RAGAR, Your Falsehood RADAR: RAG-Augmented Reasoning for Political Fact-Checking using Multimodal Large Language Models

0

Sign in to get full access
Overview
- This paper presents a system called RAGAR (RAG-Augmented Reasoning) for political fact-checking using multimodal large language models.
- The key idea is to leverage the Retrieval-Augmented Generation (RAG) framework to enhance the reasoning capabilities of language models for analyzing claims and detecting falsehoods.
- The system integrates both textual and visual information to provide more comprehensive fact-checking, addressing the challenges of misinformation that can span multiple modalities.
Plain English Explanation
RAGAR is a tool that helps detect false or misleading information, especially in the political realm. It works by combining the power of large language models, which are AI systems trained on massive amounts of text data, with a technique called Retrieval-Augmented Generation (RAG). The RAG framework has been used to improve question-answering models and generate more coherent and informative text.
In the case of RAGAR, the RAG approach is used to enhance the language model's ability to reason about claims and determine whether they are true or false. The system can analyze not just the text of a claim, but also any accompanying images or other visual information. This multimodal approach is important because misinformation can often involve a mix of text and visuals.
By bringing together the language understanding capabilities of large models with the additional context provided by related information, RAGAR aims to be a more reliable and comprehensive tool for fact-checking, helping to combat the spread of false or misleading content.
Technical Explanation
The core of RAGAR is a multimodal large language model that is trained to perform political fact-checking. The system leverages the RAG framework, which integrates a retrieval component to augment the language model's reasoning process.
Specifically, the RAGAR model takes in a claim (e.g., a political statement) along with any accompanying visual information, such as images or diagrams. It then retrieves relevant background information from a knowledge base using the RAG retriever. This additional context is combined with the original input and fed into the language model, which then generates an analysis of the claim's truthfulness.
The authors evaluate RAGAR on a dataset of political claims, comparing its performance to both human fact-checkers and previous language model-based approaches. Their results demonstrate that the RAG-augmented reasoning leads to significant improvements in fact-checking accuracy, especially for more complex or ambiguous claims.
The authors also introduce several advanced RAG-based models, including CONFLARE, to further enhance the retrieval and reasoning capabilities of the system.
Critical Analysis
One potential limitation of the RAGAR system is that it relies on a fixed knowledge base for retrieving background information. In the real world, misinformation can emerge rapidly, and the system may struggle to keep up with the latest developments. The authors acknowledge this challenge and suggest the need for incremental retrieval and update mechanisms to address it.
Additionally, the system's performance may be influenced by the quality and biases present in the training data and knowledge base. Careful curation and validation of these resources will be crucial to ensuring the system's fairness and reliability.
Overall, the RAGAR approach represents a promising step forward in leveraging multimodal large language models for high-stakes tasks like political fact-checking. Its ability to integrate textual and visual information is a valuable asset, but ongoing research will be needed to address the challenges of real-world deployment and ensure the system's robustness and trustworthiness.
Conclusion
The RAGAR system demonstrates how the Retrieval-Augmented Generation (RAG) framework can be used to enhance the reasoning capabilities of large language models for the critical task of political fact-checking. By integrating textual and visual information, the system aims to provide more comprehensive and reliable analysis of claims, helping to combat the spread of misinformation.
While the initial results are promising, the authors acknowledge the need for further research to address the dynamic nature of online misinformation and ensure the system's fairness and robustness. Continued advancements in areas like incremental retrieval and multimodal reasoning will be key to unlocking the full potential of RAGAR and similar fact-checking systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RAGAR, Your Falsehood RADAR: RAG-Augmented Reasoning for Political Fact-Checking using Multimodal Large Language Models
M. Abdul Khaliq, P. Chang, M. Ma, B. Pflugfelder, F. Mileti'c
The escalating challenge of misinformation, particularly in political discourse, requires advanced fact-checking solutions; this is even clearer in the more complex scenario of multimodal claims. We tackle this issue using a multimodal large language model in conjunction with retrieval-augmented generation (RAG), and introduce two novel reasoning techniques: Chain of RAG (CoRAG) and Tree of RAG (ToRAG). They fact-check multimodal claims by extracting both textual and image content, retrieving external information, and reasoning subsequent questions to be answered based on prior evidence. We achieve a weighted F1-score of 0.85, surpassing a baseline reasoning technique by 0.14 points. Human evaluation confirms that the vast majority of our generated fact-check explanations contain all information from gold standard data.
Read more7/15/2024

0
Retrieval Meets Reasoning: Even High-school Textbook Knowledge Benefits Multimodal Reasoning
Cheng Tan, Jingxuan Wei, Linzhuang Sun, Zhangyang Gao, Siyuan Li, Bihui Yu, Ruifeng Guo, Stan Z. Li
Large language models equipped with retrieval-augmented generation (RAG) represent a burgeoning field aimed at enhancing answering capabilities by leveraging external knowledge bases. Although the application of RAG with language-only models has been extensively explored, its adaptation into multimodal vision-language models remains nascent. Going beyond mere answer generation, the primary goal of multimodal RAG is to cultivate the models' ability to reason in response to relevant queries. To this end, we introduce a novel multimodal RAG framework named RMR (Retrieval Meets Reasoning). The RMR framework employs a bi-modal retrieval module to identify the most relevant question-answer pairs, which then serve as scaffolds for the multimodal reasoning process. This training-free approach not only encourages the model to engage deeply with the reasoning processes inherent in the retrieved content but also facilitates the generation of answers that are precise and richly interpretable. Surprisingly, utilizing solely the ScienceQA dataset, collected from elementary and high school science curricula, RMR significantly boosts the performance of various vision-language models across a spectrum of benchmark datasets, including A-OKVQA, MMBench, and SEED. These outcomes highlight the substantial potential of our multimodal retrieval and reasoning mechanism to improve the reasoning capabilities of vision-language models.
Read more6/3/2024
💬
0
RadioRAG: Factual Large Language Models for Enhanced Diagnostics in Radiology Using Dynamic Retrieval Augmented Generation
Soroosh Tayebi Arasteh, Mahshad Lotfinia, Keno Bressem, Robert Siepmann, Dyke Ferber, Christiane Kuhl, Jakob Nikolas Kather, Sven Nebelung, Daniel Truhn
Large language models (LLMs) have advanced the field of artificial intelligence (AI) in medicine. However LLMs often generate outdated or inaccurate information based on static training datasets. Retrieval augmented generation (RAG) mitigates this by integrating outside data sources. While previous RAG systems used pre-assembled, fixed databases with limited flexibility, we have developed Radiology RAG (RadioRAG) as an end-to-end framework that retrieves data from authoritative radiologic online sources in real-time. RadioRAG is evaluated using a dedicated radiologic question-and-answer dataset (RadioQA). We evaluate the diagnostic accuracy of various LLMs when answering radiology-specific questions with and without access to additional online information via RAG. Using 80 questions from RSNA Case Collection across radiologic subspecialties and 24 additional expert-curated questions, for which the correct gold-standard answers were available, LLMs (GPT-3.5-turbo, GPT-4, Mistral-7B, Mixtral-8x7B, and Llama3 [8B and 70B]) were prompted with and without RadioRAG. RadioRAG retrieved context-specific information from www.radiopaedia.org in real-time and incorporated them into its reply. RadioRAG consistently improved diagnostic accuracy across all LLMs, with relative improvements ranging from 2% to 54%. It matched or exceeded question answering without RAG across radiologic subspecialties, particularly in breast imaging and emergency radiology. However, degree of improvement varied among models; GPT-3.5-turbo and Mixtral-8x7B-instruct-v0.1 saw notable gains, while Mistral-7B-instruct-v0.2 showed no improvement, highlighting variability in its effectiveness. LLMs benefit when provided access to domain-specific data beyond their training data. For radiology, RadioRAG establishes a robust framework that substantially improves diagnostic accuracy and factuality in radiological question answering.
Read more7/23/2024
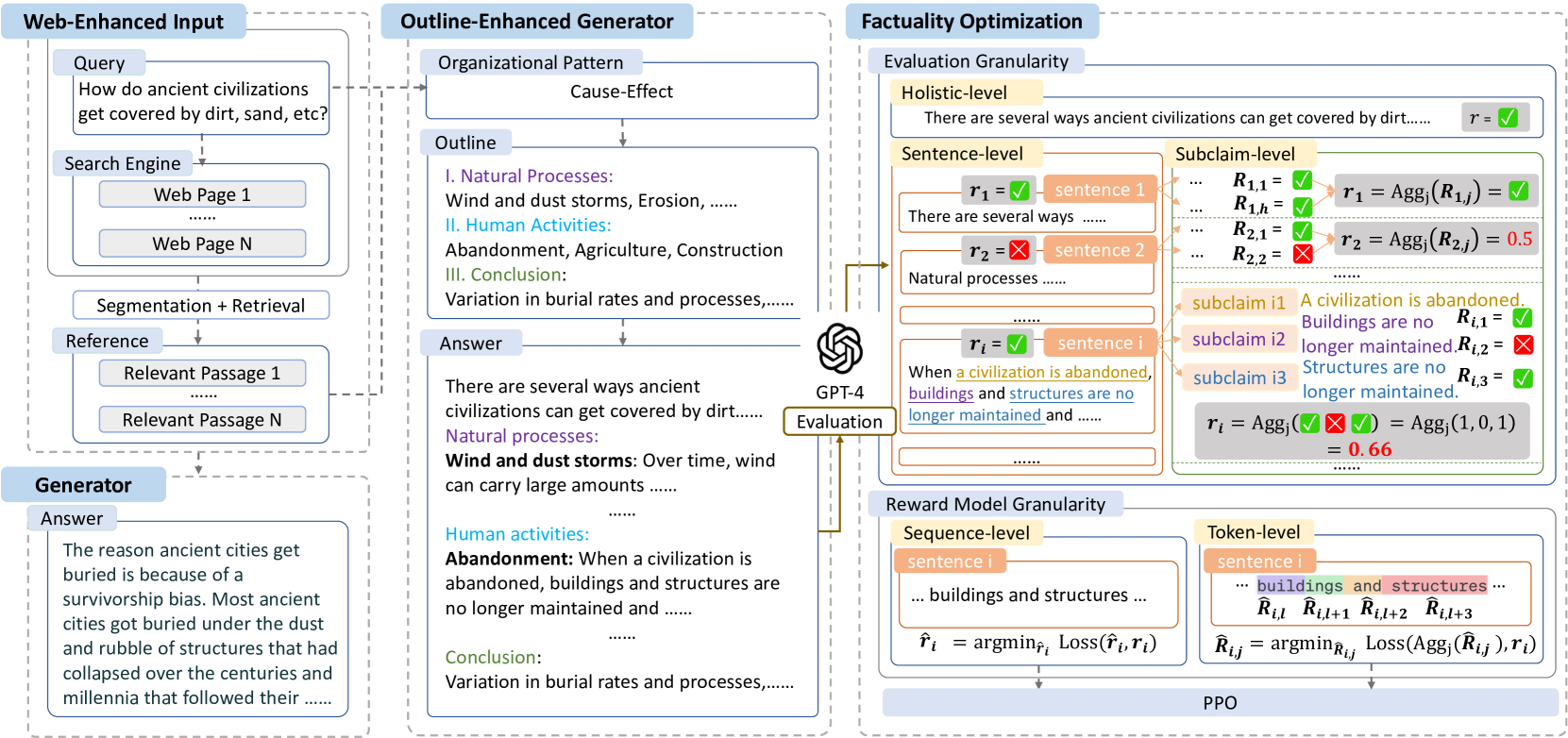
0
FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
Tianchi Cai, Zhiwen Tan, Xierui Song, Tao Sun, Jiyan Jiang, Yunqi Xu, Yinger Zhang, Jinjie Gu
Retrieval Augmented Generation (RAG) has become prevalent in question-answering (QA) tasks due to its ability of utilizing search engine to enhance the quality of long-form question-answering (LFQA). Despite the emergence of various open source methods and web-enhanced commercial systems such as Bing Chat, two critical problems remain unsolved, i.e., the lack of factuality and clear logic in the generated long-form answers. In this paper, we remedy these issues via a systematic study on answer generation in web-enhanced LFQA. Specifically, we first propose a novel outline-enhanced generator to achieve clear logic in the generation of multifaceted answers and construct two datasets accordingly. Then we propose a factuality optimization method based on a carefully designed doubly fine-grained RLHF framework, which contains automatic evaluation and reward modeling in different levels of granularity. Our generic framework comprises conventional fine-grained RLHF methods as special cases. Extensive experiments verify the superiority of our proposed textit{Factuality-optimized RAG (FoRAG)} method on both English and Chinese benchmarks. In particular, when applying our method to Llama2-7B-chat, the derived model FoRAG-L-7B outperforms WebGPT-175B in terms of three commonly used metrics (i.e., coherence, helpfulness, and factuality), while the number of parameters is much smaller (only 1/24 of that of WebGPT-175B). Our datasets and models are made publicly available for better reproducibility: https://huggingface.co/forag.
Read more6/21/2024