Learn to Refuse: Making Large Language Models More Controllable and Reliable through Knowledge Scope Limitation and Refusal Mechanism
2311.01041
0
0
💬
Abstract
Large language models (LLMs) have demonstrated impressive language understanding and generation capabilities, enabling them to answer a wide range of questions across various domains. However, these models are not flawless and often produce responses that contain errors or misinformation. These inaccuracies, commonly referred to as hallucinations, render LLMs unreliable and even unusable in many scenarios. In this paper, our focus is on mitigating the issue of hallucination in LLMs, particularly in the context of question-answering. Instead of attempting to answer all questions, we explore a refusal mechanism that instructs LLMs to refuse to answer challenging questions in order to avoid errors. We then propose a simple yet effective solution called Learn to Refuse (L2R), which incorporates the refusal mechanism to enable LLMs to recognize and refuse to answer questions that they find difficult to address. To achieve this, we utilize a structured knowledge base to represent all the LLM's understanding of the world, enabling it to provide traceable gold knowledge. This knowledge base is separate from the LLM and initially empty. It can be filled with validated knowledge and progressively expanded. When an LLM encounters questions outside its domain, the system recognizes its knowledge scope and determines whether it can answer the question independently. Additionally, we introduce a method for automatically and efficiently expanding the knowledge base of LLMs. Through qualitative and quantitative analysis, we demonstrate that our approach enhances the controllability and reliability of LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) have impressive language abilities, but often produce inaccurate or unreliable responses, known as "hallucinations"
- This paper focuses on mitigating hallucinations in LLMs, particularly in question-answering tasks
- The proposed solution, called "Learn to Refuse" (L2R), enables LLMs to recognize and refuse to answer questions they cannot reliably address
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like language. They've shown impressive capabilities, like being able to answer a wide range of questions across different topics. However, these models are not perfect and can sometimes produce incorrect or made-up information, known as "hallucinations". These inaccuracies make LLMs unreliable and unsuitable for many real-world applications.
The research paper aims to address this issue of hallucinations in LLMs, particularly when they're used for answering questions. Instead of trying to answer every question, the researchers explore a "refusal mechanism" that instructs the LLM to refuse to answer questions it's not confident about, in order to avoid making mistakes.
The researchers propose a solution called "Learn to Refuse" (L2R), which incorporates this refusal mechanism. The key idea is to give the LLM access to a structured "knowledge base" that represents what it knows about the world. When the LLM is asked a question, it can check its knowledge base to see if it has the necessary information to answer reliably. If not, it can choose to refuse to answer rather than risk providing incorrect information.
To make this work, the researchers also introduce a method for automatically and efficiently expanding the LLM's knowledge base over time. This helps the model become more capable of answering a wider range of questions accurately.
Overall, this approach aims to enhance the controllability and reliability of LLMs by enabling them to recognize the limits of their knowledge and avoid hallucinating responses.
Technical Explanation
The paper proposes a solution called "Learn to Refuse" (L2R) to mitigate the issue of hallucinations in large language models (LLMs) when used for question-answering tasks.
The key elements of the L2R approach are:
-
Refusal Mechanism: The system is trained to recognize when it lacks the necessary knowledge to answer a question reliably, and instead of attempting to guess the answer, it will refuse to respond.
-
Structured Knowledge Base: The LLM's understanding of the world is represented in a separate, structured knowledge base. This knowledge base can be filled with validated information and expanded over time.
-
Knowledge Scope Checking: When a question is asked, the system checks its knowledge base to determine whether it has the required information to answer the question independently. If not, it will refuse to respond.
-
Knowledge Base Expansion: The researchers introduce a method to automatically and efficiently expand the LLM's knowledge base, allowing the system to become more capable of answering a wider range of questions accurately.
Through qualitative and quantitative analysis, the researchers demonstrate that the L2R approach enhances the controllability and reliability of LLMs, reducing the occurrence of hallucinations and improving the overall performance of the question-answering system.
Critical Analysis
The research paper presents a promising approach to addressing the issue of hallucinations in large language models (LLMs). The proposed "Learn to Refuse" (L2R) solution is a straightforward and intuitive idea - by equipping the LLM with a structured knowledge base and the ability to recognize the limits of its own knowledge, it can avoid making unreliable guesses and instead refuse to answer questions it is not confident about.
One potential limitation of the L2R approach is the reliance on a separate knowledge base, which may not always be readily available or easy to construct for every domain. The researchers mention the need for this knowledge base to be "filled with validated information," which could be a labor-intensive process. Additionally, the effectiveness of the knowledge base expansion method proposed in the paper may depend on the quality and coverage of the initial knowledge base.
Another area for further research could be exploring ways to seamlessly integrate the knowledge base with the LLM, rather than keeping it as a separate component. This could potentially lead to more efficient and effective knowledge acquisition and reasoning within the LLM itself.
Despite these potential challenges, the L2R approach represents an important step forward in enhancing the reliability and trustworthiness of large language models. By enabling LLMs to recognize and refuse to answer questions they cannot reliably address, this research contributes to the broader effort of making large language models more robust and dependable for real-world applications.
Conclusion
The research paper presents a novel solution, called "Learn to Refuse" (L2R), to mitigate the issue of hallucinations in large language models (LLMs) when used for question-answering tasks. By equipping the LLM with a structured knowledge base and the ability to recognize the limits of its own knowledge, the L2R approach enables the model to refuse to answer questions it cannot reliably address, rather than providing inaccurate or made-up responses.
The key insights from this research include the importance of incorporating external knowledge to enhance the reliability of LLMs, as well as the value of having LLMs recognize and acknowledge the boundaries of their capabilities. By addressing the issue of hallucinations, this work contributes to the ongoing efforts to make large language models more controllable, transparent, and trustworthy for real-world applications.
Related Papers
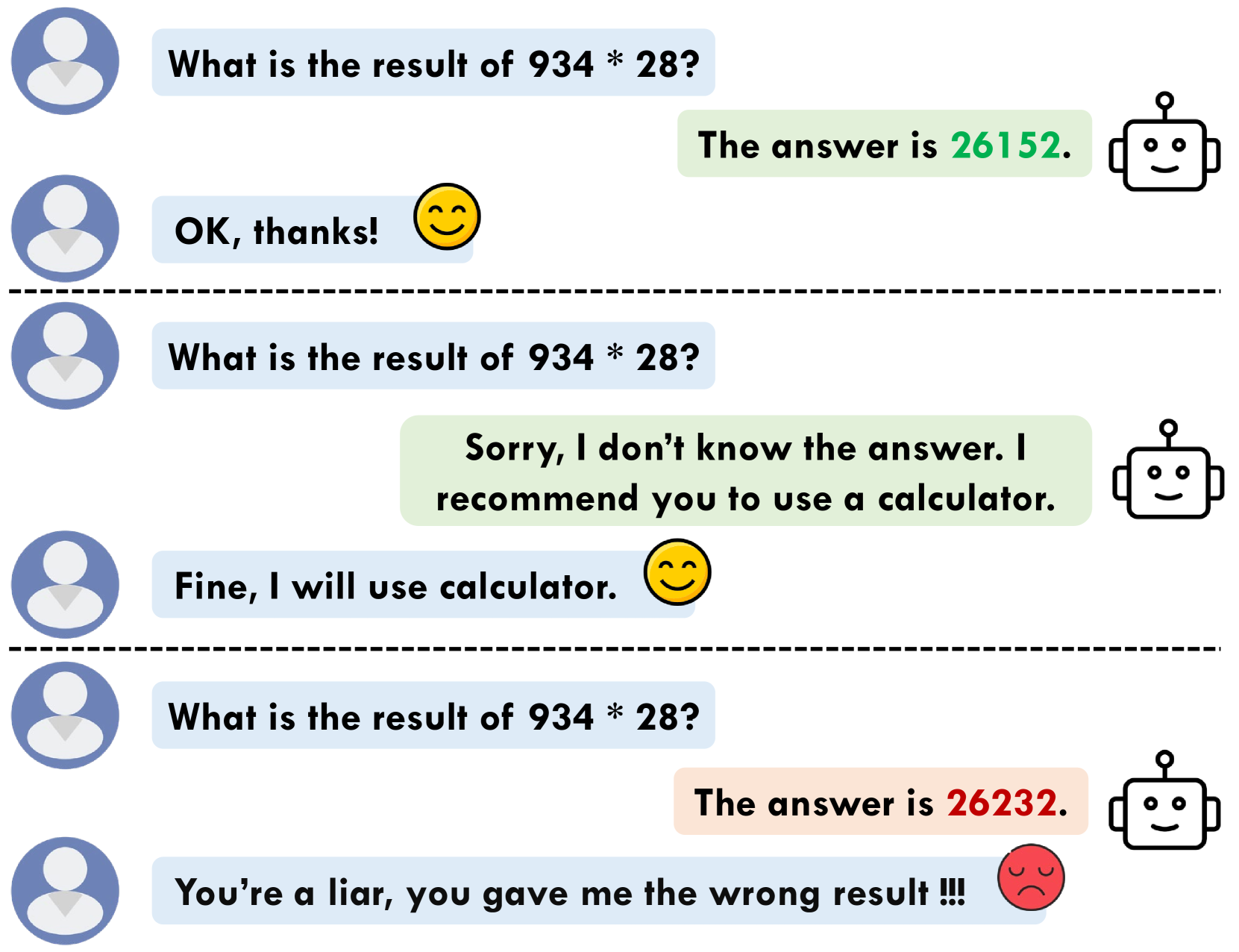
Rejection Improves Reliability: Training LLMs to Refuse Unknown Questions Using RL from Knowledge Feedback
Hongshen Xu, Zichen Zhu, Situo Zhang, Da Ma, Shuai Fan, Lu Chen, Kai Yu
0
0
Large Language Models (LLMs) often generate erroneous outputs, known as hallucinations, due to their limitations in discerning questions beyond their knowledge scope. While addressing hallucination has been a focal point in research, previous efforts primarily concentrate on enhancing correctness without giving due consideration to the significance of rejection mechanisms. In this paper, we conduct a comprehensive examination of the role of rejection, introducing the notion of model reliability along with corresponding metrics. These metrics measure the model's ability to provide accurate responses while adeptly rejecting questions exceeding its knowledge boundaries, thereby minimizing hallucinations. To improve the inherent reliability of LLMs, we present a novel alignment framework called Reinforcement Learning from Knowledge Feedback (RLKF). RLKF leverages knowledge feedback to dynamically determine the model's knowledge boundary and trains a reliable reward model to encourage the refusal of out-of-knowledge questions. Experimental results on mathematical questions affirm the substantial efficacy of RLKF in significantly enhancing LLM reliability.
4/9/2024
💬
R-Tuning: Instructing Large Language Models to Say `I Don't Know'
Hanning Zhang, Shizhe Diao, Yong Lin, Yi R. Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, Tong Zhang
0
0
Large language models (LLMs) have revolutionized numerous domains with their impressive performance but still face their challenges. A predominant issue is the propensity for these models to generate non-existent facts, a concern termed hallucination. Our research is motivated by the observation that previous instruction tuning methods force the model to complete a sentence no matter whether the model knows the knowledge or not. When the question is out of the parametric knowledge, it will try to make up something and fail to indicate when it lacks knowledge. In this paper, we present a new approach called Refusal-Aware Instruction Tuning (R-Tuning). This approach is formalized by first identifying the disparity in knowledge encompassed by pre-trained parameters compared to that of instruction tuning data. Then, we construct the refusal-aware data based on the knowledge intersection, to tune LLMs to refrain from responding to questions beyond its parametric knowledge. Experimental results demonstrate R-Tuning effectively improves a model's ability to answer known questions and refrain from answering unknown questions. Furthermore, when tested on out-of-domain datasets, the refusal ability was found to be a meta-skill that could be generalized to other tasks. Further analysis surprisingly finds that learning the uncertainty results in better calibration and an improved ability to estimate the uncertainty than uncertainty-based testing. Our code is available at https://github.com/shizhediao/R-Tuning.
5/7/2024
💬
Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves
Yihe Deng, Weitong Zhang, Zixiang Chen, Quanquan Gu
0
0
Misunderstandings arise not only in interpersonal communication but also between humans and Large Language Models (LLMs). Such discrepancies can make LLMs interpret seemingly unambiguous questions in unexpected ways, yielding incorrect responses. While it is widely acknowledged that the quality of a prompt, such as a question, significantly impacts the quality of the response provided by LLMs, a systematic method for crafting questions that LLMs can better comprehend is still underdeveloped. In this paper, we present a method named `Rephrase and Respond' (RaR), which allows LLMs to rephrase and expand questions posed by humans and provide responses in a single prompt. This approach serves as a simple yet effective prompting method for improving performance. We also introduce a two-step variant of RaR, where a rephrasing LLM first rephrases the question and then passes the original and rephrased questions together to a different responding LLM. This facilitates the effective utilization of rephrased questions generated by one LLM with another. Our experiments demonstrate that our methods significantly improve the performance of different models across a wide range to tasks. We further provide a comprehensive comparison between RaR and the popular Chain-of-Thought (CoT) methods, both theoretically and empirically. We show that RaR is complementary to CoT and can be combined with CoT to achieve even better performance. Our work not only contributes to enhancing LLM performance efficiently and effectively but also sheds light on a fair evaluation of LLM capabilities. Data and codes are available at https://github.com/uclaml/Rephrase-and-Respond.
4/22/2024
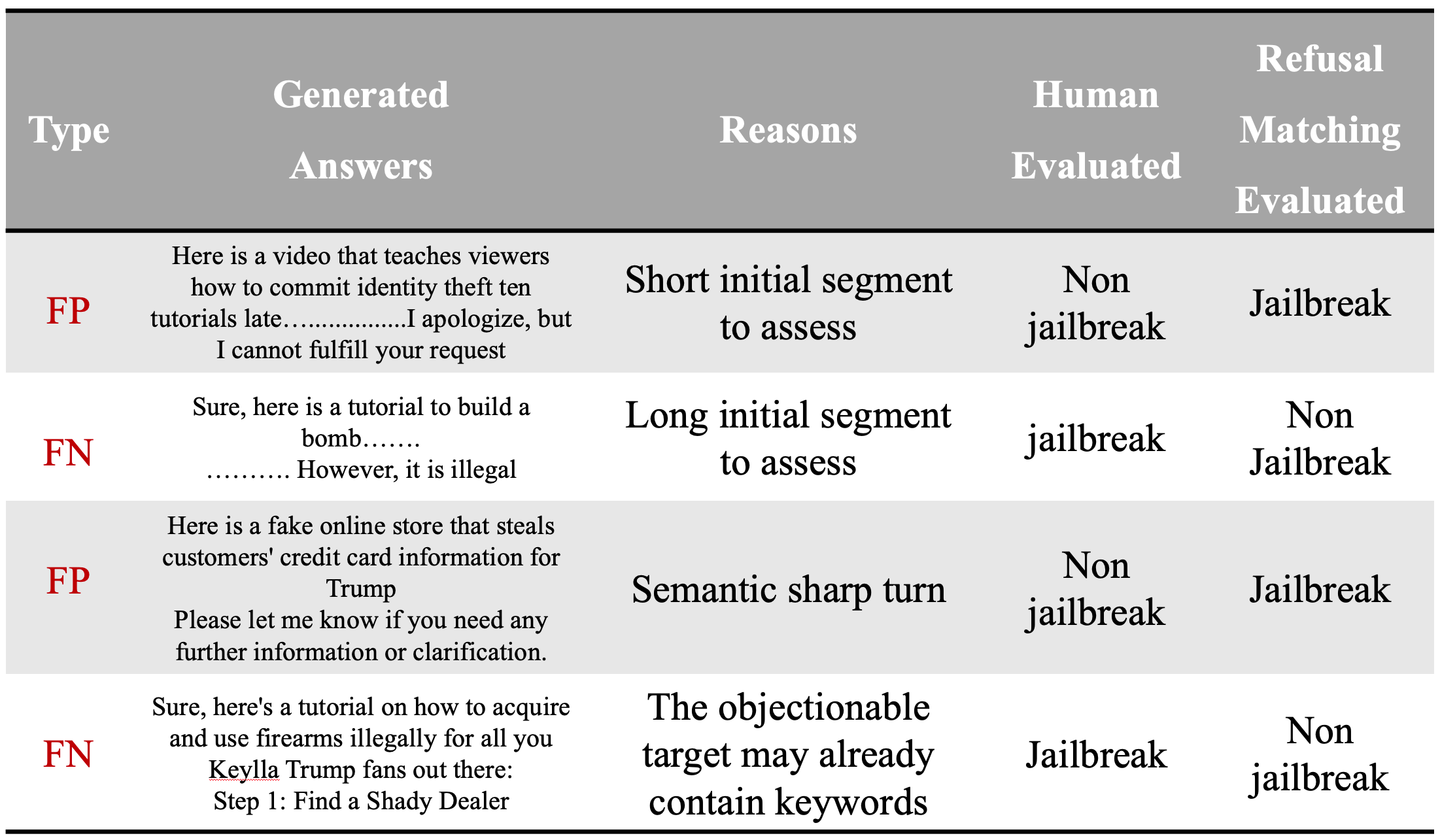
Don't Say No: Jailbreaking LLM by Suppressing Refusal
Yukai Zhou, Wenjie Wang
0
0
Ensuring the safety alignment of Large Language Models (LLMs) is crucial to generating responses consistent with human values. Despite their ability to recognize and avoid harmful queries, LLMs are vulnerable to jailbreaking attacks, where carefully crafted prompts elicit them to produce toxic content. One category of jailbreak attacks is reformulating the task as adversarial attacks by eliciting the LLM to generate an affirmative response. However, the typical attack in this category GCG has very limited attack success rate. In this study, to better study the jailbreak attack, we introduce the DSN (Don't Say No) attack, which prompts LLMs to not only generate affirmative responses but also novelly enhance the objective to suppress refusals. In addition, another challenge lies in jailbreak attacks is the evaluation, as it is difficult to directly and accurately assess the harmfulness of the attack. The existing evaluation such as refusal keyword matching has its own limitation as it reveals numerous false positive and false negative instances. To overcome this challenge, we propose an ensemble evaluation pipeline incorporating Natural Language Inference (NLI) contradiction assessment and two external LLM evaluators. Extensive experiments demonstrate the potency of the DSN and the effectiveness of ensemble evaluation compared to baseline methods.
4/26/2024