Rejection Improves Reliability: Training LLMs to Refuse Unknown Questions Using RL from Knowledge Feedback
2403.18349
0
0
Abstract
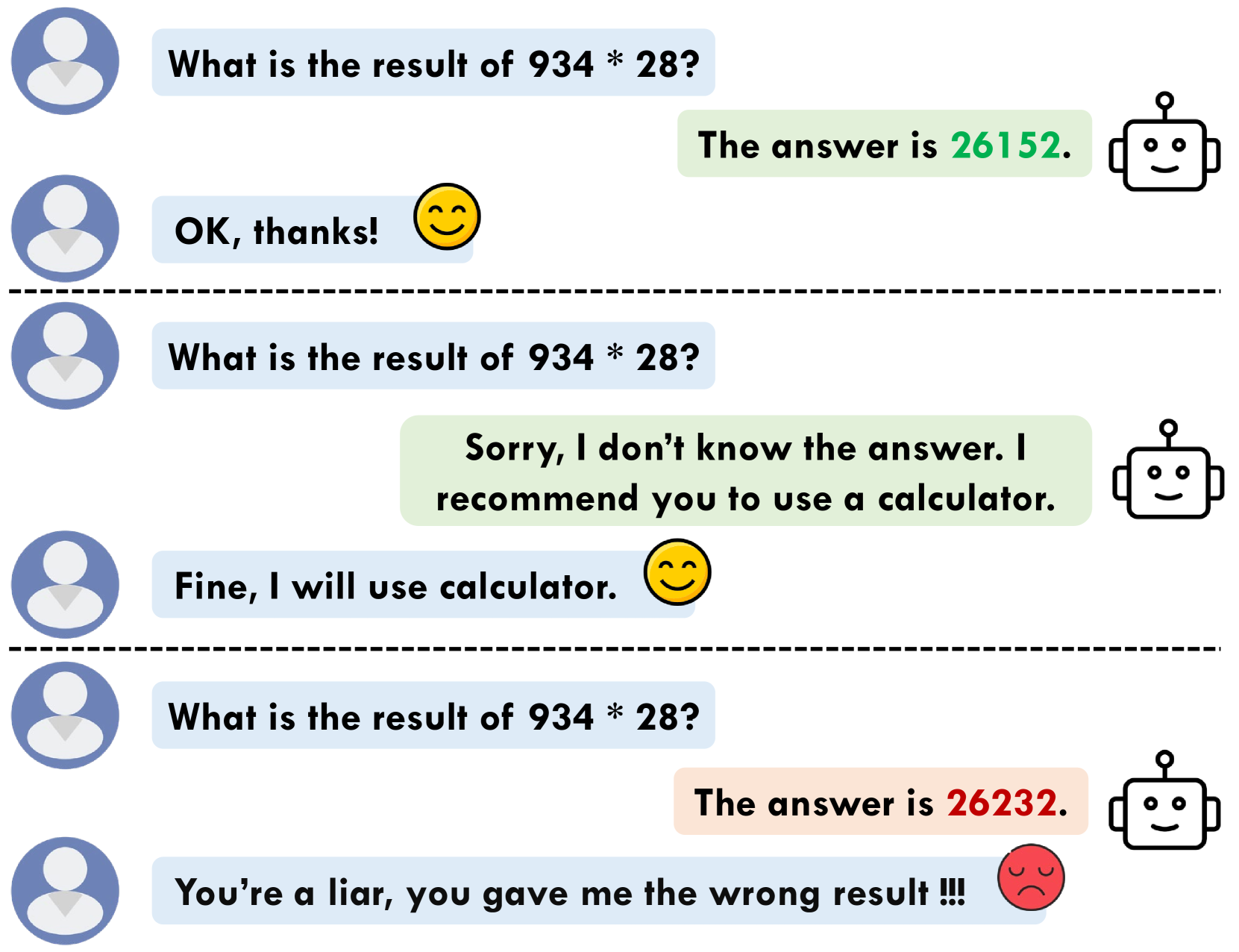
Large Language Models (LLMs) often generate erroneous outputs, known as hallucinations, due to their limitations in discerning questions beyond their knowledge scope. While addressing hallucination has been a focal point in research, previous efforts primarily concentrate on enhancing correctness without giving due consideration to the significance of rejection mechanisms. In this paper, we conduct a comprehensive examination of the role of rejection, introducing the notion of model reliability along with corresponding metrics. These metrics measure the model's ability to provide accurate responses while adeptly rejecting questions exceeding its knowledge boundaries, thereby minimizing hallucinations. To improve the inherent reliability of LLMs, we present a novel alignment framework called Reinforcement Learning from Knowledge Feedback (RLKF). RLKF leverages knowledge feedback to dynamically determine the model's knowledge boundary and trains a reliable reward model to encourage the refusal of out-of-knowledge questions. Experimental results on mathematical questions affirm the substantial efficacy of RLKF in significantly enhancing LLM reliability.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a method for training large language models (LLMs) to reliably refuse questions that are outside of their knowledge or capabilities, in order to improve their overall reliability.
- The researchers used reinforcement learning (RL) from knowledge feedback to train the LLMs to identify when they were being asked questions they could not confidently answer, and to respond by refusing the question rather than attempting to generate an answer.
- The goal was to improve the overall reliability and trustworthiness of LLMs by reducing the instances of hallucination or self-generated incorrect responses.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly capable at generating human-like text on a wide range of topics. However, they can also sometimes produce responses that are inaccurate or don't actually reflect their true knowledge. This can lead to users trusting the model's outputs even when they are mistaken or made up.
To address this, the researchers in this paper trained the LLMs to be more reliable by teaching them to recognize when they don't have enough information to confidently answer a question. Instead of guessing or hallucinating an answer, the models were trained to simply refuse the question.
The key idea is that by being honest about the limits of their knowledge, the LLMs can [avoid generating misleading or incorrect responses, which ultimately makes them more trustworthy and reliable for users. This can be especially important in applications like summarization or conversational systems where the model's outputs can have real-world impacts.
Technical Explanation
The researchers used a reinforcement learning (RL) approach to train the LLMs to refuse questions that were outside of their knowledge. During training, the model was presented with a mix of in-domain and out-of-domain questions. For in-domain questions, the model was rewarded for providing a correct answer. For out-of-domain questions, the model was rewarded for refusing to answer.
Over the course of training, the model learned to effectively identify when a question was outside of its capabilities, and to respond by politely refusing to answer rather than attempting to generate a response. The researchers evaluated the trained models on a held-out test set and found that they were able to reliably refuse out-of-domain questions while maintaining strong performance on in-domain questions.
Critical Analysis
The researchers acknowledge several limitations of their approach. First, the model was only trained to refuse questions, and did not learn to provide more helpful responses like directing the user to a more appropriate resource. Expanding the model's capabilities in this direction could make it more useful in real-world applications.
Additionally, the training process relied on having a clear delineation between in-domain and out-of-domain questions, which may not always be the case in practice. Further research would be needed to understand how these models perform when faced with more ambiguous or borderline cases.
Overall, this work represents an important step towards building more reliable and trustworthy LLMs. By teaching models to be upfront about the limits of their knowledge, the researchers have demonstrated a promising approach for enhancing the transparency and accountability of these increasingly influential AI systems.
Conclusion
This paper presents a novel method for training large language models to reliably refuse questions that are outside of their knowledge or capabilities. By using reinforcement learning from knowledge feedback, the researchers were able to teach the models to identify when they were being asked something they couldn't confidently answer, and to respond by politely refusing rather than attempting to generate a potentially inaccurate or misleading response.
This approach has the potential to significantly improve the overall reliability and trustworthiness of LLMs, which is crucial as these models become more widely deployed in high-stakes applications. While further research is needed to address some of the limitations, this work represents an important step forward in building AI systems that are more transparent about their abilities and limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Learn to Refuse: Making Large Language Models More Controllable and Reliable through Knowledge Scope Limitation and Refusal Mechanism
Lang Cao
0
0
Large language models (LLMs) have demonstrated impressive language understanding and generation capabilities, enabling them to answer a wide range of questions across various domains. However, these models are not flawless and often produce responses that contain errors or misinformation. These inaccuracies, commonly referred to as hallucinations, render LLMs unreliable and even unusable in many scenarios. In this paper, our focus is on mitigating the issue of hallucination in LLMs, particularly in the context of question-answering. Instead of attempting to answer all questions, we explore a refusal mechanism that instructs LLMs to refuse to answer challenging questions in order to avoid errors. We then propose a simple yet effective solution called Learn to Refuse (L2R), which incorporates the refusal mechanism to enable LLMs to recognize and refuse to answer questions that they find difficult to address. To achieve this, we utilize a structured knowledge base to represent all the LLM's understanding of the world, enabling it to provide traceable gold knowledge. This knowledge base is separate from the LLM and initially empty. It can be filled with validated knowledge and progressively expanded. When an LLM encounters questions outside its domain, the system recognizes its knowledge scope and determines whether it can answer the question independently. Additionally, we introduce a method for automatically and efficiently expanding the knowledge base of LLMs. Through qualitative and quantitative analysis, we demonstrate that our approach enhances the controllability and reliability of LLMs.
4/17/2024
💬
Mitigating Hallucinations in Large Language Models via Self-Refinement-Enhanced Knowledge Retrieval
Mengjia Niu, Hao Li, Jie Shi, Hamed Haddadi, Fan Mo
0
0
Large language models (LLMs) have demonstrated remarkable capabilities across various domains, although their susceptibility to hallucination poses significant challenges for their deployment in critical areas such as healthcare. To address this issue, retrieving relevant facts from knowledge graphs (KGs) is considered a promising method. Existing KG-augmented approaches tend to be resource-intensive, requiring multiple rounds of retrieval and verification for each factoid, which impedes their application in real-world scenarios. In this study, we propose Self-Refinement-Enhanced Knowledge Graph Retrieval (Re-KGR) to augment the factuality of LLMs' responses with less retrieval efforts in the medical field. Our approach leverages the attribution of next-token predictive probability distributions across different tokens, and various model layers to primarily identify tokens with a high potential for hallucination, reducing verification rounds by refining knowledge triples associated with these tokens. Moreover, we rectify inaccurate content using retrieved knowledge in the post-processing stage, which improves the truthfulness of generated responses. Experimental results on a medical dataset demonstrate that our approach can enhance the factual capability of LLMs across various foundational models as evidenced by the highest scores on truthfulness.
5/13/2024
TeaMs-RL: Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning
Shangding Gu, Alois Knoll, Ming Jin
0
0
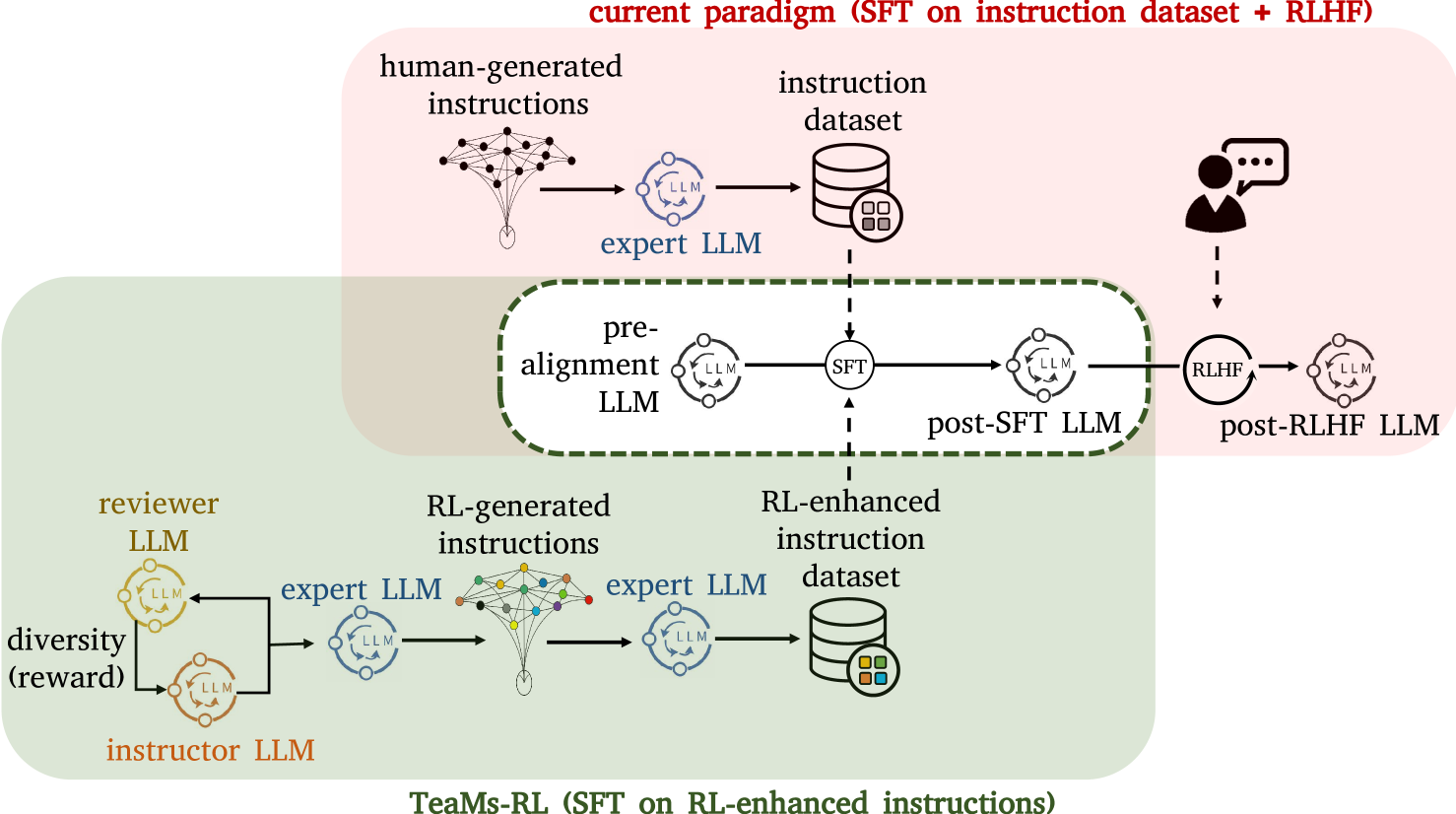
The development of Large Language Models (LLMs) often confronts challenges stemming from the heavy reliance on human annotators in the reinforcement learning with human feedback (RLHF) framework, or the frequent and costly external queries tied to the self-instruct paradigm. In this work, we pivot to Reinforcement Learning (RL) -- but with a twist. Diverging from the typical RLHF, which refines LLMs following instruction data training, we use RL to directly generate the foundational instruction dataset that alone suffices for fine-tuning. Our method, TeaMs-RL, uses a suite of textual operations and rules, prioritizing the diversification of training datasets. It facilitates the generation of high-quality data without excessive reliance on external advanced models, paving the way for a single fine-tuning step and negating the need for subsequent RLHF stages. Our findings highlight key advantages of our approach: reduced need for human involvement and fewer model queries (only $5.73%$ of WizardLM's total), along with enhanced capabilities of LLMs in crafting and comprehending complex instructions compared to strong baselines, and substantially improved model privacy protection.
5/7/2024
Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts
Jing-Cheng Pang, Si-Hang Yang, Kaiyuan Li, Jiaji Zhang, Xiong-Hui Chen, Nan Tang, Yang Yu
0
0
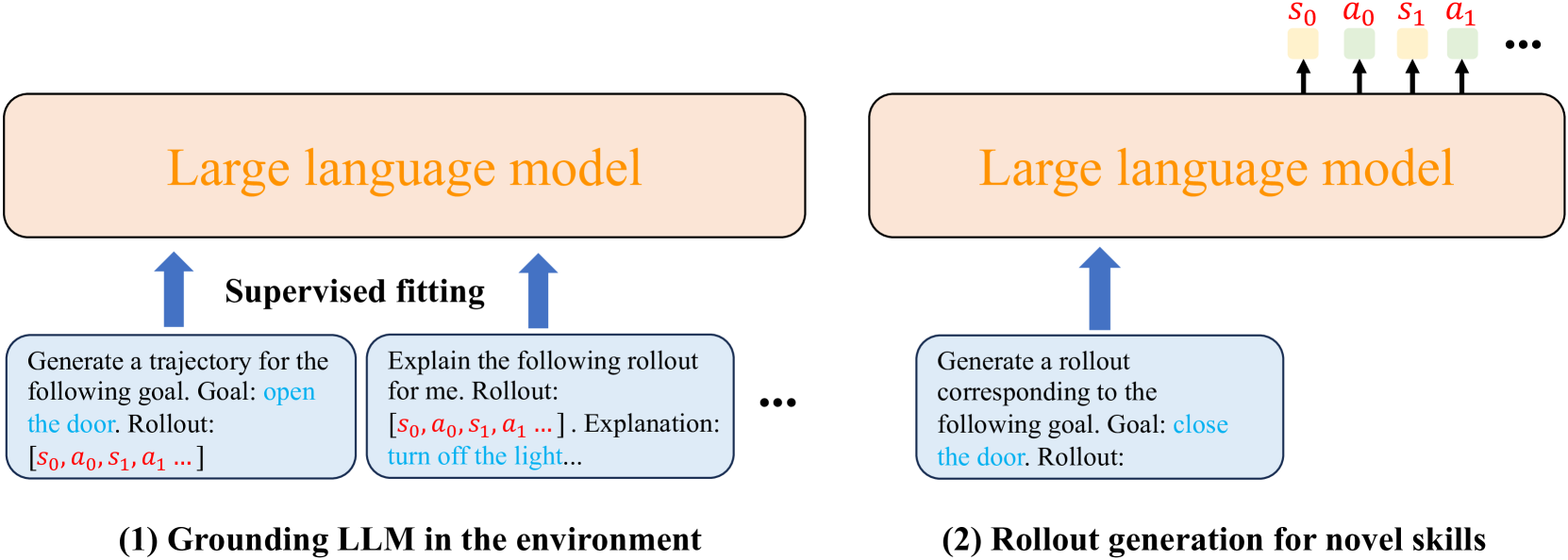
Reinforcement learning (RL) trains agents to accomplish complex tasks through environmental interaction data, but its capacity is also limited by the scope of the available data. To obtain a knowledgeable agent, a promising approach is to leverage the knowledge from large language models (LLMs). Despite previous studies combining LLMs with RL, seamless integration of the two components remains challenging due to their semantic gap. This paper introduces a novel method, Knowledgeable Agents from Language Model Rollouts (KALM), which extracts knowledge from LLMs in the form of imaginary rollouts that can be easily learned by the agent through offline reinforcement learning methods. The primary challenge of KALM lies in LLM grounding, as LLMs are inherently limited to textual data, whereas environmental data often comprise numerical vectors unseen to LLMs. To address this, KALM fine-tunes the LLM to perform various tasks based on environmental data, including bidirectional translation between natural language descriptions of skills and their corresponding rollout data. This grounding process enhances the LLM's comprehension of environmental dynamics, enabling it to generate diverse and meaningful imaginary rollouts that reflect novel skills. Initial empirical evaluations on the CLEVR-Robot environment demonstrate that KALM enables agents to complete complex rephrasings of task goals and extend their capabilities to novel tasks requiring unprecedented optimal behaviors. KALM achieves a success rate of 46% in executing tasks with unseen goals, substantially surpassing the 26% success rate achieved by baseline methods. Furthermore, KALM effectively enables the LLM to comprehend environmental dynamics, resulting in the generation of meaningful imaginary rollouts that reflect novel skills and demonstrate the seamless integration of large language models and reinforcement learning.
4/16/2024