RA-ISF: Learning to Answer and Understand from Retrieval Augmentation via Iterative Self-Feedback
2403.06840
0
0

Abstract
Large language models (LLMs) demonstrate exceptional performance in numerous tasks but still heavily rely on knowledge stored in their parameters. Moreover, updating this knowledge incurs high training costs. Retrieval-augmented generation (RAG) methods address this issue by integrating external knowledge. The model can answer questions it couldn't previously by retrieving knowledge relevant to the query. This approach improves performance in certain scenarios for specific tasks. However, if irrelevant texts are retrieved, it may impair model performance. In this paper, we propose Retrieval Augmented Iterative Self-Feedback (RA-ISF), a framework that iteratively decomposes tasks and processes them in three submodules to enhance the model's problem-solving capabilities. Experiments show that our method outperforms existing benchmarks, performing well on models like GPT3.5, Llama2, significantly enhancing factual reasoning capabilities and reducing hallucinations.
Create account to get full access
Overview
- This paper presents RA-ISF (Retrieval Augmentation via Iterative Self-Feedback), a novel approach for learning to answer and understand questions by iteratively refining the retrieved information.
- RA-ISF combines a language model with a retrieval module, allowing the model to augment its initial response by retrieving additional relevant information and incorporating it through iterative feedback.
- The key idea is to enable the model to learn how to effectively leverage retrieval to improve its understanding and answering of questions.
Plain English Explanation
RA-ISF is a new way for AI systems to answer and understand questions. It works by combining a language model with a retrieval module. The language model generates an initial response to a question, then the retrieval module finds additional relevant information. The model can then refine its answer by incorporating this new information through an iterative feedback process.
The goal is to teach the AI system how to effectively use retrieval to improve its understanding and ability to answer questions. This is different from traditional approaches that rely solely on the language model's own knowledge. By integrating retrieval, RA-ISF allows the model to access a wider range of information and continuously enhance its responses.
Technical Explanation
RA-ISF builds on the Retrieval Augmented Generation (RAG) framework, which combines a language model with a retrieval module. However, RA-ISF introduces a key innovation - the ability to iterate the retrieval and generation process multiple times.
Specifically, RA-ISF first generates an initial response using the language model. It then retrieves relevant information from a knowledge base and incorporates that into the response. The model then repeats this process, using the updated response to guide further retrieval and refinement. This iterative self-feedback loop allows the model to continuously improve its understanding and answering of the question.
The authors evaluate RA-ISF on several question answering benchmarks, including HotpotQA and Natural Questions. They find that RA-ISF outperforms standard language models as well as other retrieval-augmented approaches, demonstrating the benefits of the iterative self-feedback mechanism.
Critical Analysis
The authors acknowledge several limitations of RA-ISF. First, the iterative retrieval and refinement process can be computationally expensive, which may limit its real-world applicability. Additionally, the performance gains of RA-ISF are largely dependent on the quality and coverage of the underlying knowledge base.
The authors also note that RA-ISF may struggle with open-ended or subjective questions that require reasoning beyond simple information retrieval. Further research would be needed to address these limitations and explore ways to make RA-ISF more efficient and versatile.
Conclusion
RA-ISF represents a promising step towards building AI systems that can effectively leverage retrieval to improve their understanding and answering of questions. By iteratively refining their responses through a self-feedback loop, these models can continuously enhance their knowledge and capabilities.
While RA-ISF has some limitations, the core idea of integrating retrieval into the learning process is a valuable contribution that could inspire further advancements in the field of question answering and language understanding. As research in this area continues, we may see even more sophisticated and powerful AI assistants emerge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation
Shicheng Xu, Liang Pang, Mo Yu, Fandong Meng, Huawei Shen, Xueqi Cheng, Jie Zhou
0
0
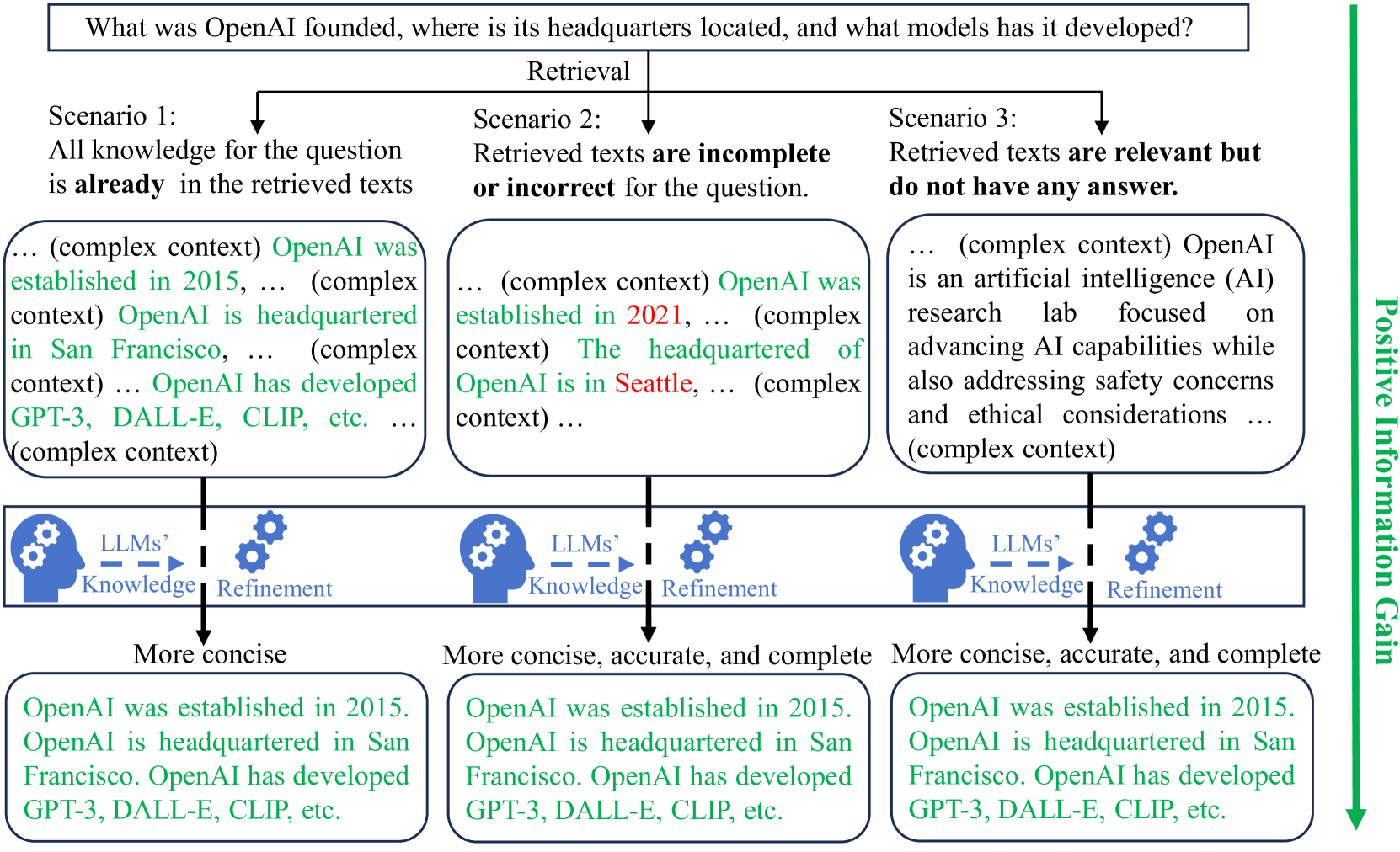
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating additional information from retrieval. However, studies have shown that LLMs still face challenges in effectively using the retrieved information, even ignoring it or being misled by it. The key reason is that the training of LLMs does not clearly make LLMs learn how to utilize input retrieved texts with varied quality. In this paper, we propose a novel perspective that considers the role of LLMs in RAG as ``Information Refiner'', which means that regardless of correctness, completeness, or usefulness of retrieved texts, LLMs can consistently integrate knowledge within the retrieved texts and model parameters to generate the texts that are more concise, accurate, and complete than the retrieved texts. To this end, we propose an information refinement training method named InFO-RAG that optimizes LLMs for RAG in an unsupervised manner. InFO-RAG is low-cost and general across various tasks. Extensive experiments on zero-shot prediction of 11 datasets in diverse tasks including Question Answering, Slot-Filling, Language Modeling, Dialogue, and Code Generation show that InFO-RAG improves the performance of LLaMA2 by an average of 9.39% relative points. InFO-RAG also shows advantages in in-context learning and robustness of RAG.
6/13/2024

R^2AG: Incorporating Retrieval Information into Retrieval Augmented Generation
Fuda Ye, Shuangyin Li, Yongqi Zhang, Lei Chen
0
0
Retrieval augmented generation (RAG) has been applied in many scenarios to augment large language models (LLMs) with external documents provided by retrievers. However, a semantic gap exists between LLMs and retrievers due to differences in their training objectives and architectures. This misalignment forces LLMs to passively accept the documents provided by the retrievers, leading to incomprehension in the generation process, where the LLMs are burdened with the task of distinguishing these documents using their inherent knowledge. This paper proposes R$^2$AG, a novel enhanced RAG framework to fill this gap by incorporating Retrieval information into Retrieval Augmented Generation. Specifically, R$^2$AG utilizes the nuanced features from the retrievers and employs a R$^2$-Former to capture retrieval information. Then, a retrieval-aware prompting strategy is designed to integrate retrieval information into LLMs' generation. Notably, R$^2$AG suits low-source scenarios where LLMs and retrievers are frozen. Extensive experiments across five datasets validate the effectiveness, robustness, and efficiency of R$^2$AG. Our analysis reveals that retrieval information serves as an anchor to aid LLMs in the generation process, thereby filling the semantic gap.
6/21/2024
🛸
IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
Diji Yang, Jinmeng Rao, Kezhen Chen, Xiaoyuan Guo, Yawen Zhang, Jie Yang, Yi Zhang
0
0
Although the Retrieval-Augmented Generation (RAG) paradigms can use external knowledge to enhance and ground the outputs of Large Language Models (LLMs) to mitigate generative hallucinations and static knowledge base problems, they still suffer from limited flexibility in adopting Information Retrieval (IR) systems with varying capabilities, constrained interpretability during the multi-round retrieval process, and a lack of end-to-end optimization. To address these challenges, we propose a novel LLM-centric approach, IM-RAG, that integrates IR systems with LLMs to support multi-round RAG through learning Inner Monologues (IM, i.e., the human inner voice that narrates one's thoughts). During the IM process, the LLM serves as the core reasoning model (i.e., Reasoner) to either propose queries to collect more information via the Retriever or to provide a final answer based on the conversational context. We also introduce a Refiner that improves the outputs from the Retriever, effectively bridging the gap between the Reasoner and IR modules with varying capabilities and fostering multi-round communications. The entire IM process is optimized via Reinforcement Learning (RL) where a Progress Tracker is incorporated to provide mid-step rewards, and the answer prediction is further separately optimized via Supervised Fine-Tuning (SFT). We conduct extensive experiments with the HotPotQA dataset, a popular benchmark for retrieval-based, multi-step question-answering. The results show that our approach achieves state-of-the-art (SOTA) performance while providing high flexibility in integrating IR modules as well as strong interpretability exhibited in the learned inner monologues.
5/24/2024
🧪
A Multi-Source Retrieval Question Answering Framework Based on RAG
Ridong Wu, Shuhong Chen, Xiangbiao Su, Yuankai Zhu, Yifei Liao, Jianming Wu
0
0
With the rapid development of large-scale language models, Retrieval-Augmented Generation (RAG) has been widely adopted. However, existing RAG paradigms are inevitably influenced by erroneous retrieval information, thereby reducing the reliability and correctness of generated results. Therefore, to improve the relevance of retrieval information, this study proposes a method that replaces traditional retrievers with GPT-3.5, leveraging its vast corpus knowledge to generate retrieval information. We also propose a web retrieval based method to implement fine-grained knowledge retrieval, Utilizing the powerful reasoning capability of GPT-3.5 to realize semantic partitioning of problem.In order to mitigate the illusion of GPT retrieval and reduce noise in Web retrieval,we proposes a multi-source retrieval framework, named MSRAG, which combines GPT retrieval with web retrieval. Experiments on multiple knowledge-intensive QA datasets demonstrate that the proposed framework in this study performs better than existing RAG framework in enhancing the overall efficiency and accuracy of QA systems.
5/30/2024