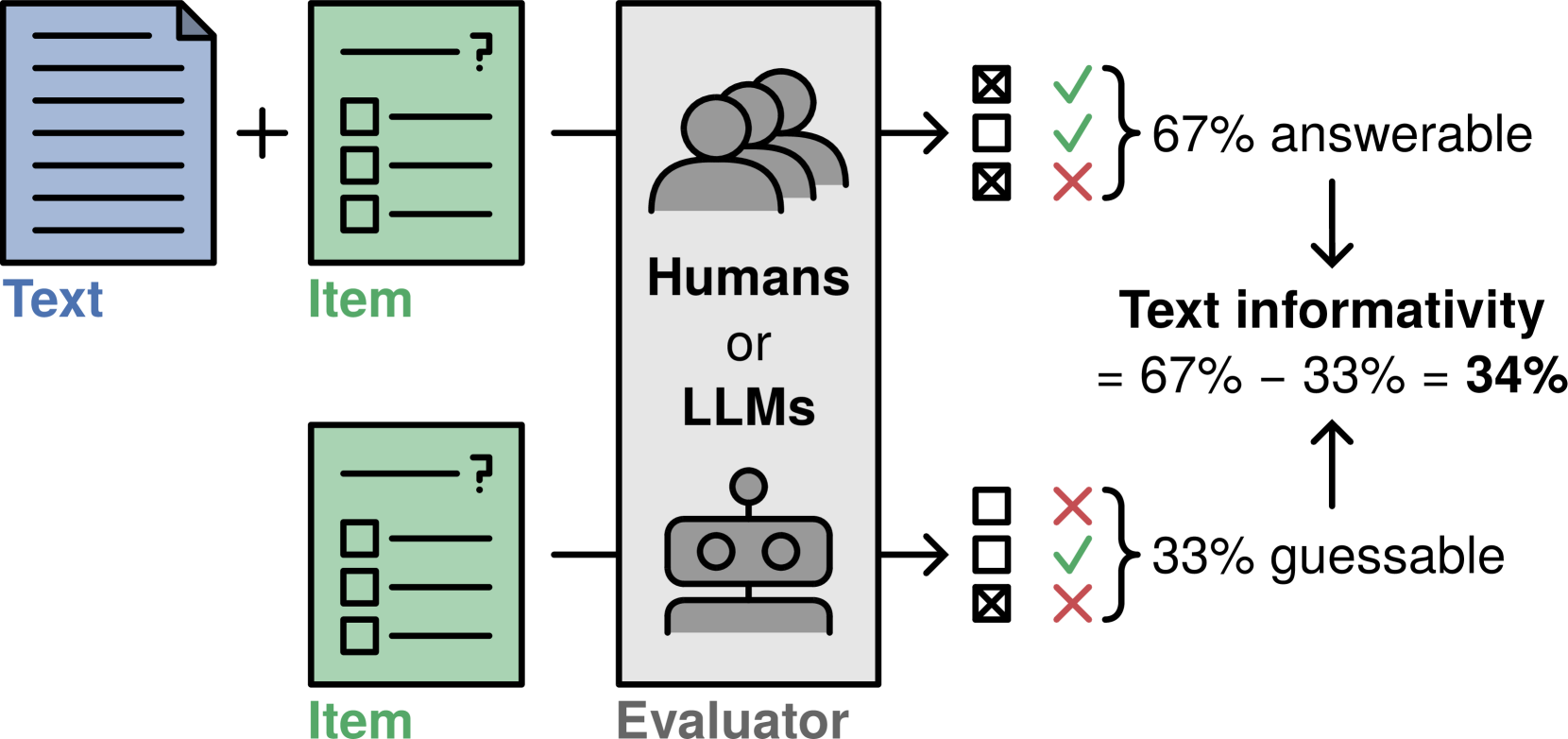
Reading comprehension tests are used in a variety of applications, reaching from education to assessing the comprehensibility of simplified texts. However, creating such tests manually and ensuring their quality is difficult and time-consuming. In this paper, we explore how large language models (LLMs) can be used to generate and evaluate multiple-choice reading comprehension items. To this end, we compiled a dataset of German reading comprehension items and developed a new protocol for human and automatic evaluation, including a metric we call text informativity, which is based on guessability and answerability. We then used this protocol and the dataset to evaluate the quality of items generated by Llama 2 and GPT-4. Our results suggest that both models are capable of generating items of acceptable quality in a zero-shot setting, but GPT-4 clearly outperforms Llama 2. We also show that LLMs can be used for automatic evaluation by eliciting item reponses from them. In this scenario, evaluation results with GPT-4 were the most similar to human annotators. Overall, zero-shot generation with LLMs is a promising approach for generating and evaluating reading comprehension test items, in particular for languages without large amounts of available data.
Read more5/22/2024
🤖
0
Investigating a Benchmark for Training-set free Evaluation of Linguistic Capabilities in Machine Reading Comprehension
Viktor Schlegel, Goran Nenadic, Riza Batista-Navarro
Performance of NLP systems is typically evaluated by collecting a large-scale dataset by means of crowd-sourcing to train a data-driven model and evaluate it on a held-out portion of the data. This approach has been shown to suffer from spurious correlations and the lack of challenging examples that represent the diversity of natural language. Instead, we examine a framework for evaluating optimised models in training-set free setting on synthetically generated challenge sets. We find that despite the simplicity of the generation method, the data can compete with crowd-sourced datasets with regard to naturalness and lexical diversity for the purpose of evaluating the linguistic capabilities of MRC models. We conduct further experiments and show that state-of-the-art language model-based MRC systems can learn to succeed on the challenge set correctly, although, without capturing the general notion of the evaluated phenomenon.
Read more8/12/2024
🛸
0
Improving Automated Distractor Generation for Math Multiple-choice Questions with Overgenerate-and-rank
Alexander Scarlatos, Wanyong Feng, Digory Smith, Simon Woodhead, Andrew Lan
Multiple-choice questions (MCQs) are commonly used across all levels of math education since they can be deployed and graded at a large scale. A critical component of MCQs is the distractors, i.e., incorrect answers crafted to reflect student errors or misconceptions. Automatically generating them in math MCQs, e.g., with large language models, has been challenging. In this work, we propose a novel method to enhance the quality of generated distractors through overgenerate-and-rank, training a ranking model to predict how likely distractors are to be selected by real students. Experimental results on a real-world dataset and human evaluation with math teachers show that our ranking model increases alignment with human-authored distractors, although human-authored ones are still preferred over generated ones.
Read more5/15/2024