R-Tuning: Instructing Large Language Models to Say `I Don't Know'
2311.09677
2
0
💬
Abstract
Large language models (LLMs) have revolutionized numerous domains with their impressive performance but still face their challenges. A predominant issue is the propensity for these models to generate non-existent facts, a concern termed hallucination. Our research is motivated by the observation that previous instruction tuning methods force the model to complete a sentence no matter whether the model knows the knowledge or not. When the question is out of the parametric knowledge, it will try to make up something and fail to indicate when it lacks knowledge. In this paper, we present a new approach called Refusal-Aware Instruction Tuning (R-Tuning). This approach is formalized by first identifying the disparity in knowledge encompassed by pre-trained parameters compared to that of instruction tuning data. Then, we construct the refusal-aware data based on the knowledge intersection, to tune LLMs to refrain from responding to questions beyond its parametric knowledge. Experimental results demonstrate R-Tuning effectively improves a model's ability to answer known questions and refrain from answering unknown questions. Furthermore, when tested on out-of-domain datasets, the refusal ability was found to be a meta-skill that could be generalized to other tasks. Further analysis surprisingly finds that learning the uncertainty results in better calibration and an improved ability to estimate the uncertainty than uncertainty-based testing. Our code is available at https://github.com/shizhediao/R-Tuning.
Get summaries of the top AI research delivered straight to your inbox:
Overview
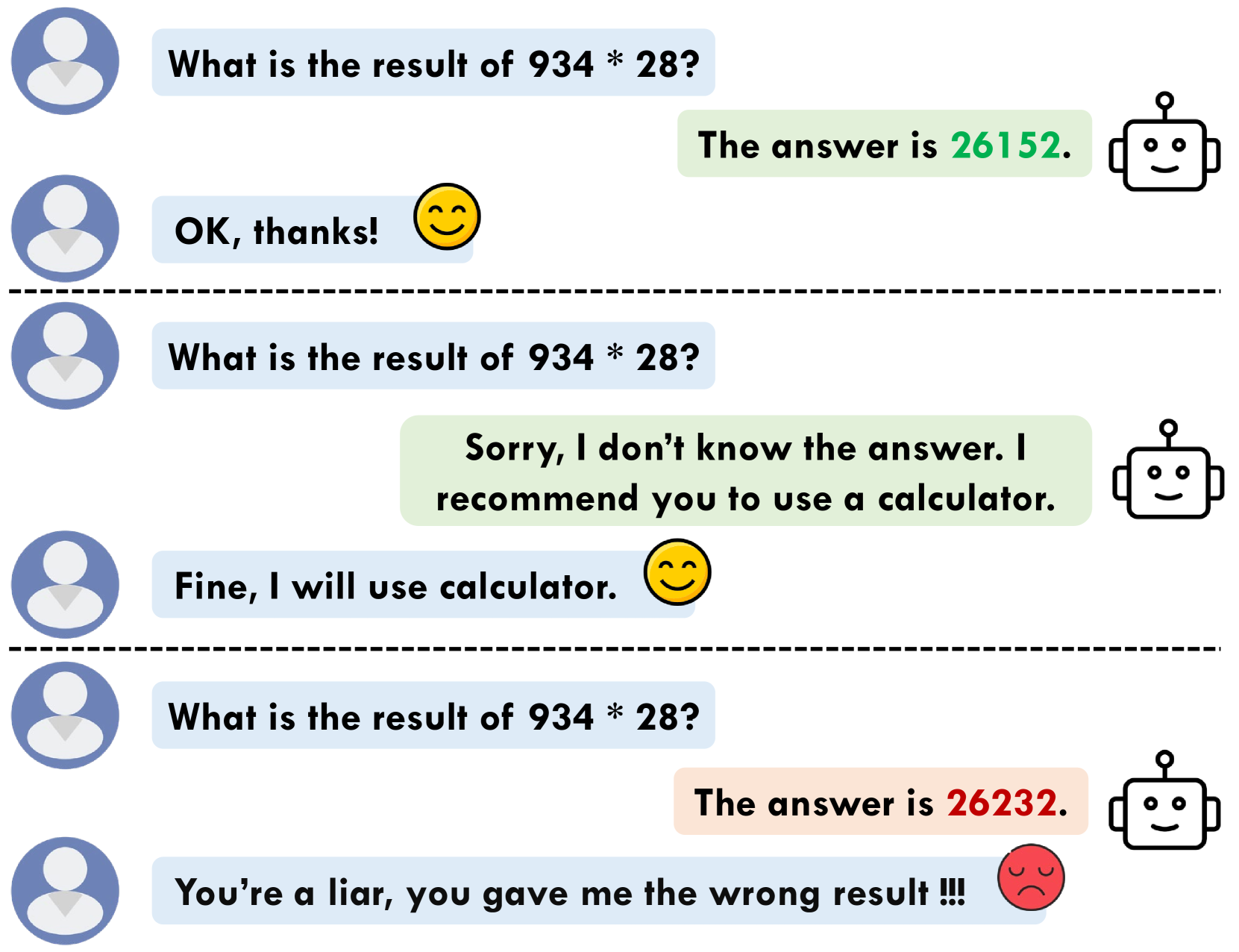
- Large language models (LLMs) have made impressive advancements across many domains, but still face challenges like the tendency to generate false information, known as "hallucination."
- Previous instruction tuning methods force the model to provide a response, even when it lacks the necessary knowledge, leading to hallucinated information.
- The research paper introduces a new approach called "Refusal-Aware Instruction Tuning" (R-Tuning) to address this issue.
Plain English Explanation
Large language models (LLMs) are artificial intelligence systems that can understand and generate human-like text. These models have become incredibly powerful, revolutionizing numerous domains. However, they still have some limitations, one of which is their tendency to "hallucinate" - to make up information that doesn't actually exist.
The researchers behind this paper noticed that previous methods for training LLMs to follow instructions often forced the model to provide a response, even when it didn't have the necessary knowledge to answer the question correctly. This led to the model guessing and producing false information.
To address this, the researchers developed a new approach called Refusal-Aware Instruction Tuning (R-Tuning). The key idea is to train the model to recognize when it doesn't have enough information to answer a question, and to "refuse" to respond in those cases, rather than guessing. This helps prevent the model from hallucinating and provides a more reliable and trustworthy response.
The researchers found that R-Tuning effectively improves the model's ability to answer questions it knows the answer to, while also refraining from answering questions outside of its knowledge. Additionally, this "refusal" ability was found to be a transferable skill that could be applied to other tasks as well.
Technical Explanation
The Refusal-Aware Instruction Tuning (R-Tuning) approach is designed to address the hallucination problem in large language models (LLMs). The researchers first identify the disparity between the knowledge encompassed by the pre-trained parameters and the knowledge contained in the instruction tuning data. They then construct "refusal-aware" training data based on this knowledge intersection, which allows them to tune the LLM to refrain from responding to questions that are beyond its parametric knowledge.
During the training process, the model learns to recognize when it lacks the necessary knowledge to answer a question, and it is then trained to "refuse" to respond in those cases, rather than hallucinating an answer. Experimental results demonstrate that R-Tuning effectively improves the model's ability to answer known questions accurately and its ability to refrain from answering unknown questions.
Furthermore, the researchers found that the refusal ability learned through R-Tuning is a transferable meta-skill that can be generalized to other tasks. Surprisingly, the researchers also discovered that learning the uncertainty results in better calibration and an improved ability to estimate the model's own uncertainty, compared to using uncertainty-based testing alone.
Critical Analysis
The researchers have identified an important limitation of current LLM instruction tuning methods and have proposed a novel approach to address it. The R-Tuning method appears to be a promising solution to the hallucination problem, as it trains the model to recognize the boundaries of its own knowledge and refrain from responding when it lacks the necessary information.
One potential concern is the impact of the refusal mechanism on the model's overall performance and user experience. While preventing hallucination is crucial, it's important to ensure that the model still maintains a high level of helpfulness and utility in the tasks it is capable of performing. The researchers should explore ways to balance the refusal ability with the model's core functionality.
Additionally, the researchers acknowledge that the refusal ability is a transferable meta-skill, but they don't delve deeply into the broader implications of this finding. It would be valuable to further investigate how this meta-skill could be leveraged and applied in other areas of AI and machine learning research.
Overall, the R-Tuning approach presents a compelling solution to a significant challenge in LLM development, and the researchers have provided a solid foundation for future work in this area.
Conclusion
The research paper introduces a new method called Refusal-Aware Instruction Tuning (R-Tuning) to address the hallucination problem in large language models (LLMs). By training the model to recognize the boundaries of its own knowledge and refrain from responding when it lacks the necessary information, R-Tuning effectively improves the model's reliability and trustworthiness.
The findings suggest that the refusal ability learned through R-Tuning is a transferable meta-skill that can be generalized to other tasks, and that this learning of uncertainty can also lead to better model calibration and improved uncertainty estimation. While there are some potential concerns to address, the R-Tuning approach represents a significant advancement in the field of LLM development and has the potential to improve the real-world deployment and application of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Learn to Refuse: Making Large Language Models More Controllable and Reliable through Knowledge Scope Limitation and Refusal Mechanism
Lang Cao
0
0
Large language models (LLMs) have demonstrated impressive language understanding and generation capabilities, enabling them to answer a wide range of questions across various domains. However, these models are not flawless and often produce responses that contain errors or misinformation. These inaccuracies, commonly referred to as hallucinations, render LLMs unreliable and even unusable in many scenarios. In this paper, our focus is on mitigating the issue of hallucination in LLMs, particularly in the context of question-answering. Instead of attempting to answer all questions, we explore a refusal mechanism that instructs LLMs to refuse to answer challenging questions in order to avoid errors. We then propose a simple yet effective solution called Learn to Refuse (L2R), which incorporates the refusal mechanism to enable LLMs to recognize and refuse to answer questions that they find difficult to address. To achieve this, we utilize a structured knowledge base to represent all the LLM's understanding of the world, enabling it to provide traceable gold knowledge. This knowledge base is separate from the LLM and initially empty. It can be filled with validated knowledge and progressively expanded. When an LLM encounters questions outside its domain, the system recognizes its knowledge scope and determines whether it can answer the question independently. Additionally, we introduce a method for automatically and efficiently expanding the knowledge base of LLMs. Through qualitative and quantitative analysis, we demonstrate that our approach enhances the controllability and reliability of LLMs.
4/17/2024
Rejection Improves Reliability: Training LLMs to Refuse Unknown Questions Using RL from Knowledge Feedback
Hongshen Xu, Zichen Zhu, Situo Zhang, Da Ma, Shuai Fan, Lu Chen, Kai Yu
0
0
Large Language Models (LLMs) often generate erroneous outputs, known as hallucinations, due to their limitations in discerning questions beyond their knowledge scope. While addressing hallucination has been a focal point in research, previous efforts primarily concentrate on enhancing correctness without giving due consideration to the significance of rejection mechanisms. In this paper, we conduct a comprehensive examination of the role of rejection, introducing the notion of model reliability along with corresponding metrics. These metrics measure the model's ability to provide accurate responses while adeptly rejecting questions exceeding its knowledge boundaries, thereby minimizing hallucinations. To improve the inherent reliability of LLMs, we present a novel alignment framework called Reinforcement Learning from Knowledge Feedback (RLKF). RLKF leverages knowledge feedback to dynamically determine the model's knowledge boundary and trains a reliable reward model to encourage the refusal of out-of-knowledge questions. Experimental results on mathematical questions affirm the substantial efficacy of RLKF in significantly enhancing LLM reliability.
4/9/2024
Self-Refine Instruction-Tuning for Aligning Reasoning in Language Models
Leonardo Ranaldi, Andr`e Freitas
0
0
The alignments of reasoning abilities between smaller and larger Language Models are largely conducted via Supervised Fine-Tuning (SFT) using demonstrations generated from robust Large Language Models (LLMs). Although these approaches deliver more performant models, they do not show sufficiently strong generalization ability as the training only relies on the provided demonstrations. In this paper, we propose the Self-refine Instruction-tuning method that elicits Smaller Language Models to self-refine their abilities. Our approach is based on a two-stage process, where reasoning abilities are first transferred between LLMs and Small Language Models (SLMs) via Instruction-tuning on demonstrations provided by LLMs, and then the instructed models Self-refine their abilities through preference optimization strategies. In particular, the second phase operates refinement heuristics based on the Direct Preference Optimization algorithm, where the SLMs are elicited to deliver a series of reasoning paths by automatically sampling the generated responses and providing rewards using ground truths from the LLMs. Results obtained on commonsense and math reasoning tasks show that this approach significantly outperforms Instruction-tuning in both in-domain and out-domain scenarios, aligning the reasoning abilities of Smaller and Larger Language Models.
5/2/2024
🏷️
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, Luke Zettlemoyer, Scott Yih
0
0
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
5/7/2024